
GoogleのDeepMindは、新しいタンパク質を生成する能力を持つAIシステム「AlphaProteo」を発表しました。AlphaProteoは、標的分子に効果的に結合する新しいタンパク質を設計することができ、創薬、疾病理解、その他の分野での研究を加速させる可能性があります。
Phindは新しいフラッグシップモデル「Phind-405B」と、高速な検索が可能な「Phind Instant」モデルを発表しました。Phind-405BはMeta Llama 3.1 405Bをベースにしており、128Kトークンのコンテキストを処理でき、32Kのコンテキストウィンドウが利用可能です。このモデルはHumanEvalで92%のスコアを達成し、Claude 3.5 Sonnetと同等の性能を示しています。
さて、この1週間の気になる生成AI技術・研究をピックアップして解説する「生成AIウィークリー」(第63回)では、GPT-4oやClaude 3.5 SonnetなどのクローズドLLMと同等以上の性能を謳うオープンソースLLM「Reflection 70B」や、画像生成AI「FLUX」をベースにした音楽生成AI「FluxMusic」を取り上げます。また、動画生成AIでスーパーマリオのプレイ映像を生成する「MarioVGG」や、高品質なリップシンクを生成する「Loopy」をご紹介します。
そして、生成AIウィークリーの中でも、特に興味深い技術や研究にスポットライトを当てる「生成AIクローズアップ」では、マイクロソフト含む大企業のエンジニア4800人以上を対象に、生成AIがどれくらい影響を与えるかを調査した研究を単体で掘り下げます。

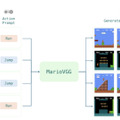
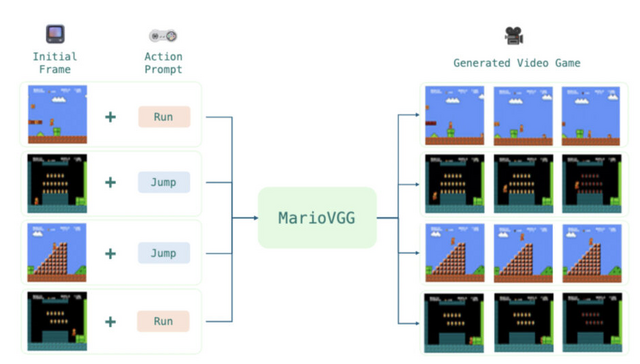
動画生成AIで“スーパーマリオブラザーズ”のプレイ映像を生成する対話型モデル「MarioVGG」
MarioVGGは、動画生成AIを用いてスーパーマリオブラザーズのゲームプレイ映像を自動生成するシステムです。このモデルは、テキストによる指示を入力として受け取り、それに対応するゲーム画面の動画を生成します。
例えば、「ジャンプ」や「走る」といった指示を与えると、マリオがその動作を行う様子を動画として出力します。MarioVGGは単にキャラクターの動きを生成するだけでなく、ゲームの物理法則や環境の一貫性も学習しています。
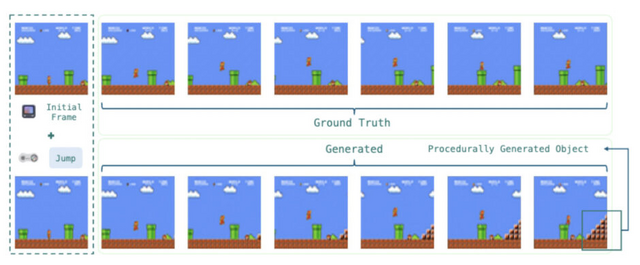
学習には、公開されているスーパーマリオブラザーズのゲームプレイデータセットを使用しており、このデータセットには280の異なるプレイエピソードが含まれています。
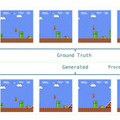
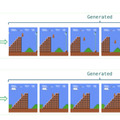
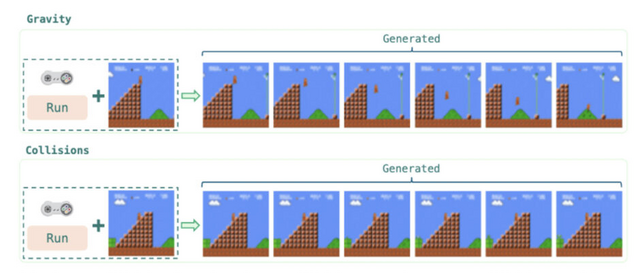
MarioVGGは実際のゲームプレイに近い動画を生成することに成功しました。マリオの動きや背景の生成が自然で、重力や障害物との衝突などのゲームルールも正確に再現されています。
このモデルは、1回の生成で約6フレームの連続した画像を64×48の解像度で生成します。より長い動画シーケンスを作成するために、これらの生成を連続して行います。具体的には、最初の6フレームを生成した後、その最後のフレームを新たな開始点として次の6フレームを生成し、この過程を繰り返すことで長時間のゲームプレイ動画を作成しています。
ただし、現状では1回の生成に約4秒かかるため、リアルタイムのゲームプレイには適していません。今後の課題としては、生成速度の向上や、より多様なアクションの学習が期待されます。

Video Game Generation: A Practical Study using Mario
Virtuals Protocol
Paper
GPT-4oやClaude 3.5 SonnetなどのクローズドLLMを凌駕すると謳うオープンLLM「Reflection 70B」
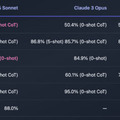
AIベンチャー「OthersideAI」のCEOであるMatt Shumer氏が、Xにおいて、Llama-3.1をベースにしたオープンソースモデル「Reflection 70B」を発表しました。Reflection 70Bは、Claude 3.5 SonnetやGPT-4oなどの最高レベルのクローズドソースモデルと同等以上の性能を持っていると述べています。
少なくともMMLU、MATH、IFEval、GSM8Kといったベンチマークでは、トップの性能を達成しています。テストしたすべてのベンチマークでGPT-4oを上回り、Llama 3.1 405Bを大きく引き離しています。
Reflection 70Bを支える技術は単純ですが、非常に強力です。現在のLLMには幻覚を起こす傾向があり、自身が幻覚を起こしていることを認識できません。このモデルは、「Reflection-Tuning」と呼ばれる技術を用いて訓練されています。Reflection-Tuningは、LLMが自身の間違いを認識し、回答を確定する前に修正することを可能にします。
70Bモデルは、現在Hugging Faceで公開されています。来週には、より強力な「Reflection 405B」の重みがリリースされ、また詳細なレポートが公開される予定です。
ただし、懐疑的な意見も飛び交っており、多様な検証や今後の詳細が待たれています。
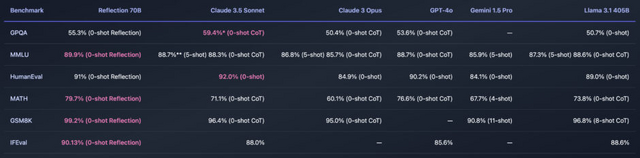
Reflection Llama-3.1 70B
Hugging Face
テキストから音楽を生成するFLUXベースの音楽生成AI「FluxMusic」
先日、元Stable Diffusion開発チームの会社「Black Forest Labs」による画像生成AI「FLUX.1」が話題になりましたが、今回はFLUXをベースにしたテキストから音楽を生成する音楽生成AI「FluxMusic」が開発されました。

FluxMusicの特徴は、音楽のメルスペクトログラム(音の周波数と時間の関係を視覚化したもの)を潜在空間で操作する点にあります。この潜在空間では、音楽の特徴がより抽象的に表現されており、効率的に処理できます。
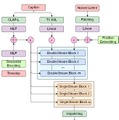
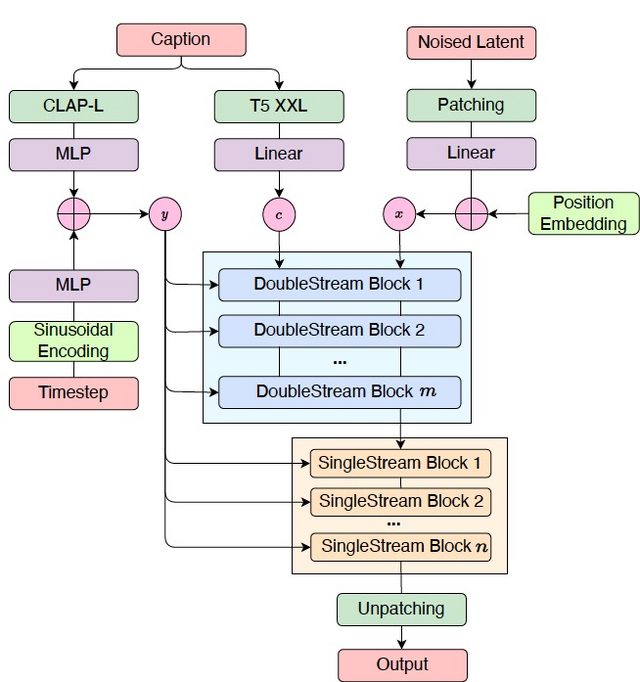
モデルのアーキテクチャは、テキストと音楽の情報を同時に処理する「DoubleStream Block」と、その後音楽の細かい要素を処理する「SingleStream Block」の組み合わせを採用しています。これにより、テキストの意味と音楽の構造の間で効果的な情報交換が可能になり、テキストの影響を受けつつ音楽の細かい要素を調整します。
テキスト処理には、CLAP-LとT5-XXLという2つの事前学習済み言語モデルを使用しています。CLAP-Lは大まかな意味を、T5-XXLは詳細なニュアンスを捉えるのに使われ、これらの情報が音楽生成プロセスの異なる段階で活用されます。
音楽の生成プロセスは、ノイズから始めて徐々に音楽的な構造を形成していく拡散モデルに基づいています。ここで「Rectified Flow」という学習方法を導入することで、従来の拡散モデルよりも効率的な学習と高品質な音楽生成を実現しています。これにより、テキストの内容を音楽の様々な要素(リズム、メロディ、雰囲気など)に効果的に反映させることが可能になります。
評価においては、Fréchet Audio Distance(FAD)やInception Score(IS)といった客観的指標に加え、人間による主観評価も実施されました。特に専門家による評価では、生成された音楽の全体的な質と、テキストの内容との整合性が高く評価されています。
音声に応じて口の動きや表情が生成されるリップシンク動画生成AI「Loopy」をByteDanceが開発
この研究では、音声駆動のポートレートアバター生成における動画生成AI「Loopy」が提案されています。従来の手法では、音声とアバターの動きの相関が弱いため、空間的な条件を追加して動きを安定させる必要がありましたが、これにより自然さと自由度が損なわれる課題がありました。
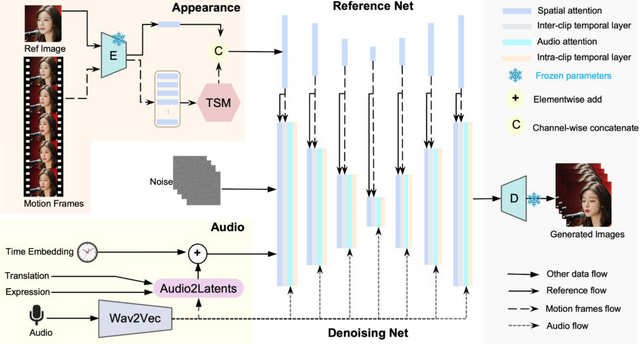
Loopyは、これらの課題を解決するために、長期的な動きの依存関係を活用して自然な動きのパターンをデータから学習する、エンドツーエンドの音声条件付きビデオ拡散モデルを提案しています。具体的には、時間的側面と音声の側面の設計において工夫がされています。
時間的側面では、クリップ間およびクリップ内の時間モジュールなどを導入しています。この設計により、モデルは100フレーム以上(25fpsで約5秒間)の長期的な動きの情報を効果的に捉え、より自然で一貫性のある動きを生成できるようになります。
音声の側面では、音声から潜在表現への変換モジュールを導入しています。このモジュールは、音声データと顔の動きに関連する特徴(顔のランドマーク、頭の動きの変化、表情の変化など)を共通の特徴空間で処理します。これにより、音声とアバターの動きの相関関係をより効果的にモデル化することが可能となります。
実験では、複雑なシナリオや感情表現を含むデータセットなどで評価が行われました。結果として、Loopyは既存の手法と比較して、時間的安定性、動きの多様性、全体的な動画品質、そして音声と動きの同期性において大幅な改善を示しました。また、様々な入力画像(実際の人物、アニメキャラクター、横顔、銅像など)と多様な音声入力(ラップや感情豊かな発話など)に対して高い適応性を示しています。

Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency
Jianwen Jiang, Chao Liang, Jiaqi Yang, Gaojie Lin, Tianyun Zhong, Yanbo Zheng
Project | Paper
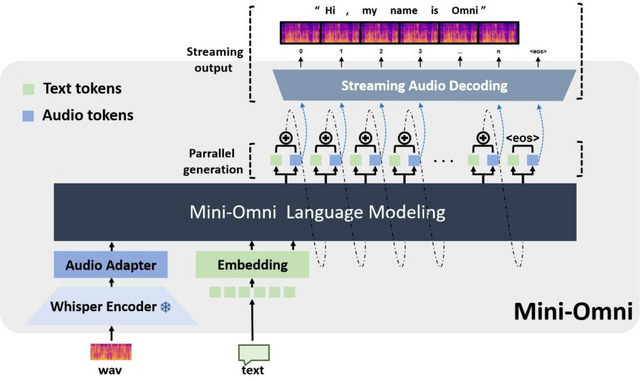
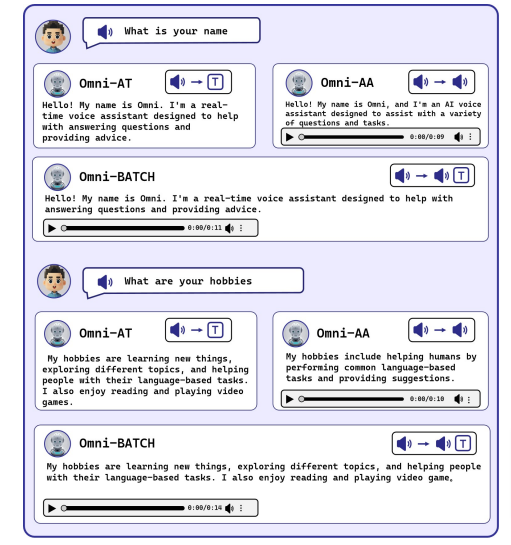
“考えながら聞き、話す” リアルタイムの音声入出力が可能なAIモデル「Mini-Omni」
「Mini-Omni」は、リアルタイムの音声入出力が可能なオープンソースのマルチモーダル大規模言語モデルです。リアルタイムのエンドツーエンドの音声入力とストリーミングオーディオ出力の音声対音声における会話機能を備えています。音声を聞き取り、考え、そして話すという一連の処理をほぼ同時に行えます。
従来の音声対話システムでは、音声を聞き取ってテキストに変換し、そのテキストに対する応答を生成し、最後にその応答を音声に変換するという段階的な処理を行っていました。これに対しMini-Omniは、テキストと音声を並行して処理することで、より自然な対話を実現しています。
このモデルの主な特徴は、テキスト指示による音声生成方式を採用していることです。この方式では、モデルがテキストと音声を同時に生成し、テキストが音声生成の指針として機能します。これにより、言語モデルのテキストベースの高度な推論能力を音声出力に効果的に転用しています。
さらに、バッチ並列デコーディングという手法を導入しています。この手法では、1つの入力に対して2つの処理を並行して行います。1つはテキストと音声の生成、もう1つはより深い推論を行うテキストのみの生成です。後者の結果を音声出力に活用することで、より複雑な推論を音声出力でも可能にしています。
Mini-Omniの学習には3段階のアプローチを採用しています。まず音声認識と合成の能力を獲得し、次に音声入力に対するテキスト応答を学習し、最後に総合的なマルチモーダル対話能力を獲得します。この方法により、元のテキストモデルの能力を最大限保持しつつ、音声対話能力を効率的に追加しています。
研究チームは、この手法を「Any Model Can Talk」と名付け、他の言語モデルにも容易に音声対話能力を追加できるフレームワークとして提案しています。また、音声アシスタント向けの学習データセット「VoiceAssistant-400K」も公開しています。
Mini-Omniは0.5Bパラメータという比較的小規模なモデルながら、高度な音声対話能力を実現しています。