




1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第11回目は、Google DeepMindによるLLM利用最適化手法、Google Mapsを利用して3D都市を無制限に生成するなど5つの論文をまとめました。
生成AI論文ピックアップ
大規模言語モデルを最適化ツールとして活用する手法「OPRO」 Googleの研究者らが開発
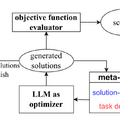
Google DeepMindに所属する研究者らは、大規模言語モデル(LLM)を最適化ツールとして活用するシンプルかつ効果的なアプローチ、「Optimization by PROmpting」(OPRO)を提案します。
最適化とは、初めに得られた答えを少しずつ改良して、より優れた答えを見つけ出すプロセスのことを指します。OPROは、LLMに自然言語で問題を説明し、その問題に対する最適な回答を求めるものです。
具体的に言うと、問題をOPROに伝えると、それに対する答えを生成します。そして、その答えを新しいヒントとして使い、さらに良い答えを生成します。このプロセスを繰り返すことで、最も適切な答えを探求します。
OPROは、数学やコンピュータサイエンスの問題解決にも応用でき、手作りの最適化アルゴリズムと同等、あるいはそれを上回る結果が得られることが確認されました。さまざまな問題に対して有効であることが確認され、このアプローチが提供するヒントは、人間が考えるヒントよりも高い性能を持つことが示されました。
Large Language Models as Optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, Xinyun Chen
Paper
大規模言語モデルのマルチモーダル指示チューニング法「ImageBind-LLM」
近年、大規模言語モデル(LLM)の指示チューニングの進展が著しいものとなっています。既存のLLaMAを独自のデータで微調整する手法として、AlpacaやLLaMAAdapterなどが提案されています。これらの手法では、言語や画像の指示をLLMに組み込む方法が進められています。
しかし、テキスト、画像、音声、3D点群、ビデオといったマルチモーダリティの指示の取り扱いに関する研究は、まだ進展していない状況です。この背景から、新しいモデル「ImageBind-LLM」が提案されました。このモデルは、画像とテキストのトレーニングだけで、音声、3D点群、動画といったさまざまなタイプの情報を同時に理解する能力を持っています。
手法はLLaMAの微調整をベースにしており、事前学習されたImageBindの共有埋め込み空間を利用し、画像と言語のデータだけでマルチモーダリティ指示のチューニングを行います。
また、モダリティ間の差異を軽減するため、埋め込みの強化を目的とした新しいキャッシュモデルも提案しています。このキャッシュモデルは、ImageBindによって抽出されたトレーニングデータセットの画像特徴を数百万にわたって含んでおり、これによって高品質な応答を実現します。
このアプローチにより、ImageBind-LLMはテキスト、画像、音声、ビデオなどの多様なモダリティの指示に適切に反応できます。3D領域の指示に対しては、Point-Bindの事前学習された3Dエンコーダを使用して、入力される3D点群を効果的にエンコードします。

ImageBind-LLM: Multi-modality Instruction Tuning
Jiaming Han, Renrui Zhang, Wenqi Shao, Peng Gao, Peng Xu, Han Xiao, Kaipeng Zhang, Chris Liu, Song Wen, Ziyu Guo, Xudong Lu, Shuai Ren, Yafei Wen, Xiaoxin Chen, Xiangyu Yue, Hongsheng Li, Yu Qiao
Paper | GitHub
低コストで大規模言語モデルを訓練できるモデル「FLM-101B」。LLMのIQテストも考案
大規模言語モデル(LLM)の訓練コストは高く、少数の企業だけがこれを訓練することができます。さらに、訓練データの量が増加する現在の傾向は、LLMの研究コストを引き上げています。
この研究では、モデルを低コストで訓練するための新しい方法として「growth strategy」(成長戦略)を提案します。これは、訓練過程でパラメータの数を固定しないもので、モデルを小さく始め、段階的に拡大していく方法です。
この成長戦略を使用して、101Bのパラメータと0.31TBのトークンを持つLLMの訓練を10万ドルの予算で試みました。結果、計算コストが大幅に削減できることが示されました。モデルのアーキテクチャはFreeLMの進化形として、「FLM-101B」と命名され、公開予定です。
次に、LLMの研究でのもう一つの大きな課題は、モデルの評価、すなわちモデルの「賢さ」をどう評価するかです。
この研究ではモデルの評価のために「知能指数」(IQ)を測定する新しい方法を提案します。これは、LLMのIQを評価するための体系的なベンチマークです。
現在の評価方法は、モデルが既知の情報をどれだけ正確に答えるかに焦点を当てていますが、これだけではモデルの真の「賢さ」を適切に測定するのは難しいです。
そこで、人間のIQテストと似ている方法で、モデルが新しい問題にどれだけ効果的に取り組むかを評価するIQベースの方法を提案しています。これは、モデルが単に知識を再生するだけでなく、新しい問題に対してどれだけ論理的に考えるかを評価するものです。
評価の結果、提案モデル「FLM-101B」は、GPT-3やGLM-130Bといった高性能なモデルと同等のパフォーマンスを達成していることが確認されました。
FLM-101B: An Open LLM and How to Train It with $100K Budget
Xiang Li, Yiqun Yao, Xin Jiang, Xuezhi Fang, Xuying Meng, Siqi Fan, Peng Han, Jing Li, Li Du, Bowen Qin, Zheng Zhang, Aixin Sun, Yequan Wang
Paper | Hugging Face
物体検出のエラーを見つけるシステム「ObjectLab」
自動運転車などの繊細なシステムを動かすにも関わらず、コンピュータビジョンにおける物体検出は、多くの実際のトレーニングデータセットに見られる注釈のエラーにより、非常に脆弱です。これは、データセットが大量の人手によるラベリングを必要とし、そのラベリング作業が必然的に不完全となるためです。
この文脈で「ObjectLab」というアルゴリズムを提案します。これは、人のラベリングミス、例えば見落とされたバウンディングボックス、不適切な位置のボックス、クラスラベルの誤った割り当てなど、物体検出ラベルの多様なエラーを検出するシンプルな方法です。
ObjectLabは、任意の訓練済み物体検出モデルを利用して各画像のラベル品質を評価し、ラベルが誤っている画像を自動的にレビュー・修正のための優先順位をつけることができます。このようにして誤ったデータを適切に取り扱うことで、モデリングコードを変更せずとも、より高品質な物体検出モデルの訓練が可能となります。
さまざまな物体検出データセット(COCOを含む)やモデル(Detectron-X101やFaster-RCNNを含む)を通じて、ObjectLabは他のラベル品質スコアと比べて、はるかに優れた精度/再現性で注釈のエラーを検出します。

ObjectLab: Automated Diagnosis of Mislabeled Images in Object Detection Data
Ulyana Tkachenko, Aditya Thyagarajan, Jonas Mueller
Paper
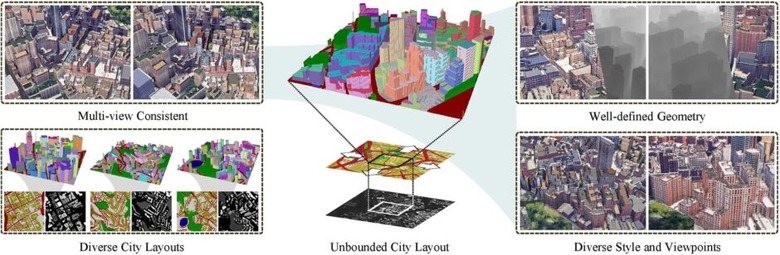
Google Earthを利用して無制限に3D都市を生成するAI「CityDreamer」
最近、3Dの自然景観生成への研究が盛んに行われていますが、3Dの都市生成に関する研究はまだ十分に進められていません。この背景には、人々が都市環境の構造的な歪みに敏感であるため、3Dの都市生成には独自の課題が存在するからです。
さらに、建物のようなオブジェクトは、自然景観の木などに比べて外観の多様性が高いため、3Dでの都市生成は自然景観生成よりも複雑だと言えます。
この都市環境の多様性に対応するため、「CityDreamer」という名の構成的な生成モデルを提案します。CityDreamerは、従来のアプローチとは異なり、ビルとその他の背景オブジェクト(道路、緑地、水域など)の生成を2つの独立したモジュールに分けて取り組んでいます。
これらのモジュールは、鳥瞰のシーン表現を利用し、敵対的トレーニングを通じてボリュームレンダラーで写実的な画像を生成します。特に、シーンのパラメータ設定は、背景オブジェクトとビルの特性を考慮して慎重に調整されています。
また、実際の都市の画像を大量に収集したOSMとGoogle Earthの2つのデータセットを用意し、生成される3D都市がレイアウトや外観で実際に近いものとなるように最適化しています。
多くの実験を通して、CityDreamerが最先端の技術よりもさまざまなリアルな3D都市生成において優れた結果をもたらしていることが証明されています。
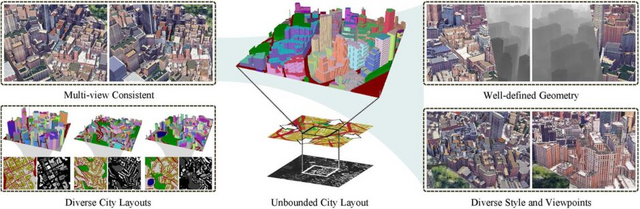
CityDreamer: Compositional Generative Model of Unbounded 3D Cities
Haozhe Xie, Zhaoxi Chen, Fangzhou Hong, Ziwei Liu
Project Page | Paper

















![Mia(ミーア)おしゃべり猫型ロボット ブラック・充電なしモデル 全国47都道府県の方言対応 AIペット 癒やし 家族 コミュニケーションロボット 高齢者 見守り ギフト プレゼント [性格カスタマイズ/リマインド機能搭載] image](https://m.media-amazon.com/images/I/31JfsEwtA0L._SL160_.jpg)
![Mia(ミーア)おしゃべり猫型ロボット ホワイト・充電なしモデル 全国47都道府県の方言対応 AIペット 癒やし 家族 コミュニケーションロボット 高齢者 見守り ギフト プレゼント [性格カスタマイズ/リマインド機能搭載] image](https://m.media-amazon.com/images/I/31PWkfpsEPL._SL160_.jpg)