




1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第16回目はアップルが初登場。マルチモーダルのLLM「Ferret」を投入しました。合わせて5つの論文をまとめました。
生成AI論文ピックアップ
画像から高品質なコードを生成できるオープンソースのAIモデル「LLaVA-1.5」 Microsoft含む研究者らが開発
低解像度画像の学習だけで、高品質な高解像度画像(4K)を生成 中国テンセント含む研究者ら「ScaleCrafter」開発
画像内の形や場所を言葉で説明するAI「Ferret」 Apple含む研究者らが開発
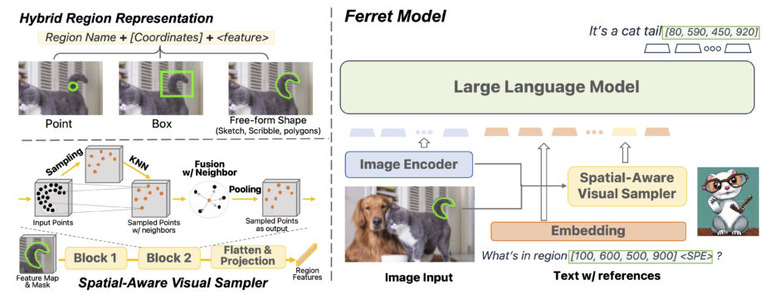
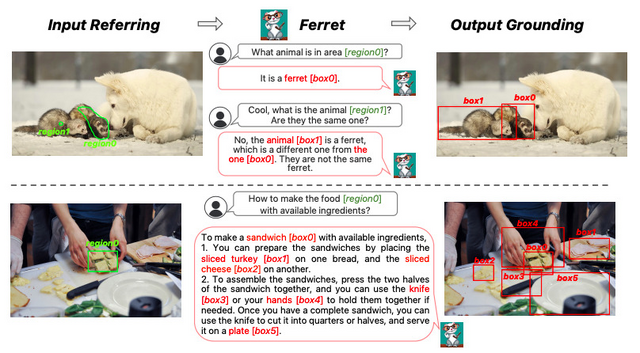
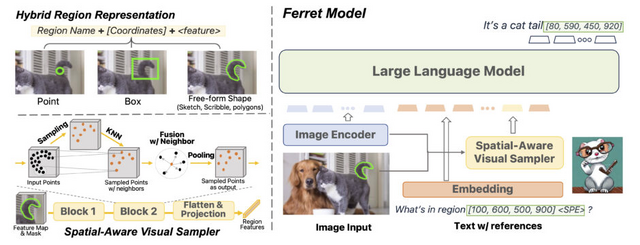
アップルが開発し、GitHubで公開している「Ferret」という新しい技術を紹介します。これは、画像と言語を組み合わせて理解するためのMultimodal Large Language Model(MLLM)を基盤としたモデルです。Ferretの主な特徴は、画像内の特定の部分や領域を自然言語で数値的に表現する能力です。
しかし、単なる点や四角形だけで領域を示すのは不十分です。日常で目にするような複雑な形状や線を正確に表現するための能力も必要です。Ferretは、画像内の指定した物体の領域とテキストを組み合わせて理解し、どんな形状でも正確に捉え、物体の正確な位置を示すことができます。
Ferretが「参照」(画像内の特定の部分や領域を指すこと)および「地点特定」(参照した物体の位置を特定すること)をより効果的に行うため、「GRIT」という大規模なデータセットを構築しました。
このデータセットは、110万のサンプルで構成されており、物や場所の関係、説明など多岐にわたる情報を含んでいます。また、テキストから場所を特定するタスクや、場所からテキストを生成するタスクのデータも取り入れています。このデータセットは、過去の研究やタスクからのデータを基にして作成されました。さらに、ChatGPT/GPT-4の技術を活用し、新たな会話データも追加しました。
この新しい能力を評価するために、「Ferret-Bench」という評価ツールを開発しました。このツールは、「参照の説明」、「参照の推論」、そして「会話中の地点特定」の3つの新しいタスクを含んでいます。
既存のMLLMを「Ferret-Bench」で評価した結果、Ferretはそれらの最も優れたものよりも平均で20.4%高い性能を示しました。さらに、Ferretは物体の誤認を減少させる興味深い特性も持っています。
Ferret: Refer and Ground Anything Anywhere at Any Granularity
Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, Yinfei Yang
Paper | GitHub
画像から高品質なコードを生成できるオープンソースのAIモデル「LLaVA-1.5」 Microsoft含む研究者らが開発
2023年4月に、Microsoftをはじめとする研究者たちは、視覚と言語の理解のための汎用モデル「LLaVA」(Large Language and Vision Assistant)を発表しました。これは、GPT-4を活用して言語と画像の組み合わせたデータを生成し、その上でモデルを構築しています。
LLaVAはマルチモーダルチャットの能力に優れており、未知の画像や指示にもGPT-4のように反応します。入力画像の解説や画像ベースのコード生成など、用途は多岐にわたります。また、GPT-4とは異なり、関連するコードは公開されています。
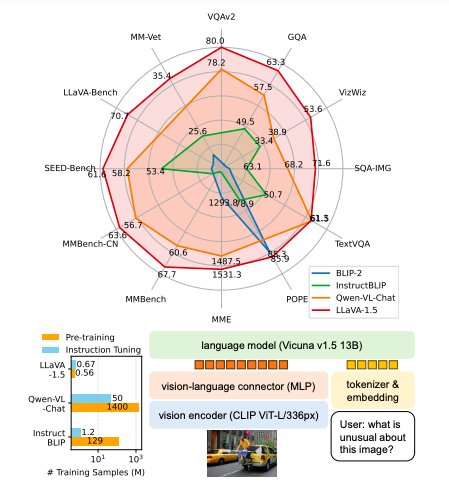
最近、LLaVAフレームワークを基盤として、少しの変更で更に強力な「LLaVA-1.5」が発表されました。具体的には、CLIP-ViT-L-336pxをMLP(Multi-Layer Perceptron)として用い、VQAなどのデータを追加しました。このような変更により、モデルのマルチモーダルな理解力が向上しました。
他のモデルとの比較で、LLaVAはシンプルな設計を保ちつつ、限られたデータでも高い性能を発揮します。最終的に、公開されているたった120万のデータで、1日以内に訓練を完了。11のベンチマークで最先端の性能を達成し、10億規模のデータを用いる方法を上回りました。
Improved Baselines with Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee
Project Page | Paper | GitHub | Demo
低解像度画像の学習だけで、高品質な高解像度画像(4K)を生成 中国テンセント含む研究者ら「ScaleCrafter」開発
テキストから画像を生成するモデル、たとえばStable Diffusion (SD)、SD-XL、Midjourney、IFなどが非常に人気があります。しかしながら、これらのモデルの最大解像度は1024 × 1024にとどまります。
これらのモデルで訓練された画像サイズよりも高解像度の画像を直接サンプリングすると、オブジェクトの繰り返しや不自然なオブジェクトの構造の問題が生じます。例として、512×512の解像度で訓練されたSDモデルを使用して512×1024や1024×1024の解像度の画像をサンプリングすると、オブジェクトが繰り返し出現することがわかります。画像のサイズが大きくなると、この問題はさらに顕著になります。
SDのU-Netの構造を詳細に調査し、その構成要素の受容野(どの部分の入力画像を「見る」かの範囲)を研究しました。その結果、問題の原因は受容野の範囲が狭いことであると判明しました。この発見をもとに、受容野の範囲を動的に調整する新しい方法を提案しました。
そして、この新しい方法を使用することで、オブジェクトの繰り返しを排除した、非常に高解像度の画像(例: 4096 x 4096の解像度)を生成できることが確認されました。これは訓練の解像度の16倍です。また動画でも適応可能です。特筆すべきは、この技術は追加の訓練や調整を必要としない点です。



ScaleCrafter: Tuning-free Higher-Resolution Visual Generation with Diffusion Models
Yingqing He, Shaoshu Yang, Haoxin Chen, Xiaodong Cun, Menghan Xia, Yong Zhang, Xintao Wang, Ran He, Qifeng Chen, Ying Shan
Project Page | Paper | GitHub
ブラウザ上で可能 5枚ほどの顔写真からAI顔写真を生成するWebUIプラグイン「EasyPhoto」
Stable Diffusion(SD)のもっとも知られる応用の一つは、AUTOMATIC1111氏によるStable Diffusion web UI(SD-WebUI)です。これはGradioライブラリを基盤にしたブラウザインタフェースを備えており、SDモデル用のユーザーフレンドリーなインタフェースを提供しています。
SD-WebUIの利便性に着目し、AIポートレートを生成するためのWebUIプラグイン「EasyPhoto」を開発しました。既存の方法が非現実的な照明を導入したり、アイデンティティの喪失に直面する中、EasyPhotoはSDモデルの画像間変換機能を利用して現実的かつ正確な結果を提供します。
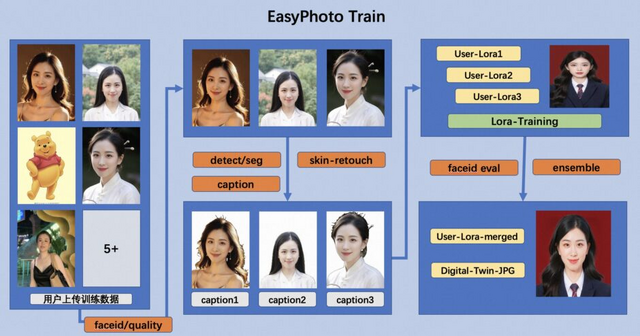
EasyPhotoはWebUIに簡単に追加としてインストール可能で、ユーザーフレンドリーな設計により多くのユーザーが利用できます。SDモデルの力を活用して、EasyPhotoは入力されたアイデンティティによく似た、高品質のAIポートレートを生成できます。
ユーザーは数枚の写真(5から20枚が理想的で、半身の写真、眼鏡なしが望ましい)をアップロードし、自身のデジタルな分身としてLoRAモデルをオンラインで訓練します。このLoRAモデルは、ユーザーの特定のID情報を捉えるために訓練され、訓練済みのモデルは基本的なSDモデルに統合されて推論に利用されます。
推論時には、推論テンプレートの顔部分を再構築します。ControlNetユニットを利用して、入力と出力の画像がどれほど似ているかを確認します。2段階の拡散プロセスにより、生成される画像はユーザーのアイデンティティを維持し、見た目の不整合を最小化します。また、強力なSDXLモデルを利用して、多様で現実的なテンプレートを生成します。
この技術は顔だけでなく、ユーザーIDに関連する他の対象にも適用可能です。そのため、一度モデルを訓練すれば、様々なAI写真を生成することができます。さらに、アニメ風やリアルなスタイルなど、多彩なスタイルから選択することができます。


EasyPhoto: Your Smart AI Photo Generator
Ziheng Wu, Jiaqi Xu, Xinyi Zou, Kunzhe Huang, Xing Shi, Jun Huang
Paper | GitHub
AI生成した画像の“不自然な箇所”を自動検出・修正するシステム Adobeなどの研究者らが開発
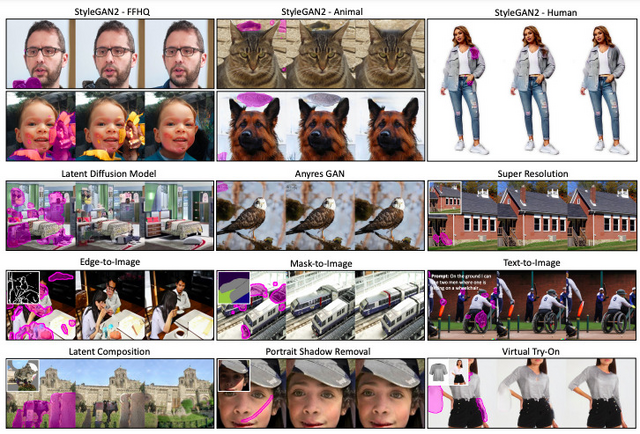
生成モデルは、画像の修復、画像間変換、テキストから画像への変換など、さまざまな画像合成タスクで顕著な進歩を遂げています。しかしながら、最先端のモデルであっても、時折、実際には存在しえない内容を生成することや、画像の特定の領域に不快な欠陥(アーティファクト)を示すことがあります。
そのため、通常の画像編集プロセスでは、ユーザーは生成された画像を手作業で修正し、これらの領域をマスキングおよび再編集して完璧さを追求します。アーティファクトの手動での修正は時間がかかり、反復的な作業が必要です。このようなアーティファクトは、人の監督なしに画像の合成、編集、またはバッチ処理を完全に自動化するための生成モデルにとっての課題となっています。
この目的を達成するため、本研究では生成された画像のデータセットを収集し、合成タスクごとにアーティファクトをピクセル単位で識別するラベルを付加しました。具体的には、1万168枚の画像からなる新しい高品質なデータセットで、各ピクセルに人間が注釈したアーティファクトの情報が含まれています。このデータセットは10種類の異なる画像合成タスクを網羅しています。
このデータセットを利用して、多様なタスクでアーティファクトを特定するセグメンテーションモデルを訓練しました。事前に訓練されたアーティファクト検出モデルは、新しいモデルにも適用可能で、限られたトレーニングデータでも高い精度で動作します。
アーティファクト検出に加えて、いくつかの実用的なアプリケーションも提案しています。その中で最も注目すべきは、画像修復を用いて生成された画像のアーティファクトを自動的に修正することです。しかし、DALL-Eや Stable Diffusionのような先進的な拡散画像修復モデルは、手や顔の特徴などの高忠実度のオブジェクト詳細を生成する際に、時折失敗することが確認されています。
詳細な部分の生成に課題があるため、「ズームイン画像修復パイプライン」という新しい手法を導入しました。このシンプルな手法は、オブジェクトの詳細生成に関する問題を効果的に軽減し、モデルの再訓練や変更を行うことなくこれを達成します。

Perceptual Artifacts Localization for Image Synthesis Tasks
Lingzhi Zhang, Zhengjie Xu, Connelly Barnes, Yuqian Zhou, Qing Liu, He Zhang, Sohrab Amirghodsi, Zhe Lin, Eli Shechtman, Jianbo Shi
Project Page | Paper | GitHub