
1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第23回目は、AIアニメーションを次の段階に進ませる技術と大きな脚光を浴びた「Animate Anyone」、3D Gaussian Splattingを使った新しい3D応用技術など、生成AI最新論文の概要5つをお届けします。
生成AI論文ピックアップ
画像内のキャラクターや写真内の人物を骨格動画に応じて動かせる「Animate Anyone」 アリババらが開発
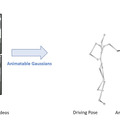
この研究では、キャラクターの画像をアニメーションビデオに変換する新しい方法「Animate Anyone」を提案しています。この方法では、特定のポーズシーケンス(骨格動画)に従って、画像内のキャラクターや写真内の人物をアニメーション化できます。
従来の方法と比較して、Animate Anyoneは所望する動きの一貫性を保ちながら、時間的なジッターやちらつきのない高精度のビデオを生成する能力を持っています。さらに、動いた際に揺れる髪や服の動きも再現されています。
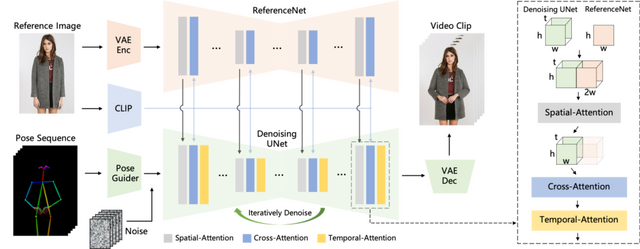
Animate Anyoneは、Stable Diffusionのネットワークの設計と事前に学習させた重みを利用します。この技術は、Stable Diffusionから学んだ方法とデータを使って、マルチフレーム画像を扱うことができる特別なネットワーク(UNet)を改良しています。
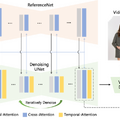
まず、キャラクターの動き(ポーズシーケンス)をコンピュータが理解できる形式に「Pose Guider」でデジタルデータに変換します。次に、この変換したデータを複数の画像フレームのノイズと組み合わせ、「Denoising UNet」を通じてノイズを取り除き、ビデオを作成します。
このプロセスには、空間的アテンション、クロスアテンション、そして時間的アテンションという重要な部分が含まれ、これらはビデオの品質を向上させるために使用されます。さらに、新しく設計された「ReferenceNet」を利用し、元のキャラクターの参照画像から詳細な特徴を抽出してDenoising UNetに組み込みます。
「Temporal Layer」という機能も組み込まれており、動画を作る際に異なる時間に撮影されたフレーム間の関係を理解し、ビデオの連続性と滑らかさを保証するために使用されます。最終的に、これらのデータは「VAEデコーダ」を使用して実際のビデオに変換されます。
このモデルは、UBCファッションビデオデータセットとTikTokデータセットという2つのビデオ合成ベンチマークで評価され、最先端の結果を達成しています。


Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
Li Hu, Xin Gao, Peng Zhang, Ke Sun, Bang Zhang, Liefeng Bo
Project | Paper | GitHub
話した言葉をリアルタイム翻訳できるシステムMeta「Seamless」 話し方や感情なども忠実に再現
Meta AIが提案した新システム「Seamless」は、異なる言語間での音声翻訳をリアルタイムで実現します。Seamlessは約100言語の翻訳をサポートし、遅延は2秒未満で、話者が話している間に翻訳を開始する機能を持っています。
Seamlessは、新たに開発した「SeamlessM4T v2」をベースにしているモデル「SeamlessExpressive」と「SeamlessStreaming」を統合したシステムになります。
SeamlessM4T v2は、基本的な多言語・マルチモーダルモデルで、他の2つのモデルの基礎になります。100言語近くをサポートし、様々な音声およびテキスト翻訳タスクで最先端の精度を実現しています。これはSeamlessM4Tの改良版です。
SeamlessExpressiveは、音声から音声への翻訳で、話者の感情や口調、イントネーションなどの表現を正確に再現することに特化しています。また、話し方の速さや休止のリズムなどの韻律の側面にも注目しています。英語、スペイン語、ドイツ語、フランス語、イタリア語、および中国語の言語間の翻訳をサポートし、表現的なS2ST(音声から音声への翻訳)を可能にします。
SeamlessStreamingは、約2秒の遅延で高品質な翻訳を提供するストリーミングモデルです。話が完了するのを待たずに低遅延で目標言語の翻訳を生成することができます。同時に多対多の翻訳をサポートし、SeamlessM4T v2と同じ言語範囲で約100の入力・出力言語に対するASR(自動音声認識)とS2TT(音声からテキストへの翻訳)をサポートするとともに、約100の入力言語と36の出力言語に対するS2ST(音声から音声への翻訳)もサポートしています。
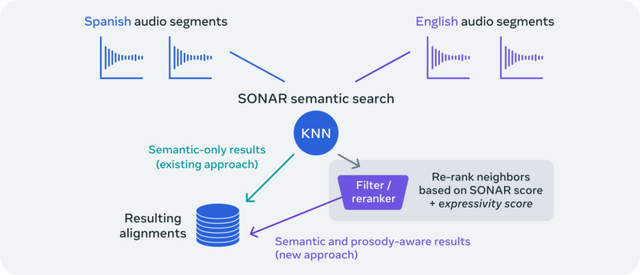
「SeamlessAlign」というデータセットの拡張版は、既存の47万時間に加えてさらに11万4800時間の音声とテキストの整合データを含んでおり、37言語から76言語へと対応範囲を広げています。

Seamless: Multilingual Expressive and Streaming Speech Translation
Loïc Barrault, Yu-An Chung, Mariano Coria Meglioli, David Dale, Ning Dong, Mark Duppenthaler, Paul-Ambroise Duquenne, Brian Ellis, Hady Elsahar, Justin Haaheim, John Hoffman, Min-Jae Hwang, Hirofumi Inaguma, Christopher Klaiber, Ilia Kulikov, Pengwei Li, Daniel Licht, Jean Maillard, Ruslan Mavlyutov, Alice Rakotoarison, Kaushik Ram Sadagopan, Abinesh Ramakrishnan, Tuan Tran, Guillaume Wenzek, Yilin Yang, Ethan Ye, Ivan Evtimov, Pierre Fernandez, Cynthia Gao, Prangthip Hansanti, Elahe Kalbassi, Amanda Kallet, Artyom Kozhevnikov, Gabriel Mejia Gonzalez, Robin San Roman, Christophe Touret, Corinne Wong, Carleigh Wood, Bokai Yu, Pierre Andrews, Can Balioglu, Peng-Jen Chen, Marta R. Costa-jussà, Maha Elbayad , Hongyu Gong, Francisco Guzmán, Kevin Heffernan, Somya Jain, Justine Kao, Ann Lee, Xutai Ma, Alex Mourachko, Benjamin Peloquin, Juan Pino, Sravya Popuri, Christophe Ropers , Safiyyah Saleem, Holger Schwenk , Anna Sun , Paden Tomasello, Changhan Wang, Jeff Wang, Skyler Wang, Mary Williamson
Project | Paper | GitHub | Demo
リアルな動きを持つ高品質なアバターを生成するモデル「Animatable Gaussians」
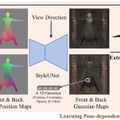
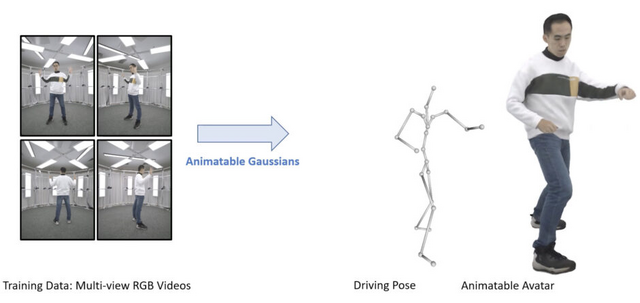
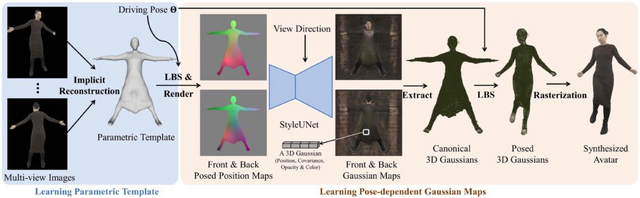
この研究では、「Animatable Gaussians」という新しいアバター表現技術が提案されています。この技術は、多角度のRGBビデオからリアルな動きを持つ高品質なアバターを作成する方法です。従来のNeRFベースの手法と異なり、明示的なポイントベースの表現である「3D Gaussian Splatting」を用い、2Dの畳み込みニューラルネットワーク(CNN)を活用して、高い忠実度の人間の外観をモデル化します。
この手法は、提案されたテンプレートに基づくパラメータ化とポーズ投影戦略により、詳細な人間の外観を忠実に再構築すると同時に、新しいポーズの合成においてリアルな衣服の動きも生成できます。
最初のステップでは、多角度からの画像を使用してキャラクター固有のテンプレートを作成します。これは、キャラクターの基本的な形状や特徴を捉えるためのものです。
次のステップでは、StyleUNetと呼ばれるネットワークを用いて、キャラクターが取る可能性のあるさまざまなポーズに基づいた正面と背面から見た2Dの画像(ガウスマップ)に変換します。これらの画像から、ポーズに応じた3D形状を生成し、最終的にこれを特定のカメラの視点から見た画像に変換します。
評価実験では、他の最先端のアバターアプローチよりも優れていることが示されています。

Animatable Gaussians: Learning Pose-dependent Gaussian Maps for High-fidelity Human Avatar Modeling
Zhe Li, Zerong Zheng, Lizhen Wang, Yebin Liu
Project | Paper | GitHub
写真から3Dシーンを生成できる3D Gaussian Splattingを軽量化する技術「LightGaussian」
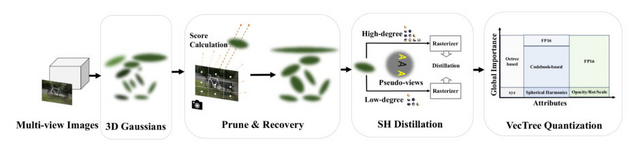
3Dシーンを生成する点ベースの手法「3D Gaussian Splatting」(3D-GS)は、顕著な成果を上げていますが、大量のストレージを必要とする問題があります。この問題は、3Dシーンを構築するために必要な点(ポイント)の数が多く、大規模なシーンではギガバイト単位のデータが必要になることに起因しています。
「LightGaussian」という新しいフレームワークは、この問題に対処します。LightGaussianは、3Dシーンを構成する際に必要な点の数を減らすプロセスを採用しています。このプロセスにより、シーンの質を維持しつつ必要なデータ量を大幅に削減することが可能です。また、LightGaussianは、シーンの外見を保ちながらデータをコンパクトにする技術も採用しています。
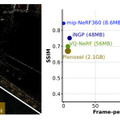
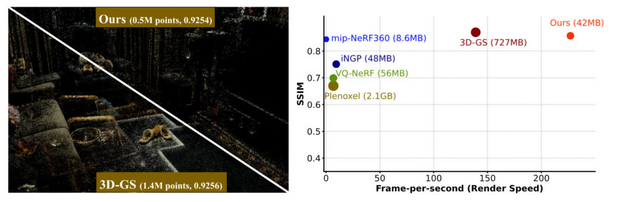
これらの技術により、3Dシーンを構成するポイントの数を大幅に削減できます。具体的には、149万個のガウス分布を57万5000個まで減らし、データ容量を727MBから42MBまで削減できます。この変更による画像品質の低下はごくわずかです。
さらに、LightGaussianは複雑なシーンのレンダリング速度を向上させます。詳細な背景を含む複雑なシーンでも、1秒間に200以上のフレーム(FPS)を実現できます。これは、3Dレンダリングの応用範囲を広げるための実用的な解決策を提供することを意味しています。

LightGaussian: Unbounded 3D Gaussian Compression with 15x Reduction and 200+ FPS
Zhiwen Fan, Kevin Wang, Kairun Wen, Zehao Zhu, Dejia Xu, Zhangyang Wang
Project | Paper | GitHub
テキスト指示から3D画像を生成する新モデル「GeoDream」
GeoDreamは、テキストから3D画像を生成する新しい方法です。この技術の開発は、従来のテキストから画像への変換手法、特に2D拡散モデルが、3Dの幾何学的構造を正確に捉えるのに苦労しているという問題に対応するために行われました。生成された3D形状が一貫性を欠き、画像に不自然なアーティファクトが現れるという問題です。
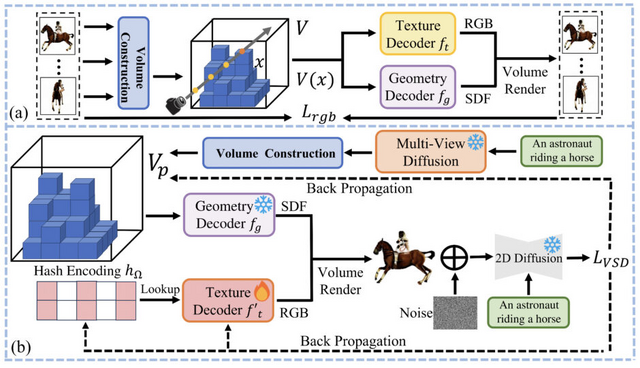
GeoDreamのプロセスは2つの主要なステップから成り立っています。第1のステップでは、3Dの形や外観の情報を特定のデータ構造(コストボリューム)にエンコードし、これを3Dの基本情報として使用します。
第2のステップでは、この基本情報を2Dの画像生成モデルと組み合わせてさらに精緻化し、結果として高品質で正確な3D画像が生成されます。これにより、GeoDreamはリアルで詳細な3Dコンテンツの作成を可能にします。
GeoDreamの重要な特徴は、2Dの画像生成と3Dの形状生成を分けて考え、それぞれのプロセスを細かく調整し、3Dの形状を改善することです。
実験により、GeoDreamは他の最新の3D生成技術よりも優れていることが示されています。これは、GeoDreamが一貫性のある3Dテクスチャメッシュを生成し、高解像度でリアルな画像を提供できることを意味します。


GeoDream: Disentangling 2D and Geometric Priors for High-Fidelity and Consistent 3D Generation
Baorui Ma, Haoge Deng, Junsheng Zhou, Yu-Shen Liu, Tiejun Huang, Xinlong Wang
Project | Paper | GitHub