





この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第112回)は、AIに同じ質問すると毎回微妙に違う返答になる謎を解き明かした研究や、バイトダンスが開発した文字・画像・音声から話す人物動画を生成できるAIモデル「HuMo」を取り上げます。
また、研究用ソフトウェアを自動生成するGoolge開発のAIや、家庭でもロボットAIを学習できる効率的なロボット制御モデル「VLA-Adapter」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、巨大なデータセンターに依存せず、世界中に散らばる個人PCが協力してAIを学習する分散型アプローチ「SAPO」を別に単体記事で取り上げています。

研究用ソフトウェアを自動生成するAIをGoogleが開発。人間が作るモデルより高性能
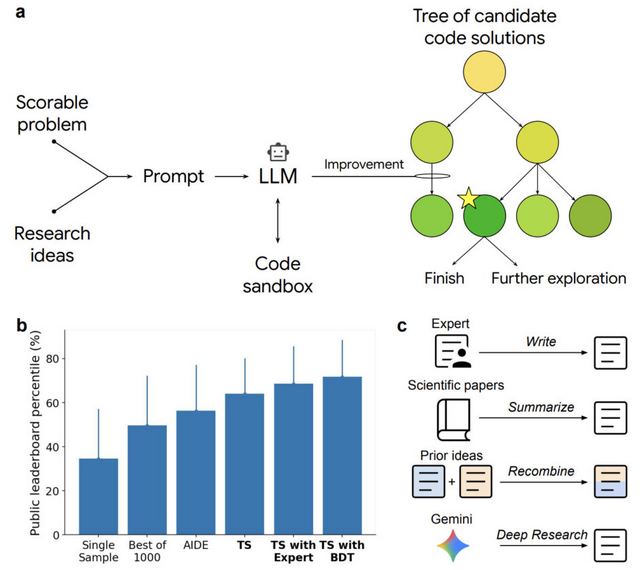
Googleの研究チームが、科学研究用のソフトウェアを専門家レベルで自動生成するAIシステムを開発しました。このシステムは大規模言語モデル(LLM)と木探索アルゴリズムを組み合わせ、品質スコアを最大化するようにコードを体系的に改良していきます。
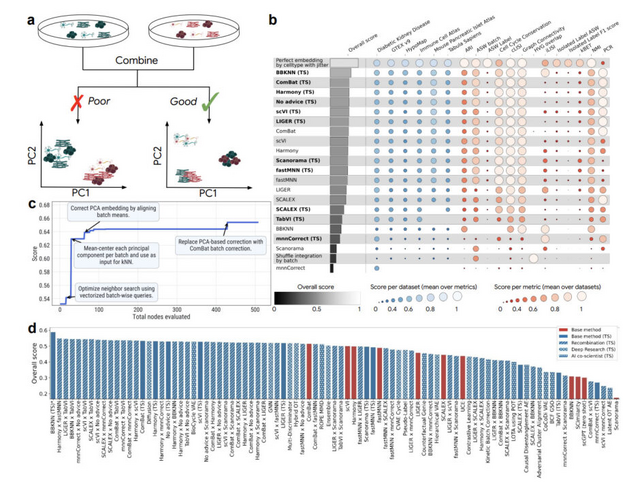
研究チームは6つの異なる科学分野でシステムを評価しました。単細胞RNA配列解析のバッチ効果除去では、既存の最高手法を上回る40の新しい手法を発見しました。米国CDCのCOVID-19入院者数予測コンペティションでは、専門家チームのアンサンブルモデルを超える14のモデルを生成しました。
システムの特徴は、科学文献から研究アイデアを統合し、複数の手法を組み合わせて新しいアプローチを生み出す能力にあります。例えば、異なる手法の長所を組み合わせたハイブリッド戦略や、Deep Researchツールを使って生成された新規アイデアの実装などが可能です。
その他、衛星画像の土地被覆分類では最新の学術論文の成果を20%以上改善し、ゼブラフィッシュ全脳の神経活動予測では既存のビデオベース手法を上回る性能を達成しました。時系列予測や数値積分などの課題でも最先端の結果を示しています。
An AI system to help scientists write expert-level empirical software
Eser Aygün, Anastasiya Belyaeva, Gheorghe Comanici, Marc Coram, Hao Cui, Jake Garrison, Renee Johnston Anton Kast, Cory Y. McLean, Peter Norgaard, Zahra Shamsi, David Smalling, James Thompson, Subhashini Venugopalan, Brian P. Williams, Chujun He, Sarah Martinson, Martyna Plomecka, Lai Wei, Yuchen Zhou, Qian-Ze Zhu, Matthew Abraham, Erica Brand, Anna Bulanova, Jeffrey A. Cardille, Chris Co, Scott Ellsworth, Grace Joseph, Malcolm Kane, Ryan Krueger, Johan Kartiwa, Dan Liebling, Jan-Matthis Lueckmann, Paul Raccuglia, Xuefei (Julie)Wang, Katherine Chou, James Manyika, Yossi Matias, John C. Platt, Lizzie Dorfman, Shibl Mourad, Michael P. Brenner
Paper
文字・画像・音声から話す人物動画を生成できるAIモデル「HuMo」をバイトダンスが開発
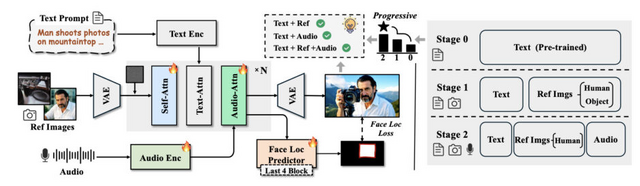
ByteDanceや清華大学などの研究チームが、テキスト、参照画像、音声の3つの入力を同時に制御して人間中心の動画を生成するフレームワーク「HuMo」を発表しました。
従来手法では、参照画像を重視すると音声同期が劣化し、音声同期を優先するとテキスト追従性や被写体保持が損なわれるというトレードオフが存在していました。HuMoはこの問題を解決するため、高品質なマルチモーダルデータセットの構築と、段階的な学習を提案しています。
技術的には、第1段階で参照画像による被写体保持を学習し、第2段階で音声視覚同期を段階的に導入することで、各能力を損なわずに統合しています。
実験は1.7Bパラメータと17Bパラメータの2つのモデルサイズで実施され、HuMoは被写体保持と音声視覚同期の両タスクにおいて既存の専門手法を上回る性能を示しました。特に17Bパラメータモデルは、テキスト追従性、被写体一貫性、音声視覚同期などの主要な評価指標で優れた結果を達成しています。



HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
Liyang Chen, Tianxiang Ma, Jiawei Liu, Bingchuan Li, Zhuowei Chen, Lijie Liu, Xu He, Gen Li, Qian He, Zhiyong Wu
Project | Paper | GitHub
家庭でもロボットAIを学習できる、効率的なロボット制御モデル「VLA-Adapter」
中国の研究チームが、ロボット制御のための視覚言語行動モデル「VLA-Adapter」を開発しました。このような「Vision-Language-Action」(VLA)の研究は主に、マルチモーダル情報を抽出し、それをもとに高品質な行動を生成することに焦点を当てています。
従来のVLAモデルは、70億パラメータ規模のモデルを訓練するには、複数の高価なGPUと長時間の計算が必要で、研究機関や大企業が持つような高性能な計算環境が必要でした。
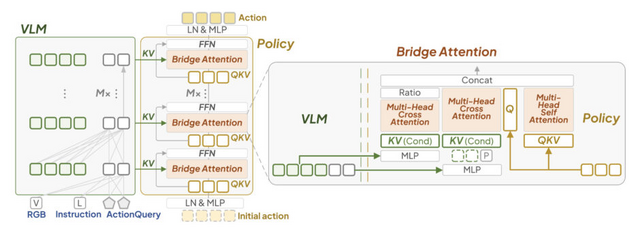
VLA-Adapterは、視覚言語表現から行動への効果的な橋渡し方法を発見し、わずか0.5億パラメータのモデルで70億パラメータの既存手法と同等の性能を実現しています。
具体的には、「Bridge Attention」と呼ばれる新しい機構により、VLMの各層から抽出される特徴量と学習可能なトークンを効果的に組み合わせることで、視覚と言語の情報を効率的に行動へと変換します。
これにより、メモリ使用量を62GBから24.7GBに削減し、家庭用GPU1台で8時間の学習を可能にしました。LIBEROベンチマークで97.3%の成功率を達成し、推論速度を従来の3倍の219.2Hzに向上させました。
実世界実験では、6自由度ロボットアームによる物体操作タスクで優れた汎化性能を示しました。この技術により、高価な計算資源なしでも高性能なロボット制御システムの開発が可能となり、VLAモデルの実用化への障壁が大きく下がることが期待されます。

VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
Yihao Wang, Pengxiang Ding, Lingxiao Li, Can Cui, Zirui Ge, Xinyang Tong, Wenxuan Song, Han Zhao, Wei Zhao, Pengxu Hou, Siteng Huang, Yifan Tang, Wenhui Wang, Ru Zhang, Jianyi Liu, Donglin Wang
Project | Paper
「AIに同じ質問すると毎回微妙に違う返答になる謎」、元OpenAIチームが意外な原因を突き止める。毎回同じ答えになる新システムも開発
大規模言語モデル(LLM)に同じ質問をしても、毎回微妙に違う答えが返ってくることがあります。これまで、この問題はコンピュータが並列処理をする際の計算順序のばらつきが原因だと考えられていました。
しかし、元OpenAIの前CTOミラ・ムラティが立ち上げたAIチーム「Thinking Machines Lab」は、間違ってはいないが説明が十分ではないとして、根本的な原因を報告しました。
それは、LLMサーバーが複数のユーザーからの質問を同時に処理する際、その「同時処理する数」によって、一つ一つの答えの計算結果が微妙に変わってしまうというものです。
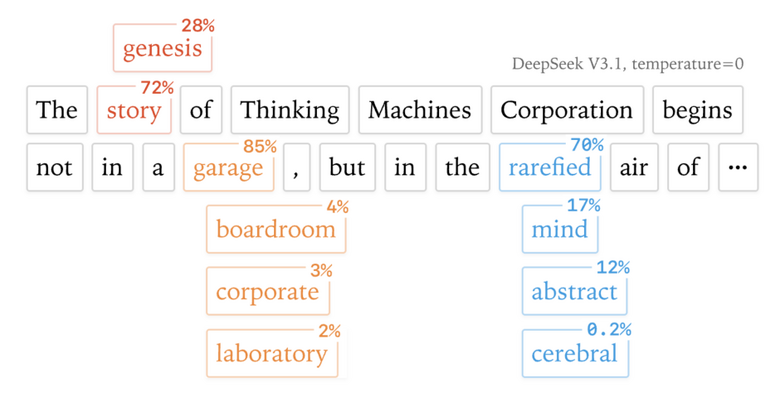
LLMサーバーは複数ユーザーの要求を同時処理しますが、その時々の混雑度でバッチサイズが変動します。10人が同時に質問している時と1000人が同時に質問している時では、場合により計算戦略が変わり、GPUの浮動小数点演算の丸め誤差により個々の結果がわずかに異なります。この微小な差がトークンの確率計算に影響し、最終的に異なる文章が生成されます。
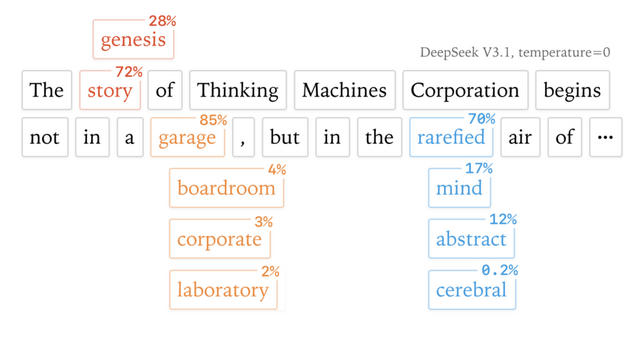
実際の実験では、「リチャード・ファインマンについて教えて」という同じ質問を1000回繰り返したところ、80種類もの異なる回答が生成されました。最初の102番目トークンは同じでしたが、103番目で「Queens, New York」と書くか「New York City」と書くかで分かれ始めたのです。
研究チームは、どんな状況でも同じ順序で計算を行うように改良した新しい計算方法を開発しました。この方法を使うと、1000回質問しても1000回とも完全に同じ答えが返ってきます。処理速度は少し遅くなりますが(26秒が42秒になる程度)、重要な局面でAIを使用する際には重宝すると思われます。
Defeating Nondeterminism in LLM Inference
Thinking Machines Lab
Blog