



1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第42回目は、生成AI最新論文の概要5つを紹介します。
生成AI論文ピックアップ
AIが生成した“誤ったコード”を改善するAIモデル「AutoCodeRover」
大規模言語モデル(LLM)の進歩により、自然言語要件からコードを自動生成することが可能になりつつあります。しかし、LLMにより生成されたコードには誤りや脆弱性が含まれる可能性があるため、自動生成されたコードを自律的に改善していく仕組みが必要とされています。
研究チームは、LLMを活用した自律的コード改善のフレームワーク「AutoCodeRover」を提案しました。AutoCodeRoverは、ファイルの代わりに抽象構文木(AST)などのプログラム表現を利用し、プログラム構造を活用した反復的なコード検索を行います。さらに、テストが利用可能な場合はテストケースを利用してプログラム内の障害箇所を特定する手法を利用することで、自律的なコード修正を可能にしています。
研究チームは、300件の実際のGitHub issueからなるベンチマーク「SWE-bench lite」でAutoCodeRoverを評価しました。その結果、AutoCodeRoverは約22%のissueを解決でき、最近の他の研究と比較して高い有効性を示しました。開発者が平均2. 77日かけて解決したissueの中に、AutoCodeRoverが10分以内で解決できたものが67件ありました。




AutoCodeRover: Autonomous Program Improvement
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, Abhik Roychoudhury
Paper | GitHub
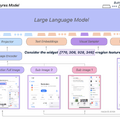
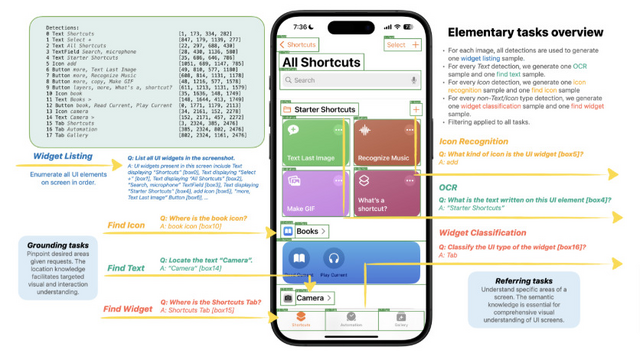
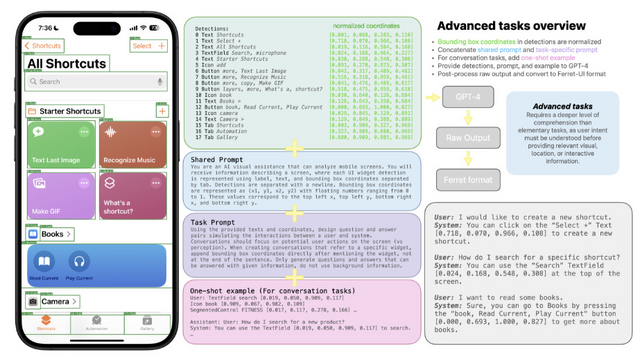
Apple、スマホUIを理解するためのモバイル向けマルチモーダル大規模言語モデル「Ferret-UI」を発表
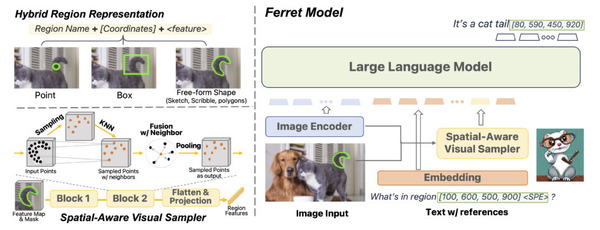
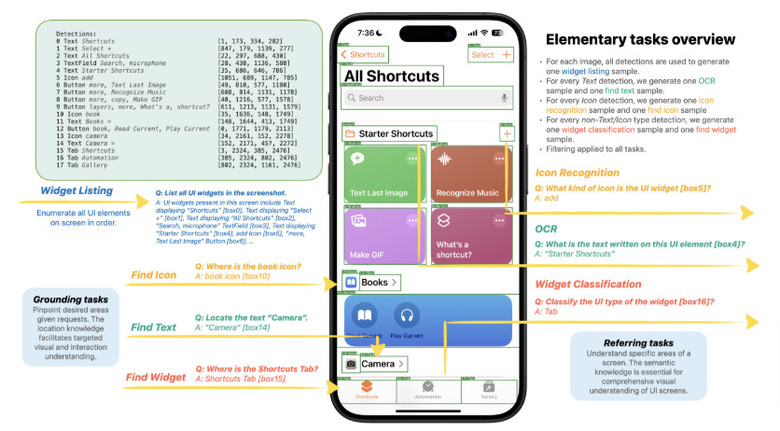
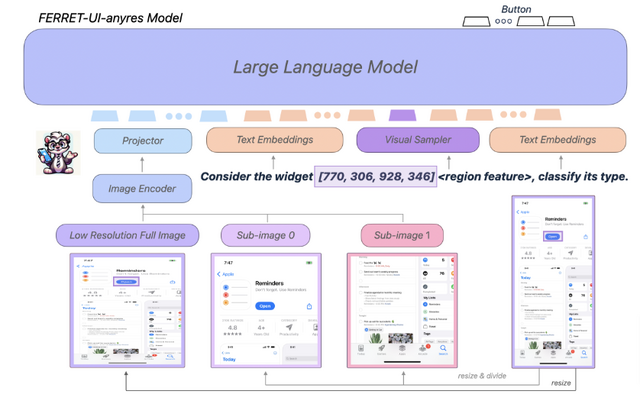
Ferret-UIは、スマホUIに特化したマルチモーダル大規模言語モデル(MLLM)で、Appleの研究者らによって開発されました。Ferret-UIは、同社が2023年10月に発表した画像内を理解するMLLM「Ferret」をベースに開発されました。(ちなみに、最近「Ferret-v2」も公開されています。)
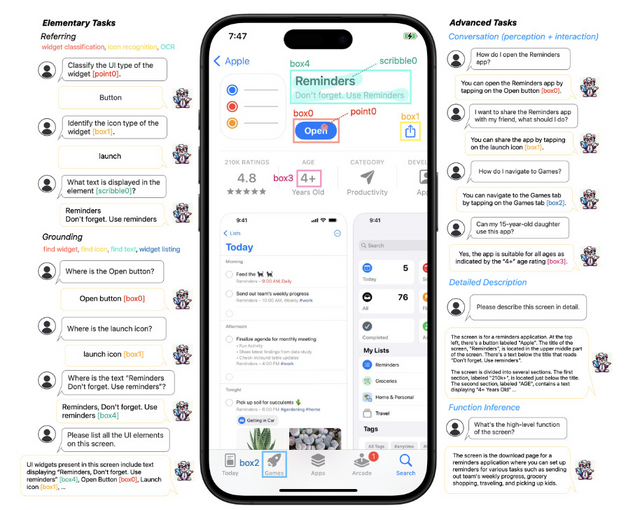
Ferret-UIは、スマホUIの参照、位置特定、推論のタスクを効果的に実行できます。アーキテクチャ面では、様々な画面のアスペクト比に柔軟に対応するために「any resolution」機能を組み込んでいます。また、基本的なUI操作から高度な推論まで多様なタスクのトレーニングデータを用意し、モデルを訓練しました。
Ferret-UIの評価のために、参照と位置特定に関する14のモバイルUIタスクからなるベンチマークを開発しました。各種のモデルと比較した結果、Ferret-UIは基本的なUIタスクで他のモデルを大きく上回り、高度なタスクでも優れたパフォーマンスを示しました。具体的には、iPhoneとAndroidで評価した結果、他のオープンソースMLLMやGPT-4Vと比べ、基本的なUIタスクにおいてFerret-UIは優れたパフォーマンスを示しました。
Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs
Keen You, Haotian Zhang, Eldon Schoop, Floris Weers, Amanda Swearngin, Jeffrey Nichols, Yinfei Yang, Zhe Gan
Paper
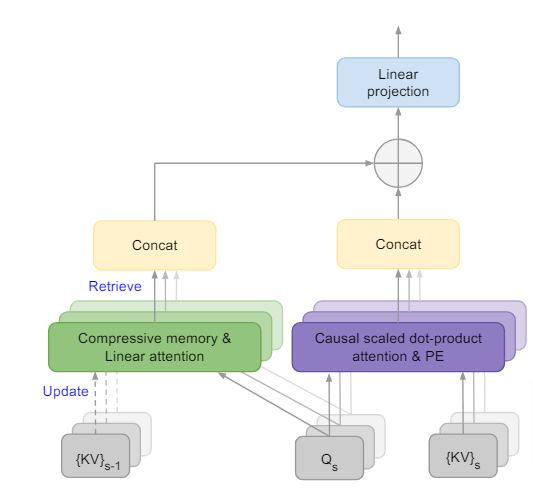
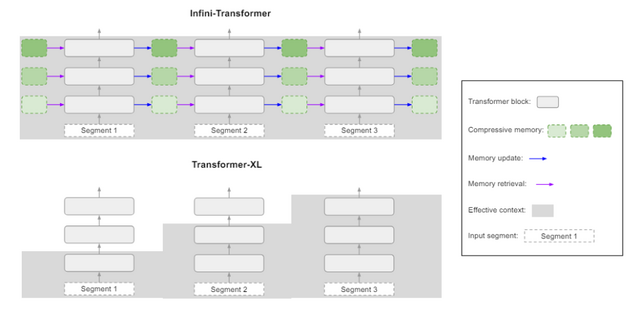
極めて長い入力プロンプトに対応できるLLM向け技術「Infini-attention」をGoogleが開発
近年の大規模言語モデル(LLM)は、非常に長い文脈を理解することが課題となっています。既存のTransformerベースのLLMは、アテンションメカニズムの性質上、メモリと計算量が入力長の2乗に比例して増大してしまいます。
この問題に対し、Googleの研究チームは、「Infini-attention」と呼ばれる新しいアテンション機構を開発しました。Infini-attentionは、文章を理解する仕組みの中に、情報を圧縮して覚えておく「圧縮メモリ」を組み込んだ技術です。メモリは更新して情報を蓄積し、入力に対するクエリを使って、圧縮メモリから関連する過去の情報を検索します。これにより、長い文脈を効率的に取り込めます。
この工夫により、LLMは極めて長い入力を、メモリと計算量を一定に抑えつつ、ストリーミング方式で処理できるようになりました。Infini-attentionを1BのLLMに適応すると100万のシーケンス長にスケールし、パスキー検索タスクを解決しました。さらに、Infini-attentionを備えた8Bモデルは、継続的な事前学習とタスクのファインチューニング後、50万の長さの本の要約タスクにおいて新しいSOTAの結果に到達し、その有効性を実証しました。
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
Paper
「種から花が咲く」「氷が溶けていく」などの物理法則に従った動画を文章から生成できるT2Vモデル「MagicTime」
近年のテキストからビデオを生成するモデル(T2V)は、テキストの説明から高品質の一般的なビデオを合成することに大きな成功を収めています。しかし、従来のT2Vモデルでは、現実世界の物理法則に関する知識が十分にエンコードされていないため、生成されるビデオの動きや変化が限定的だという課題があります。
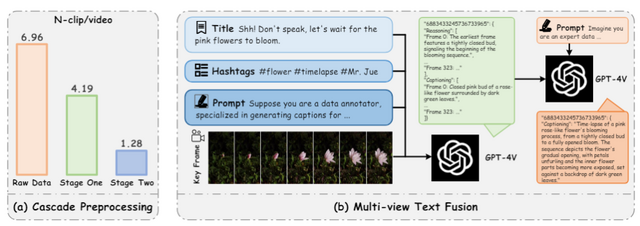
この課題に対し、「MagicTime」と名付けられた新しいアプローチが提案されました。MagicTimeは、タイムラプス動画から現実世界の物理法則を学習し、変容的な生成を実現するT2Vモデルです。
例えば、「種から花が咲く過程」といったテキストを入力すると、MagicTimeは種が発芽し、茎が伸び、つぼみができ、花が開くまでの一連の過程を滑らかに表現した動画を生成します。また、「氷が溶けていく様子」といった指示を与えれば、氷が徐々に小さくなり、水たまりができていく様子を生成してくれます。
MagicTimeの特徴は、MagicAdapter-SとMagicAdapter-Tという2つのアダプターを用いて、空間と時間のトレーニングを個別に行う点にあります。また、独自のデータセットを構築し、「MagicAdapter」と呼ばれるスキームを用いて事前学習済みのT2Vモデルを変容的ビデオ生成用に変換することで、多様な変化パターンを学習しています。
多数の実験により、MagicTimeが高品質でダイナミックな変容ビデオを生成できることが実証されました。この手法は、Open-Sora-Planや他のDiT(Diffusion-Transformer)ベースのT2Vモデルをサポートすることで、Soraの再現に役立つことを目指しているといいます。




MagicTime: Time-lapse Video Generation Models as Metamorphic Simulators
Shenghai Yuan, Jinfa Huang, Yujun Shi, Yongqi Xu, Ruijie Zhu, Bin Lin, Xinhua Cheng, Li Yuan, Jiebo Luo
Paper | GitHub
1枚の画像から高品質な3Dモデルを生成するフレームワーク「InstantMesh」、テンセントなどが開発
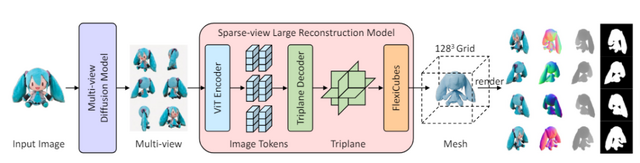
この研究では、「InstantMesh」という手法が提案されています。これは単一画像から高品質な3Dメッシュモデルを数秒で生成するフレームワークです。
InstantMeshは2つの要素技術を組み合わせています。1つ目は教師あり学習済みのマルチビュー画像生成モデルで、単一の入力画像から3D的に整合性のある複数視点の画像を生成します。2つ目は少数視点の3D再構成モデルで、前述の複数視点画像を入力として3Dメッシュを予測します。全体の処理は10秒以内で完了します。
3D再構成モデルの訓練効率を高めるため、微分可能な特殊なモジュールを組み込み、デプスや法線などの幾何情報を活用しながらメッシュ表現に対して直接最適化を行っています。また、モデルアーキテクチャにはトランスフォーマーを採用し、大規模データセットへの拡張性を持たせています。
公開データセットでの評価実験により、InstantMeshが他の最新手法を大きく上回る性能を示しました。


InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, Ying Shan
Paper | GitHub | Demo