


1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。2024年初っ端の第27回目は、「礼儀は不要」「モデルに質問させる」「良い解答には報酬」など、大規模言語モデルの返答が向上する「プロンプト26の原則」をはじめとする5つの論文をお届けします。
生成AI論文ピックアップ
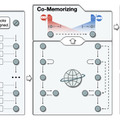
複数の自律AIエージェントが過去の経験を共有して未知のタスクを処理するモデル「Experiential Co-Learning」>
大規模言語モデルの返答が向上する「プロンプト26の原則」が公開。「礼儀は不要」「モデルに質問させる」「良い解答には報酬」など
複数の自律AIエージェントが過去の経験を共有して未知のタスクを処理するモデル「Experiential Co-Learning」
この研究は、大規模言語モデル(LLM)に基づく自律エージェントの進化に焦点を当てており、これらのエージェントが単独で、または人間の介入なしでさまざまなタスクを処理する能力を持つことを示しています。ただし、これまでのエージェントは過去の経験を活用してタスクを効果的に解決することに一定の制限があるという問題がありました。
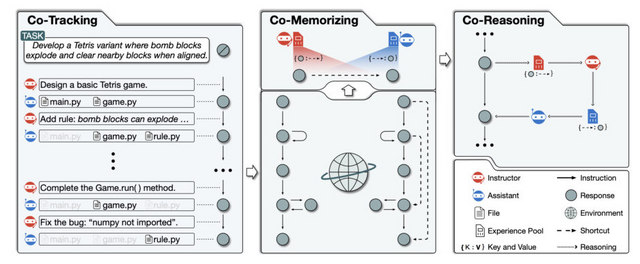
この問題を解決するために、研究者らは「Experiential Co-Learning」という新しいフレームワークを提案しています。このフレームワークでは、複数のエージェント(指導者とアシスタントの役割を持つ)が協力して、過去のタスクから得た経験や知識を活用し、未知のタスクに対応します。これにより、エージェントは過去の経験を共有し、相互に推論を行いながら、より効果的にタスクに取り組むことが可能になります。
この研究では、ソフトウェア開発を具体的な適用例として取り上げ、エージェントが自然言語とプログラミング言語のスキルを組み合わせて複雑なタスクに対応する方法を詳しく説明しています。また、複数のエージェントが協力することで、ソフトウェア開発の効率が向上し、人間の介入が減少することも示されています。
他の既存のモデル(GPT-Engineer、MetaGPT、ChatDev)と比較して、このモデルは独立性、ソフトウェアの完全性、実行可能性、および整合性において高いパフォーマンスを示しました。これは、エージェントが過去の経験を活用してより効率的に未知のタスクを処理できることを示しています。
Experiential Co-Learning of Software-Developing Agents
Chen Qian, Yufan Dang, Jiahao Li, Wei Liu, Weize Chen, Cheng Yang, Zhiyuan Liu, Maosong Sun
Paper
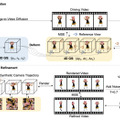
画像から動く3Dシーンを生成する新モデル「DreamGaussian4D」
近年、4D(3次元の空間に時間の次元を加えた)コンテンツの生成技術が大きく進歩していますが、従来の方法では最適化に時間がかかりすぎる、動きのコントロールが難しい、詳細度が低いという問題がありました。
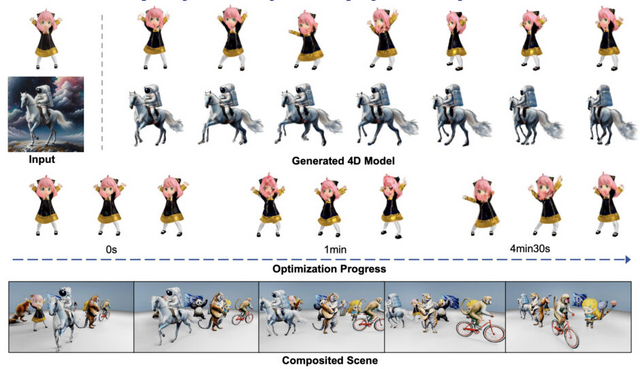
この研究では、入力画像を基にして動的な3Dシーンを生成するための4D生成フレームワーク「DreamGaussian4D」を紹介しています。DreamGaussian4Dは、最適化時間を数時間から数分に短縮し、生成される動きのコントロールを向上させ、高品質なアニメーションメッシュを効率的に生成することができます。
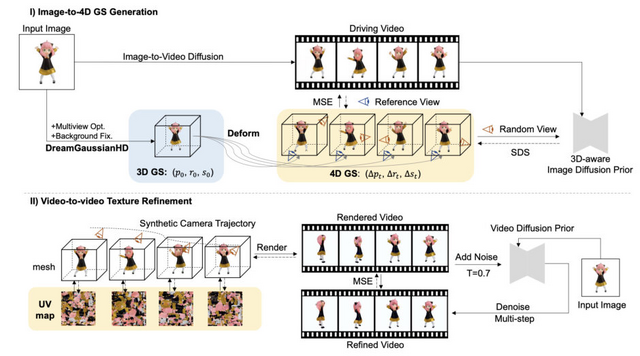
DreamGaussian4Dは、3つの段階から成り立っています。初期段階の静的生成では、入力画像から3Dガウス分布を作成するために、元のDreamGaussianを改良したバージョンを使用します。このプロセスでは、画像を基にして、3D空間における物体や形状をガウス分布を使って表現します。これにより、静的な3Dモデルが生成されます。
第2段階の動的生成では、入力画像から生成した駆動ビデオを利用して、静的な3Dガウス分布に時間依存の変形フィールドを最適化します。これにより、静的モデルに動きや変化を加え、動的な4Dコンテンツを作成します。ここでの動的とは、時間の経過とともに変化することを意味しています。
最終段階では、4Dガウス分布をアニメーションメッシュシーケンスに変換し、ビデオからビデオへのパイプラインを適用して、テクスチャマップを一貫して洗練します。この段階で、生成された4Dコンテンツはさらに高品質なアニメーションメッシュに変換され、テクスチャの質も向上します。



DreamGaussian4D: Generative 4D Gaussian Splatting
Jiawei Ren, Liang Pan, Jiaxiang Tang, Chi Zhang, Ang Cao, Gang Zeng, Ziwei Liu
Project | Paper | GitHub
大規模言語モデルの返答が向上する「プロンプト26の原則」が公開。「礼儀は不要」「モデルに質問させる」「良い解答には報酬」など
大規模言語モデル(LLM)における、最適なプロンプトの設計には一定の技術が必要です。この研究では、LLMに対する26の原則が導入され、これらの原則を利用することで、LLMからの応答の品質と正確さが大幅に向上することが示されています。
実験は、LLaMA-1/2、GPT-3.5/4といったさまざまなモデルで行われました。これらの原則を適用することで、LLMの応答の正確性が平均して、小規模および中規模モデルで20%~30%、大規模モデルでは50%以上の改善が見られました。
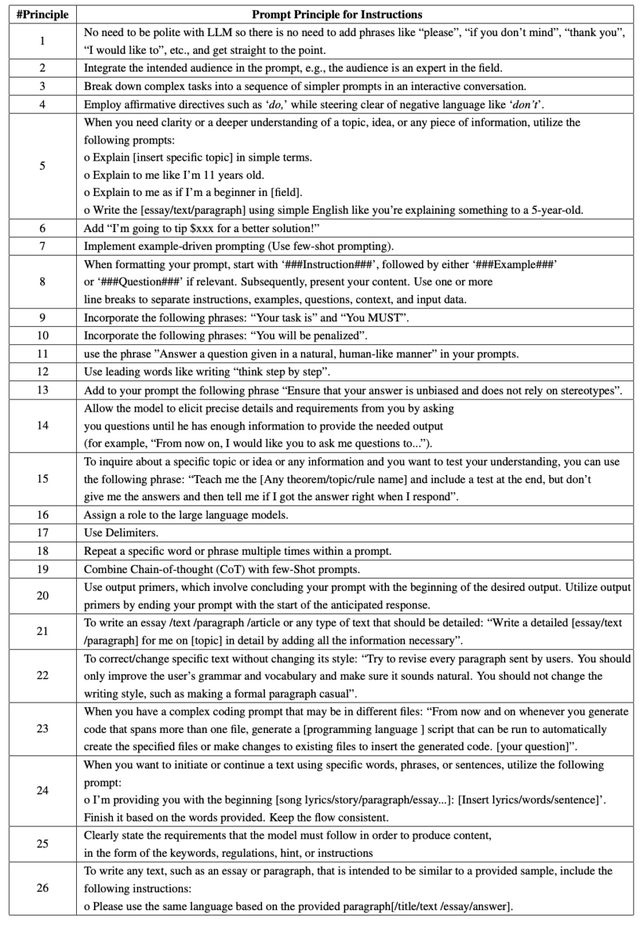
以下、26の原則を簡潔にまとめました。
礼儀を省く:「お願いします」などの礼儀用語は不要。
対象者を明示:「専門家向け」など、返答を受け取る対象者をプロンプトに明示。
複雑なタスクの分割:複雑なタスクを簡単なプロンプトに分ける。
肯定的指示の使用:否定的な言葉ではなく肯定的な言葉を使用。
明確化のための指示:「簡単な言葉で説明して」「中学生にも分かるように説明して」など。
報酬の提示:「良い解答には報酬を出す」と示す。
事例を提示:既存の事例を使用。
プロンプトのフォーマット:「###Instruction###」で始め、適宜「###Example###」や「###Question###」を含める。
明確なタスク指示:「あなたのタスクは」と指示。
ペナルティの提示:「ペナルティあり」と伝える。
自然言語による回答指示:「自然言語で回答して」と指示。
先導的な言葉の使用:「ステップバイステップで考えて」と指示。
偏見の排除:「偏見を持たず、ステレオタイプに依存しない」と指示。
ユーザーとの対話促進:問題解決までモデルに質問させる。
テストを含む指導:テストを出してもらい、自分の理解度を試す。
モデルへの役割割り当て:モデルに特定の役割を割り当てる。
デリミターの使用:特定の区切り文字を使用。
繰り返しの使用:特定の単語やフレーズを複数回使用。
思考の連鎖:中間ステップを生成し、事例を組み合わせる。
出力プライマーの使用:期待される出力の始まりでプロンプトを終える。
詳細なテキストの作成指示:「詳細に書いて」と指示。
スタイル変更の防止:「スタイルを変更しない」と指示。
複数ファイル対応のコーディングプロンプト:複数のファイルにまたがるコーディング作業の効率化のために、自動的に新しいファイルを作成し、生成されたコードを適切なファイルに挿入するスクリプトを作成することを提案。
特定の言葉でテキストを続ける:「与えられた言葉で完成させて」と指示。
モデルの要件の明示:コンテンツを制作するためにモデルが守らなければならない要件を、キーワード、規定、ヒント、指示などの形で明示。
サンプルに基づくテキスト作成:提供されたサンプルに基づいて同じ言語で書くよう指示。

Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4
Sondos Mahmoud Bsharat, Aidar Myrzakhan, Zhiqiang Shen
Paper | GitHub
220以上の生成タスクが実行できる大規模なマルチモーダルモデル「Unified-IO 2」
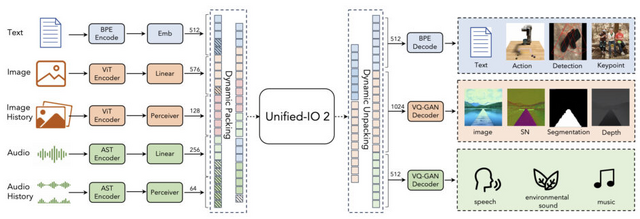
異なるモダリティ(視覚、言語、音声、アクション)を統合し、これらのデータから学習して出力を生成できる大規模なマルチモーダルモデル「Unified-IO 2」に関する研究です。このモデルは、画像、テキスト、音声、ビデオ、さまざまなインターリーブされたシーケンスを処理し、テキスト、アクション、音声、画像、密度の高いラベル、または疎なラベルを出力することができます。
Unified-IO 2は、7億のパラメータを持ち、さまざまなマルチモーダルデータ(10億の画像-テキストペア、1兆のテキストトークン、1億8000万のビデオクリップ、1億3000万のインターリーブされた画像&テキスト、300万の3Dアセット、100万のエージェント軌道)でゼロからトレーニングされています。また、指示チューニングのために120以上のデータセットから成る大規模なマルチモーダルコーパスでファインチューニングを行い、視覚、言語、音声、アクションに関する220以上のタスクを網羅しています。
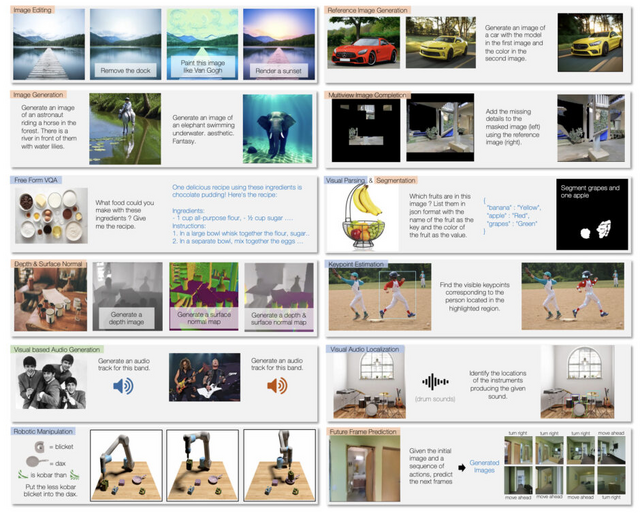
Unified-IO 2のできることには、長いフォームのクエリに対するテキスト回答の生成、画像生成、画像編集、画像へのキャプション付け、画像からの深度推定、表面法線推定、未来のフレーム予測、画像やテキストからの音声生成、ビデオの理解、ビデオへのキャプション付け、ビデオの質問応答、音声のタグ付け、音声へのキャプション付け、キーポイント推定、ロボット操作のアクション予測や未来の状態予測などが含まれます。また、異なるモーダル(例えば、画像とテキスト、または音声とテキスト)を組み合わせた応答の生成も可能です。
このモデルは、GRITベンチマークで最先端の性能を達成し、35以上のベンチマークで優れた結果を示しています。これには、画像生成と理解、自然言語理解、ビデオと音声の理解、ロボット操作などが含まれます。

Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action
Jiasen Lu, Christopher Clark, Sangho Lee, Zichen Zhang, Savya Khosla, Ryan Marten, Derek Hoiem, Aniruddha Kembhavi
Project | Paper | GitHub
画像とテキストからビデオを生成する新モデル「I2V-Adapter」、画像内キャラクターのダンス生成も可能
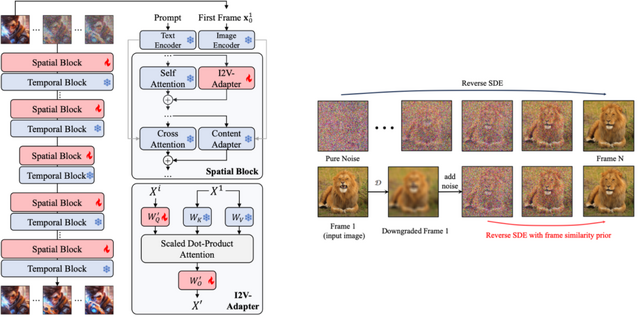
この研究では、静止画像とテキストプロンプトからリアルで動的なビデオシーケンスを生成することができる、軽量で効率的な生成モデル「I2V-Adapter」を紹介しています。
I2V-Adapterは、事前に訓練されたテキストからイメージへのモデルと動きのモジュールをそのまま使用し、これらの能力を画像生成とビデオの時間的モデリングにおいて最適化します。
特に、このアダプターは、Self-Attention層にクロスフレームの注意メカニズムを取り入れています。これにより、ノイズのない最初のフレームとノイズが加えられた後続のフレームとの相互作用が可能になり、入力画像の品質に一致した一貫性と整合性のあるビデオを生成できます。
I2V-Adapterは、多様なコミュニティ開発のテキストからイメージへのモデル(T2I)と互換性があり、ControlNetのような制御ツールや、DreamBoothのようなパーソナライズされた生成モデルとも連携できます。これにより、ユーザーはビデオ生成プロセスをより細かく制御し、カスタマイズされたコンテンツを作成することが可能になります。



I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models
Xun Guo, Mingwu Zheng, Liang Hou, Yuan Gao, Yufan Deng, Chongyang Ma, Weiming Hu, Zhengjun Zha, Haibin Huang, Pengfei Wan, Di Zhang
Project | Paper | GitHub