

1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第29回目は、生成AI最新論文の概要4つとおまけ2つを紹介します。
生成AI論文ピックアップ
GPT-4の次に性能が良いオープンソースの大規模言語モデル「Mixtral 8x7B」はGemini ProやClaude、GPT-3.5を凌駕する性能
【おまけ】人物や背景、物や衣服などを高品質に入れ替えられる画像編集AI「ReplaceAnything」、アリババグループが開発
テキスト指示から高品質で美麗な動画を生成するモデル「MagicVideo-V2」、Bytedanceが開発
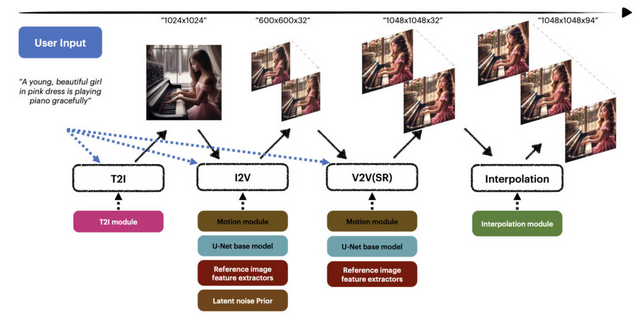
MagicVideo-V2は、テキストから高品質かつ美しい動画を生成するための新しいT2V(Text-to-Video)技術です。この手法は、4つのステージを経て動画を生成するエンドツーエンドのパイプラインを採用しています。
最初の「テキストから画像」(Text-to-Image、T2I)モジュールでは、ユーザーからのテキスト入力を受け取り、それを基に初期画像を生成します。次に、「画像から動画」(Image-to-Video、I2V)モジュールでは、生成された画像を基に低解像度の動画のキーフレームを生成します。
「動画から動画」(Video-to-Video、V2V)モジュールでは、既に生成されたキーフレームの解像度を高め、詳細を精細化します。これにより、高解像度で品質の高い動画に仕上げます。最後に、「動画フレーム補間」(Video Frame Interpolation、VFI)モジュールでは、生成されたキーフレーム間に追加のフレームを挿入し、動画の動きをより滑らかにします。これにより、全体的な動画の品質と視覚的な流れが向上します。
最先端のT2Vシステム(RunwayのGen-2、MoonValley、Pika 1.0、Morph、Stable Video Diffusionなど)との比較実験において、MagicVideo-V2は他の方法と比較して優れた性能を明確に示しました。特に、動画のフレーム品質、動きの一貫性、構造エラーの少なさなどの点で、MagicVideo-V2が優位に立っていました。


MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation
Weimin Wang, Jiawei Liu, Zhijie Lin, Jiangqiao Yan, Shuo Chen, Chetwin Low, Tuyen Hoang, Jie Wu, Jun Hao Liew, Hanshu Yan, Daquan Zhou, Jiashi Feng
Project | Paper
GPT-4の次に性能が良いオープンソースの大規模言語モデル「Mixtral 8x7B」はGemini ProやClaude、GPT-3.5を凌駕する性能
Mistral AIチームが2023年12月にリリースした「Mixtral 8x7B」は、Sparse Mixture of Experts(SMoE)アーキテクチャを採用した強力な大規模言語モデル(LLM)です。Mixtral 8x7Bは、商業用途に無料で利用可能なApache 2.0ライセンスの下でリリースされています。
Mixtral 8x7Bは、同チームが2023年5月にリリースした「Mistral 7B」の上位モデルで、MistralからMixtralへと微妙に名前が変わっています。Mistral 7Bのアーキテクチャを踏襲しつつ、各レイヤーに8つのフィードフォワードブロックを配置しています。各トークンごとに、各レイヤーで2つのフィードフォワードブロックを選択し、それらの出力を組み合わせます。
その結果、各トークンは470億のパラメータへのアクセスを持ちながら、推論中には130億のアクティブパラメータのみを使用します。これにより、効率的な計算と高速な推論が可能になります。
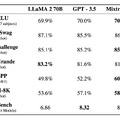
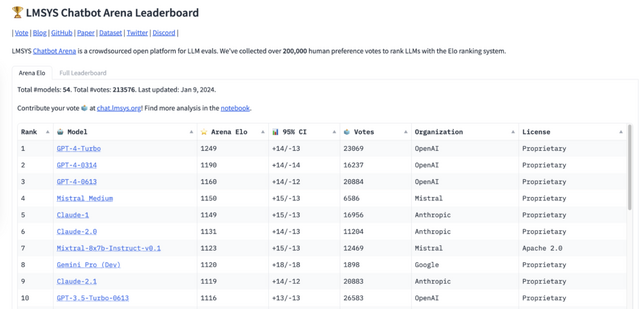
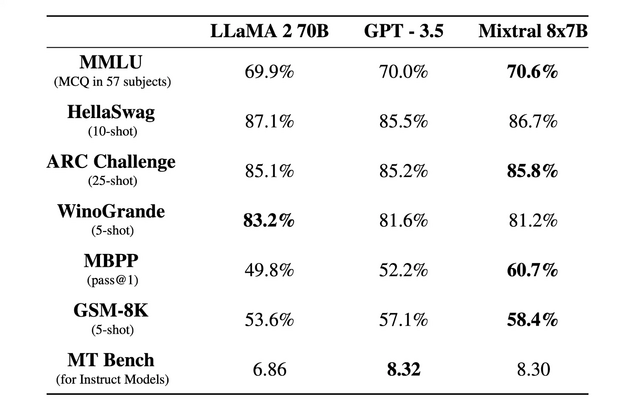
Mixtral 8x7Bは、数学、コード生成、多言語タスクなど、さまざまなベンチマークでLlama 2 70BやGPT3.5を上回っています。さらに執筆現在(2024年1月14日)、LLMのベンチマークプラットフォーム「Chatbot Arena」において、「Mistral Medium」がGPT-4に続く4位にランクインしました。これはClaude-1やGemini Pro(Dev)、GPT-3.5 Turbo-0613を凌駕するものです。

Mixtral of Experts
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed
Project | Paper | GitHub
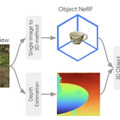
3Dシーンにテキスト指示とバウンディングボックスで物体を挿入できるモデル「InseRF」、Googleなどが開発
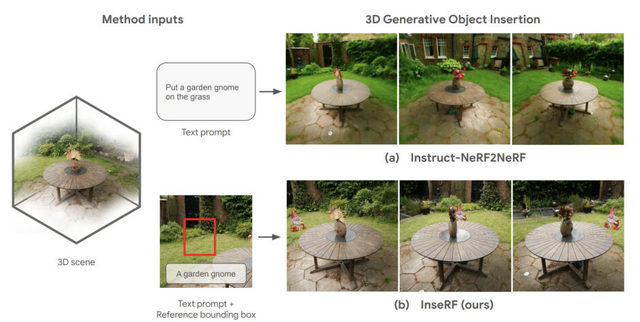
テキスト記述を用いて3Dシーンにオブジェクトを挿入する新しい手法「InseRF」が提案されました。この技術は、NeRFで再構築された3Dシーンとテキストプロンプトを活用し、3Dシーン編集を容易にするアプローチです。
InseRFの最大の特徴は、ユーザーがテキスト入力で特定のオブジェクトを3Dシーンに追加できる点です。また、配置したい場所は2Dバウンディングボックスを用いて直感的に指定することができます。このように、InseRFを使用すると、3Dシーンの編集が容易になります。
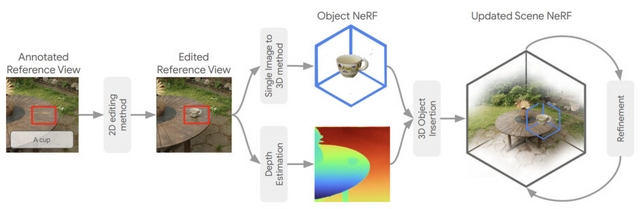
ユーザーが指定したテキストとバウンディングボックスに基づいて、2D画像内にオブジェクトが生成されます。この2Dオブジェクトは単眼深度推定技術を使用して3D空間に適切に配置され、その後3Dモデルに変換されて推定された位置に配置されます。
挿入されたオブジェクトの照明や影に関する課題はありますが、テキスト指示とバウンディングボックスのみを用いた簡便な挿入方法は、今後の発展に期待が持てます。

InseRF: Text-Driven Generative Object Insertion in Neural 3D Scenes
Mohamad Shahbazi, Liesbeth Claessens, Michael Niemeyer, Edo Collins, Alessio Tonioni, Luc Van Gool, Federico Tombari
Project | Paper
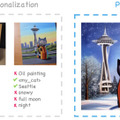
好きなキャラや物などを生成画像に調和して合成できる個人化AI「PALP」、Googleなどが開発
PALPは、テキストから画像を生成する新しい技術です。この方法は、ユーザーが指定した特定のテキスト(プロンプト)に基づいて、個人的なコンテンツ(例えば、ユーザーのペット、猫の置き物、特定の人など)を含む合成画像を生成することを目的としています。
PALPでは、事前に学習済みのモデルの知識を利用して、パーソナライズされたモデルがターゲットプロンプトを理解し続けるようにします。訓練中にターゲットプロンプトを把握し、パーソナライズされたモデルが学習済みのモデルと一致するように調整します。
このアプローチは、「Personalization」と「Prompt-alignment」の2つの主要な部分から構成されています。前者ではモデルに新しい個人的なコンテンツについて学習させ、後者ではモデルがターゲットプロンプトの要素を忘れないようにします。
結果として、PALPはプロンプトと個人的なコンテンツの整合性において優れた結果を示し、複雑なプロンプトを含む細かい要求に基づく画像の生成を可能にします。また、複数の個人的なコンテンツを組み合わせたり、テキストだけでなく芸術作品からもインスピレーションを得るなど、新しい応用例も提案しています。



PALP: Prompt Aligned Personalization of Text-to-Image Models
Moab Arar, Andrey Voynov, Amir Hertz, Omri Avrahami, Shlomi Fruchter, Yael Pritch, Daniel Cohen-Or, Ariel Shamir
Project | Paper
【おまけ】Animate Anyoneのオープンソース再現実装版が登場「Moore-AnimateAnyone」
論文ではないのですが、Animate Anyoneを再現実装した「Moore-AnimateAnyone」を紹介します。本家のAnimate Anyoneは、2013年12月にアリババグループなどによって開発・発表されたAIモデルです。特定のポーズシーケンス(骨格動画)に従って、画像内のキャラクターや写真内の人物をアニメーション化できる技術で、多くの注目を集めました。生成AIウィークリーでも紹介しました。
このような画像内のキャラクターを動かすアプローチは以前から存在しましたが、Animate Anyoneはその精度の高さで評価されました。動きの一貫性を保ちつつ、AIに特有のアーティファクトを最小限に抑え、滑らかに動作します。動いた際の髪や服の揺れも再現され、リアリズムも高いです。
そんなAnimate Anyoneを再現実装した「Moore-AnimateAnyone」のリポジトリがGitHubに公開されました。既にX上で、好きなキャラクターや人物を任意の動きで踊らせている出力結果が多く見られます。
ただし、リポジトリの説明にもあるように、本家のパフォーマンスにはまだ及んでおらず、およそ80%のレベルに留まっています。デモ(解像度 512×768)やX上での各ユーザーによる出力結果を見ても、明らかな不自然さが確認できます。今後の改善が予定されています。

Moore-AnimateAnyone
GitHub
【おまけ】人物や背景、物や衣服などを高品質に入れ替えられる画像編集AI「ReplaceAnything」、アリババグループが開発
論文やコードはまだ公開されていませんが、アリババグループがコンテンツ置き換え用のAIモデルを発表しました。詳細はまだ明らかにされていませんが、この技術はユーザーが指定したマスクされたオブジェクトのアイデンティティを厳守しつつ、新しいコンテンツにそれを合成するものです。
出力結果を見ると、合成の質の高さが確認できます。デモでは、人物(顔)の入れ替え、衣服の入れ替え、背景の入れ替え、物体の入れ替えなど、様々なシーンでの合成が示されています。





ReplaceAnything as you want: Ultra-high quality content replacement
Binghui Chen, Chao Li, Chongyang Zhong, Wangmeng Xiang, Yifeng Geng, Xuansong Xie
Project | GitHub | Demo