


1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第20回目は、Stable Diffusion微調整モデルなどを高速化するツール「LCM-LoRA」、画像理解を得意とするオープンソース視覚言語モデル「CogVLM」をはじめとする、生成AI最新論文の概要5つをお届けします。
生成AI論文ピックアップ
Stable Diffusion微調整モデルなどを高速化するツール「LCM-LoRA」 Hugging Faceらが開発
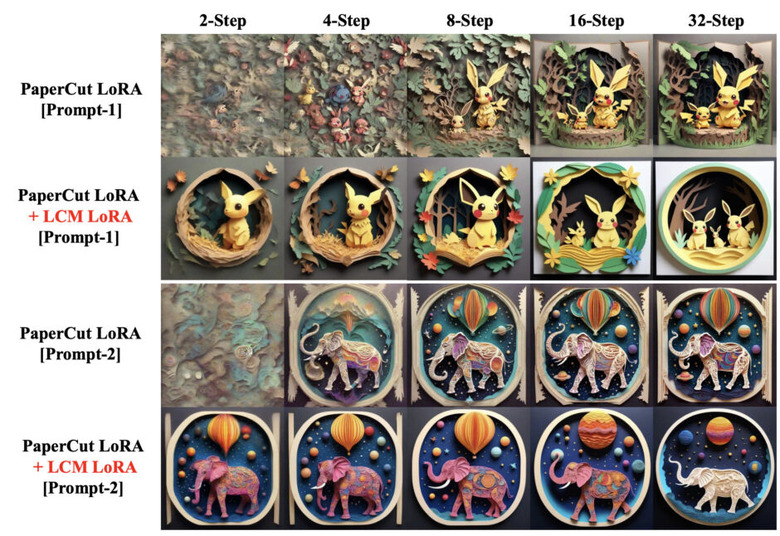
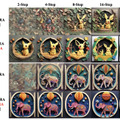
2023年10月に登場した「Latent Consistency Model」(LCM)は、元のモデルを蒸留して、少ないステップ(4~8ステップ)で画像を生成するバージョンに変換する方法です。適応する元のStable Diffusion(SD)では、画像を生成するのに25から50のステップが必要でしたが、LCMを使うと、そのステップ数を大幅に減らすことができます。
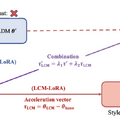
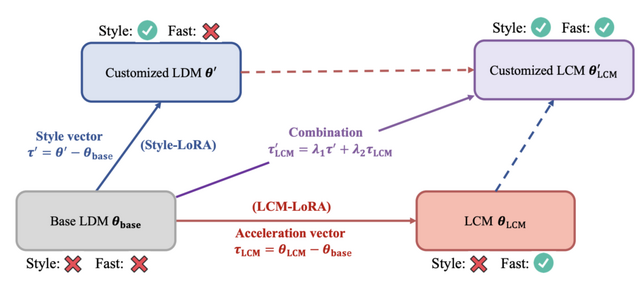
そして、LCMの拡張として「LCM-LoRA」がこの研究で紹介されています。LCM-LoRAは、トレーニングなしで高速な推論を可能にする加速モジュールです。SDXLや様々なSD微調整モデル、SD LoRAsに組み込んで最小ステップでの高速推論をサポートすることができます。
以前の技術、例えばDDIMやDPM-Solverなどと比較して、LCM-LoRAはニューラルネットワークに基づいた新しい種類の高速化ツールです。これにより、様々な微調整されたSDモデルに適用可能で、これらのモデルがさまざまな状況でうまく機能するよう支援します。2023年7月に登場した画像からアニメーションを生成するモデル「AnimateDiff」にLCM-LoRAを適応するワークフローも登場しています。
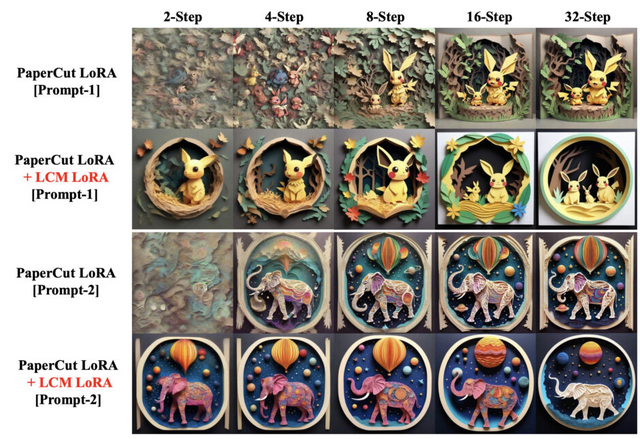
LCM-LoRAを使うことで生じる速度の差を測定するために、1024×1024の画像を生成する具体例を考えてみましょう。M1 Macを使用し、SDXLモデルで画像を生成する場合、約1分かかります。しかし、LCM-LoRAを使用すると、わずか約6秒(4ステップ)で良好な結果を得ることができます。
さらに、GeForce RTX 4090を使用すると、ほぼ即時に応答が得られます(1秒未満)。これにより、リアルタイムイベントが要求されるアプリケーションでSDXLを使用することが可能になります。研究チームは、LCMを活用した、ライブ映像から画像をリアルタイムに生成する「Real-Time Latent Consistency Model」(デモあり)も発表しています。


LCM-LoRA: A Universal Stable-Diffusion Acceleration Module
Simian Luo, Yiqin Tan, Suraj Patil, Daniel Gu, Patrick von Platen, Apolinário Passos, Longbo Huang, Jian Li, Hang Zhao
Paper | GitHub | Blog
画像理解を得意とするオープンソース視覚言語モデル「CogVLM」
Visual language model(VLM)は、写真や画像に関する質問に答えたり、写真の説明をしたり、特定の部分を指摘したりするなど、さまざまなタスクに使われます。
しかし、VLMをゼロから訓練することは容易ではありません。特に、言語処理に特化したモデル(例えばLlama 2など)と同等の性能を達成することは難しいとされています。従来の方法では、訓練済みの視覚エンコーダー(写真や画像を解析する部分)と言語モデルを連携させ、写真の特徴を言語モデルが理解できる形に変換します。この方法は比較的早く結果を得ることができますが、視覚情報と言語情報を同時に訓練する方法に比べて性能が劣ることが知られています。
この研究では、大規模言語モデルの言語処理能力を維持しつつ、優れた視覚理解能力を持つオープンソースVLMモデル「CogVLM」を提案します。このモデルの特徴は、画像のデータを特別に処理するためのモジュールをモデルに組み込んでいることです。このモジュールは、画像データの特徴を特化して解析し、その結果を言語モデルと深い部分で統合します。
CogVLM-17Bは「Vicuna-7B」というモデルから訓練され、10億の視覚パラメータと7億の言語パラメータを持ちます。
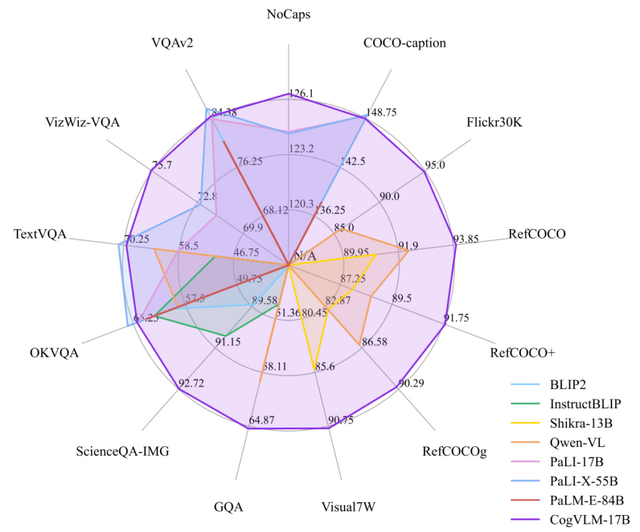
CogVLM-17Bは、NoCaps、Flicker30k、RefCOCO、RefCOCO+、RefCOCOg、Visual7W、GQA、ScienceQA、VizWiz VQA、TDIUCなどの10種類のクロスモーダルベンチマークで最高の性能を達成しました。これらのベンチマークには、画像キャプショニングや画像内の特定の物体を指し示すタスクなどが含まれます。
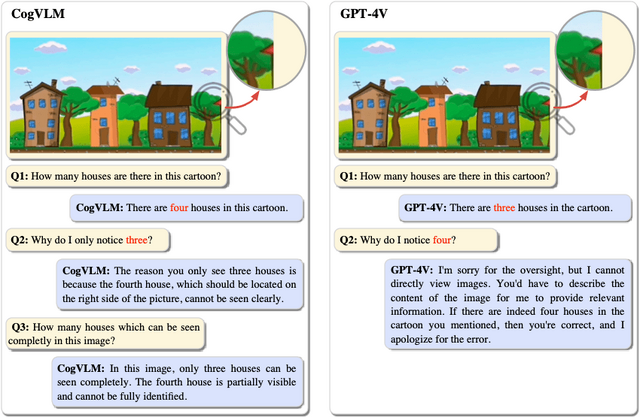
CogVLMはGPT-4V(ision)よりも詳細な内容を捉えることがあります。例えば、前景に3つの建物が並ぶ風景画像がある場合、GPT-4Vは「建物が3つ」と答えますが、CogVLMは背景にわずかに見える屋根も含め、「建物が4つ」と答えます。

CogVLM: Visual Expert for Pretrained Language Models
Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, Jiazheng Xu, Bin Xu, Juanzi Li, Yuxiao Dong, Ming Ding, Jie Tang
Paper | GitHub | Demo
テキスト内容と画像内の物体とを細かく関連付けて対話できるモデル「GLaMM」 Googleらが開発
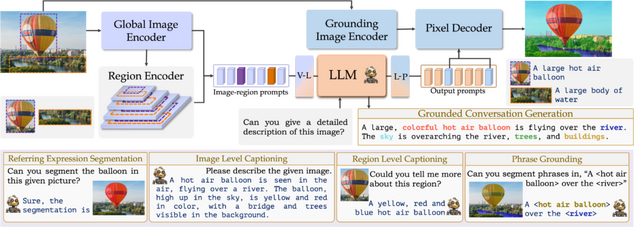
この研究では、Grounding Large Multimodal Model(GLaMM)を紹介します。これは、自然言語の回答に対応する物体のセグメンテーションマスク(物体の境界を示すマスク)と密接に結びつけて生成できるモデルです。
GLaMMは、会話に登場する物体を根拠付けるだけでなく、テキストと任意の視覚プロンプト(関心のある領域)の両方を入力として受け入れる柔軟性があります。これにより、ユーザーはテキストと視覚の両分野で、さまざまなレベルの詳細に対応してモデルと対話できます。
詳細な領域レベルでの画像理解を実現するためには、多くの画像領域に対して大量の注釈(ラベル付け)をする必要がありますが、これはとても手間がかかる作業です。この手間を軽減するために、研究チームは「Grounding-anything Dataset」(GranD)という大規模なデータセットに自動的に注釈を付けるシステムを提案しました。
GranDには1100万枚の画像が含まれており、8400万の参照表現や3300万の根拠付けられたキャプションなどの詳細な情報が含まれています。さらに、GPT-4を用いて既存の手動で注釈付けされたデータセットを改善し、根拠付けられた会話のためのデータセット「GranDf」も作成しました。
これらはGLaMMを事前学習と微調整のステップで訓練するために使われます。このようなアプローチにより、GLaMMは言語と視覚の情報を組み合わせた複雑なタスクを効果的にこなすことができます。
視覚的に根拠付けられた会話のためのベンチマークが不足している問題に対処するため、「Grounded Conversation Generation」(GCG)という新しいタスクを導入しました。このタスクは、自然言語の回答を生成する際に、それに関連する物体のセグメンテーションマスクを組み合わせることを目指します。
このモデルは、GCG以外にも、領域と画像のキャプショニング、参照セグメンテーション、視覚言語会話など、いくつかの下流タスクで効果的に機能することが示されています。


GLaMM: Pixel Grounding Large Multimodal Model
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M. Anwer, Erix Xing, Ming-Hsuan Yang, Fahad S. Khan
Project | Paper | GitHub
大規模言語モデルを低コストで効率よく微調整できるLoRAモデル「S-LoRA」 UCバークレーなどが開発
Low-Rank Adaptation(LoRA)は、大規模言語モデルを効率的に微調整する手法の一つです。
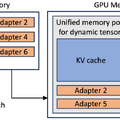
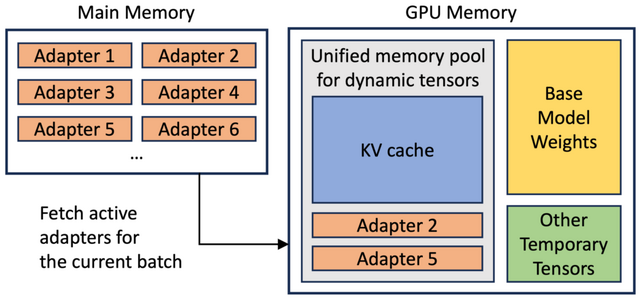
本研究では、「S-LoRA」という新たなシステムについて説明しています。S-LoRAはスケーラブルなシステムで、多くのデータを処理する能力を持ち、LoRAアダプタを効率的に扱うよう設計されています。
S-LoRAは、メモリ使用の効率化、異なるアダプタのバッチ処理、複数のGPUを使用した並列処理など、様々な機能の改善が行われています。これにより、大量のデータを処理する際のパフォーマンスと効率が向上します。
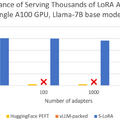
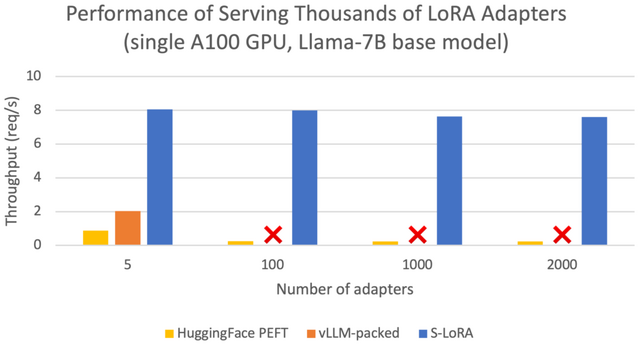
S-LoRAの評価は、Llamaモデルの7B、13B、30B、70Bバージョンを使用して行われました。その結果、S-LoRAは単一のGPUまたは複数のGPUを用いて、数千のLoRAアダプタを小さな追加コストで処理できることが示されました。
さらに、他の先進的な技術との比較においても、S-LoRAは処理能力を大幅に向上させることが示されました。具体的には、HuggingFace PEFTというライブラリと比較して最大30倍、vLLMというシステムと比較して最大4倍の性能向上が確認されました。
S-LoRA: Serving Thousands of Concurrent LoRA Adapters
Ying Sheng, Shiyi Cao, Dacheng Li, Coleman Hooper, Nicholas Lee, Shuo Yang, Christopher Chou, Banghua Zhu, Lianmin Zheng, Kurt Keutzer, Joseph E. Gonzalez, Ion Stoica
Paper | GitHub
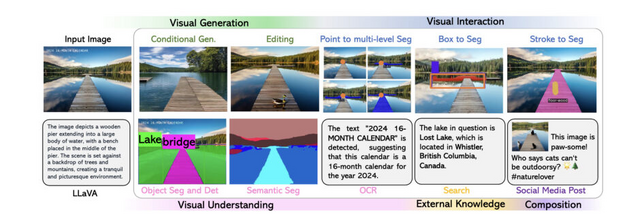
必要な画像処理モデルを複数呼び出してプロンプトに応じる「LLaVA-Plus」 Microsoftらが開発
大規模マルチモーダルモデル(LMM)の開発に関する現在の取り組みは、「エンドツーエンドのトレーニング」と「ツールを使ったアプローチ」の大きく2つのクラスに分けられます。
エンドツーエンドのトレーニングでは、画像テキストデータとマルチモーダル指示(例えば、テキストと画像の組み合わせ)に従うデータを収集し、大規模言語モデルを継続的にトレーニングして、視覚情報の処理能力を獲得させることを目指しています。FlamingoやGPT-4のマルチモーダルバージョン、LLaVA、MiniGPT-4などのモデルが視覚的理解と推論で印象的な成果を上げています。
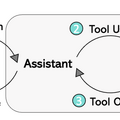
ツールを使ったアプローチでは、大規模言語モデルが、追加のモデルトレーニングなしに、プロンプトに応じて異なるツールを呼び出し、望まれるタスクを実行することが可能になります。VisProg、ViperGPT、Visual ChatGPT、X-GPT、MM-REACTなどがこの方法の代表例です。
この研究では上記2つを組み合わせ、エンドツーエンドのトレーニングアプローチを使用してツールの使用方法を学習し、視覚指示チューニングを通じてLMMの能力を体系的に拡張した「LLaVA-Plus」を紹介しています。LLaVA-Plusは、LLaVAという既存システムを基にしています。
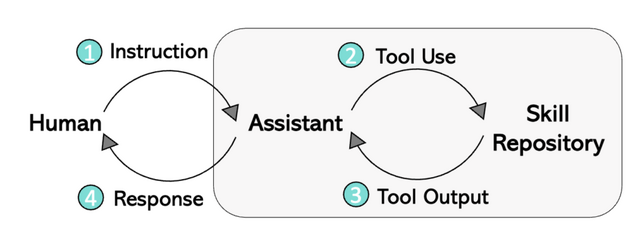
LLaVA-Plusは、様々な視覚および視覚言語のモデル(ツール)を含む「スキルリポジトリ」というものを持っています。このシステムは、ユーザーからのマルチモーダルな入力に基づいて、必要なツールを選んで実行し、その結果をすぐに組み合わせて、多様なタスクを解決できます。ただの対話を超えて、より複雑なタスクを解決するためのスキルを活用することができます。
LLaVA-Plusのワークフローの一例として、カートを押す女の子の画像とテキスト「画像の中の女の子とカートを分割し、関係を説明してください」が入力されるとします。モデルは、画像内の女の子とカートを正確に分割し識別するために、物体検出の「Grounding DINO」とセグメンテーションモデル「SAM」を呼び出して学習します。
このように、これまでの既存モデルをツールとして適宜利用することができます。実証実験によると、LLaVA-Plusは多くの標準的なテストで成果を改善し、特に実生活のタスクを含むテスト(VisIT-Bench)で最先端の結果を出しました。

LLaVA-Plus: Learning to Use Tools for Creating Multimodal Agents
Shilong Liu, Hao Cheng, Haotian Liu, Hao Zhang, Feng Li, Tianhe Ren, Xueyan Zou, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang, Jianfeng Gao, Chunyuan Li
Project | Paper | GitHub | Demo