1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、脳に電極を埋め込まないで脳活動から直接文章を文字に起こす非侵襲AI技術を提案した、オックスフォード大学の研究者らによる論文「Unlocking Non-Invasive Brain-to-Text」を取り上げます。
これまでの脳波からテキストに変換する技術「Brain-to-Text」(B2T)は、脳に電極を埋め込む侵襲的方法が主流であり高い精度を示していたが、脳感染や出血などのリスクを伴うという課題がありました。
非侵襲的方法としては頭皮上の電極を用いるEEG(脳電図)やMEG(脳磁図)がありますが、これまでの研究ではランダム予測を超える性能を実証できていませんでした。
MEGは頭部の外側に配置された高感度のセンサーを使用して、神経活動によって生じる微弱な磁場を非侵襲的に測定する装置。EEGが頭蓋骨などの影響を受けやすいのに対し、MEGはこれらの影響をあまり受けないという特性があります。
この研究でもMEGを使用した非侵襲的手法を採用し、主に3つの工夫を導入しました。
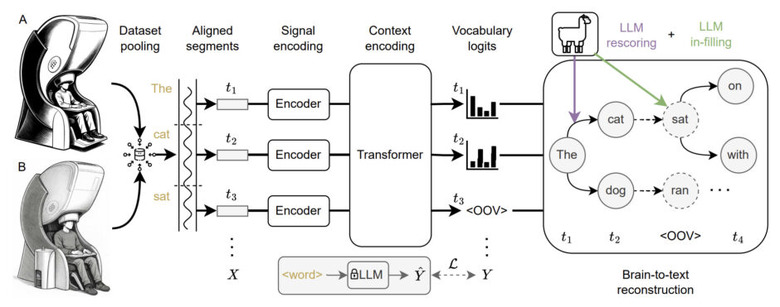
1つ目は大規模言語モデル(LLM)を活用して、予測された単語の並びが、どれだけ文脈に合っているかを評価する仕組みです。これまでのシステムは、単語を一つずつ予測する能力はあっても、それらを自然な文章としてつなげるのが苦手でした。研究チームは予測された単語の並びが、どれだけ自然な文章に近いかをLLMを使って評価し、最も適切な文章を選び出す方法を導入しました。
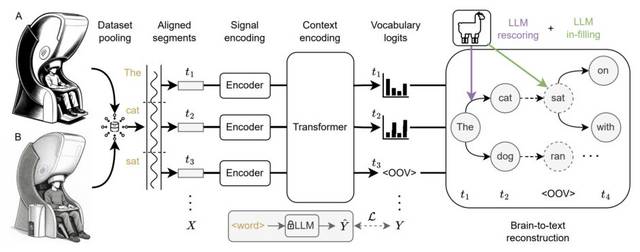
▲提案手法の概要図
2つ目は知らない単語で文脈を補うことです。脳波から単語を予測するモデルは、あらかじめ決められた限られた語彙しか扱えません。語彙を増やそうとすると、かえって予測精度が落ちるという問題がありました。この課題を解決するため、研究チームはモデルが「知らない単語」(語彙外)を検出する仕組みを開発し、その部分をLLMが文脈に合わせて適切な単語で埋めるようにしました。
3つ目は複数の異なる脳波データを組み合わせる手法の導入です。脳波データは、測定機器や参加者の違い、実験方法などによって大きく異なり、複数のデータセットを単純に組み合わせても、なかなか性能が向上しませんでした。研究チームは、個々のデータセットが単独でどれだけ良い性能を出すかを基準に、質の高いデータセットを選んで組み合わせることで、この課題を克服しました。この方法により、単語分類の精度を2倍以上に高めることができました。
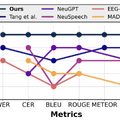
これらの技術を駆使した結果、テキスト変換の標準的評価指標であるBLEUスコアを従来研究と比較して最大2.6倍向上させました。また、全ての評価指標においてランダムベースラインを統計的に有意な水準で上回ることに成功しました。
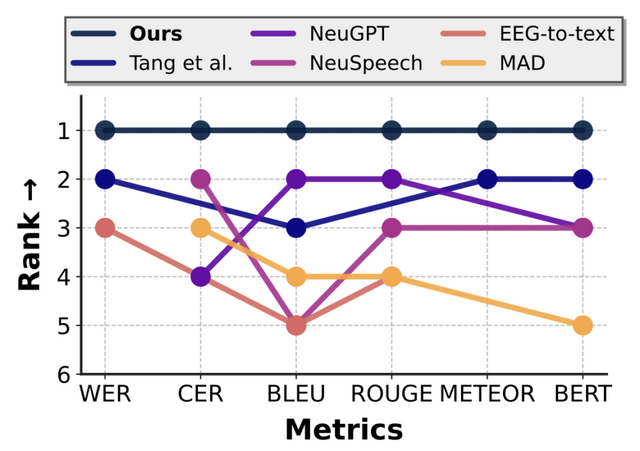
▲提案手法は従来モデルの全てのスコアを上回る