



この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第102回)は、自分が生成した画像を自己評価して修正する画像生成AI「OmniGen2」、プロンプトだけで大規模言語モデル(LLM)を瞬時に微調整相当の専門モデルに作り上げる方法「Drag-and-Drop LLMs」を取り上げます。
また、Black Forest Labsの画像編集に特化したオープンウェイトAI「FLUX.1 Kontext [dev]」と、画像1枚からプレイヤー操作可能なゲームを生成する「Hunyuan-GameCraft」をご紹介します。
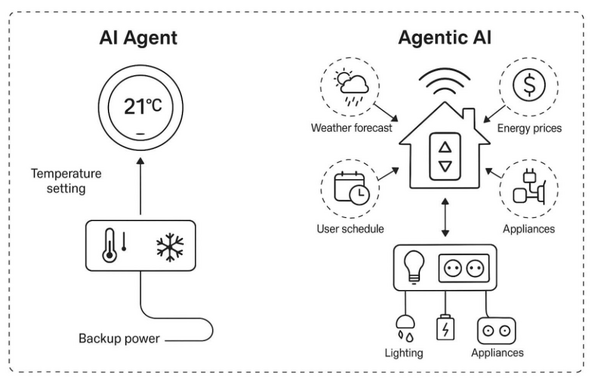
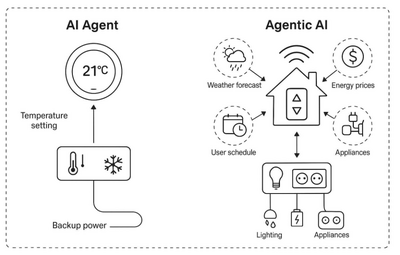
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、「AIエージェント」(AI Agents)と「エージェント型AI」(Agentic AI)の違いを説明した論文を別で単体記事として取り上げています。
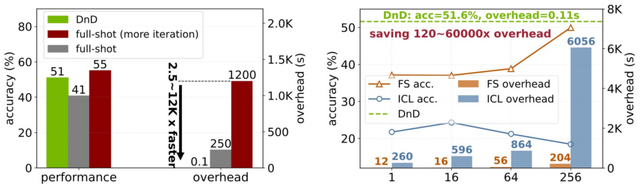
プロンプトだけでLLMを瞬時に特定のタスクに適応できる方法「Drag-and-Drop LLMs」は従来の方法と比べて最大1万2000倍高速
従来、大規模言語モデル(LLM)を企業の特定業務や専門分野に適応させるには、LoRAなどのファインチューニングを用いますが、ある程度の計算資源と時間が必要です。
今回、LLMを特定のタスクに適応させる方法「Drag-and-Drop LLMs」(DnD)が開発されました。DnDはファイルをドラッグ&ドロップするように、このようにしてほしいというタスクのプロンプトをいくつか入力するだけで、そのタスクに特化したモデルパラメータを瞬時に生成します。これによりファインチューニングが一切不要になります。
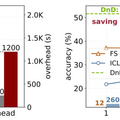
実験では、常識推論、数学、コード生成、マルチモーダルベンチマークにおいて、フルファインチューニングと比べて最大12,000倍も高速化され、しかも性能は未見のデータセットに対し最大30%向上する結果が得られました。
この技術の核心は、モデルのパラメータ(重み)そのものを新しいデータとして扱い、タスクのプロンプトから直接生成するという発想にあります。


Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights
Zhiyuan Liang, Dongwen Tang, Yuhao Zhou, Xuanlei Zhao, Mingjia Shi, Wangbo Zhao, Zekai Li, Peihao Wang, Konstantin Schürholt, Damian Borth, Michael M. Bronstein, Yang You, Zhangyang Wang, Kai Wang
Project | Paper
Black Forest Labsが画像編集に特化したオープンウェイトAI「FLUX.1 Kontext [dev]」発表
高品質な画像生成AIで知られる「Black Forest Labs」が、画像編集に特化したオープンウェイトモデル「FLUX.1 Kontext [dev]」を発表しました。
このモデルの最大の特徴は、複数回の編集を行ってもキャラクターや対象物の一貫性が保たれることです。例えば、同じキャラクターを異なるシーンに配置したり、表情を変更したりしても、その特徴が維持されます。処理速度も優れており、1024×1024ピクセルの画像を3~5秒で生成できます。
主な機能として、画像の一部だけを変更するローカル編集、画像全体の雰囲気を変えるグローバル編集、芸術的スタイルを他の画像に適用するスタイル参照、画像内のテキストを自然に置き換えるテキスト編集などがあります。
技術的には、画像をトークン化してコンテキスト画像と対象画像を連結する簡潔な手法を採用しています。性能評価用に開発されたKontextBenchベンチマークでは、既存の最先端モデルと同等以上の品質を達成しながら、大幅に高速な処理を実現していることが確認されました。






FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Müller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, Luke Smith
Paper | Blog
1枚の画像からプレイヤー操作可能なゲームを生成できるAI「Hunyuan-GameCraft」をテンセントが開発
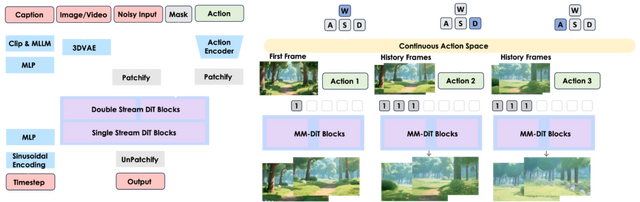
Tencentを中心とした研究チームが、1枚の画像とテキストプロンプトから、プレイヤーの操作に応じてリアルタイムでインタラクティブなゲーム映像を生成できるモデル「Hunyuan-GameCraft」を発表しました。
このモデルは、テキストから動画への基盤モデルである「Hunyuan-Video」をベースに構築されています。
特徴としては、「W, A, S, D」が移動、「↑, ←, ↓, →」が視点変更などのキーボード操作をカメラ表現空間に変換し、滑らかで自然な映像生成を実現している点です。また長時間の映像でも一貫性を保ちながら、過去のシーン情報を効果的に保持します。
蒸留技術の実装により推論速度は最大20倍に向上し、リアルタイム(6.6フレーム/秒)でのインタラクティブな体験が可能になっています。
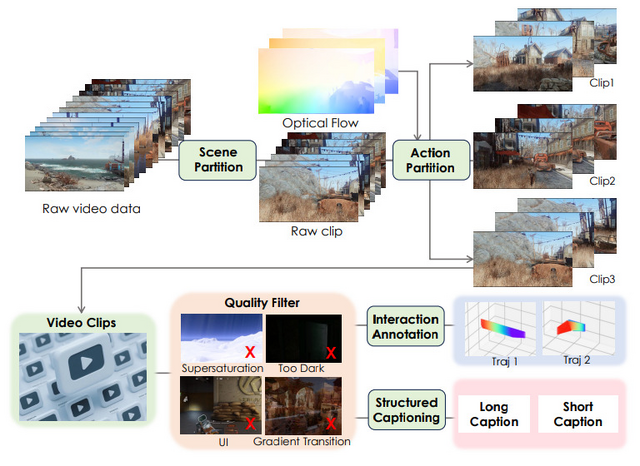
学習データには100以上のAAAタイトルから収集した100万件以上のゲームプレイ録画を使用し、さらに高品質な合成データでファインチューニングを行いました。実験結果では、既存の最先端モデルと比較して、動的性能やインタラクションエラーの削減において大幅な改善を達成しています。



Hunyuan-GameCraft: High-dynamic Interactive Game Video Generation with Hybrid History Condition
Jiaqi Li, Junshu Tang, Zhiyong Xu, Longhuang Wu, Yuan Zhou, Shuai Shao, Tianbao Yu, Zhiguo Cao, Qinglin Lu
Project | Paper
自分が生成した画像を自己評価してミスを修正する画像生成AI「OmniGen2」
北京人工知能研究院(BAAI)が、多様な画像生成タスクを単一モデルで実現するオープンソースモデル「OmniGen2」を発表しました。このモデルは、テキストから画像の生成、画像編集、文脈を考慮した生成など、従来は別々のモデルが必要だった機能を統合しています。
OmniGen2の特徴は、テキストと画像に対して異なる処理経路を採用している点です。画像情報の種類と用途に応じて異なるエンコーダとトランスフォーマーを使い分けることで、テキストの理解能力を損なうことなく、高品質な画像生成を実現しています。
注目すべき機能として「リフレクション」があります。生成した画像を自己評価し、指示に合わない部分を特定して修正する能力を持っています。例えば「黄色いブロッコリー」という指示に対して緑色のブロッコリーを生成した場合、モデル自身がこの誤りを認識し、次の生成で色を修正します。
性能評価では、GenEvalベンチマークで0.86のスコアを達成し、140億パラメータを持つ他のモデル(BAGEL)に匹敵する性能を70億パラメータで実現しました。画像編集タスクでも、オープンソースモデルの中で最高レベルの性能を示しています。




OmniGen2: Exploration to Advanced Multimodal Generation
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, Ze Liu, Ziyi Xia, Chaofan Li, Haoge Deng, Jiahao Wang, Kun Luo, Bo Zhang, Defu Lian, Xinlong Wang, Zhongyuan Wang, Tiejun Huang, Zheng Liu
Paper | GitHub