



1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第24回目はさらに豊作で、生成AI最新論文の概要6つをお届けします。Stable Diffusionベースとした単眼深度推定手法「Marigold」、高品質のビデオを数分間出力できる動画生成モデル「Vchitect」などです。
生成AI論文ピックアップ
写真内の奥行きを推定するStable Diffusionベースの単眼深度推定手法「Marigold」
この研究は、「単眼深度推定」という技術に関するものです。単眼深度推定は、一枚の写真からその場所の奥行きや立体感(深度マップ)を計算する方法です。
単眼深度推定は、モデルの容量が増えるにつれて目覚ましい進歩を遂げています。初期の技術は比較的シンプルなCNN(畳み込みニューラルネットワーク)を使用していましたが、現在はより高度なトランスフォーマー(Transformer)アーキテクチャを用いています。
これらの推定器は、訓練データに基づく視覚世界の理解に依存しているため、未知のコンテンツやレイアウトを持つ画像に対応する際には難しさがあります。特に新しい領域への適応、いわゆるゼロショットはこれらのシステムにとっての課題です。
この研究では、生成的拡散モデルにおける豊富な事前知識を活用して、より優れた深度推定を実現する「Marigold」という新しい手法を提案しています。Marigoldは、Stable Diffusionモデルから派生した単眼深度推定方法で、合成されたRGB-D(色と深度情報を含む)データを用いてデノイジングU-Netを変更し、微調整を行います。このプロセスはGPUを使用して数日間で完了し、リソース効率の高さが特徴です。
Marigoldは、実際の深度マップを見たことがなくても、幅広い画像に対して高い一般化能力を持っています。これは、Stable Diffusionモデルの豊富な画像に対する理解に基づくものです。その結果、Marigoldはさまざまな種類の画像に対して効果的に深度を推定でき、幅広いデータセットにおいて最先端のパフォーマンスを実現しています。特定のケースでは20%以上のパフォーマンス向上も達成しています。


Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, Konrad Schindler
Project | Paper | GitHub | Demo
本物過ぎる動く実写アバターをリアルタイム生成する手法をMetaが開発。毛穴や髪の毛1本まで精密に再現しライティングも変更可能
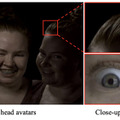
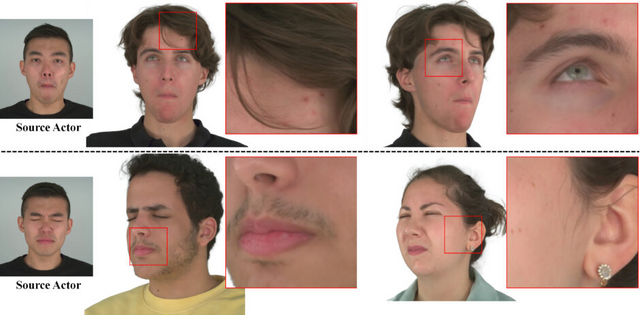
この研究は、リアルタイムで高忠実度のリライト(再照明)可能な写実的頭部アバターの生成に焦点を当てています。このモデルは、人間の頭部の複雑な散乱と反射特性に対応するために、3D Gaussian Splatting技術とリライティング外観モデルを組み合わせています。
3D Gaussian Splattingを使用することで、写実的な頭部アバターの効率的なリアルタイムレンダリングが可能となり、動的な顔のシーケンスで髪の毛一本一本や毛穴など、サブミリメートルレベルの細かい3Dディテールを捉えることができます。
リライティング外観モデルは、肌、髪、目など人間の頭部の様々な素材を一つのモデルで統一的に扱い、リアルタイムで自然な光の反射を実現します。このモデルは、点光源や連続照明の下でもリアルタイムに効率的に再照明することが可能です。また、目の反射の忠実度を向上させるために、視線の制御とリライトが可能な眼モデルを導入しています。
応用面では、VRヘッドセットからの任意の視点でリアルタイムにアバターをレンダリングできます。自然光や人工的な照明下でのリライティングも可能で、これによりVR内でアバターをよりリアルかつ動的に表示し、光の変化に合わせて自然に見せることが可能になります。




Relightable Gaussian Codec Avatars
Shunsuke Saito, Gabriel Schwartz, Tomas Simon, Junxuan Li, Giljoo Nam
Project | Paper
映画品質のビデオを数分間出力できる動画生成モデル「Vchitect」
Vchitectは、テキストからビデオ(T2V)および画像からビデオ(I2V)への変換を目的とした、幅広い用途に適応する汎用ビデオ生成システムです。このシステムは、映画のような視覚品質を持つビデオを生成し、数秒から数分に及ぶ長さのビデオを作成できるとともに、一貫したストーリーテリングとスムーズなカメラの遷移をサポートします。
Vchitectは、多様な機能を備えた5つのモデルから構成されています。各モデルはテキストの説明に基づいて個別に訓練されており、1) 短く低解像度のキーフレームを生成する基本モデル、2) 任意の長さのビデオや2つの異なるビデオ間のスムーズな遷移を生成するモデル、3) 同じ主題の複数のビデオクリップを作成するモデル、4) 短いビデオのフレームレートを高める時間補間モデル、5) 低解像度のビデオから高解像度の結果を合成するモデルが含まれます。
Vchitectの性能向上のため、品質、多様性、美的魅力に重点を置いた2500万組のテキストとビデオを含む大規模データセット「Vimeo25M」が収集されました。
ビデオ生成タスク専用に設計された包括的なベンチマークも提案されており、これに基づいてVchitectは多くの分野で優れた成績を収め、最先端技術と競合する、またはそれを上回る成果を達成しています。



Vchitect: a generalist video generation system for cinematic storytelling
Vchitect Team
Project | Paper | GitHub | Demo
“言語に頼らない”画像理解モデル「Large Vision Model」
大規模言語モデル(LLM)は、GPTやLLaMAなどのモデルを通じて世界中で注目を集めています。これらのモデルはテキストデータを処理し、人間の言語を模倣する能力を持っていることが特徴です。
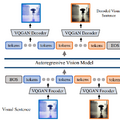
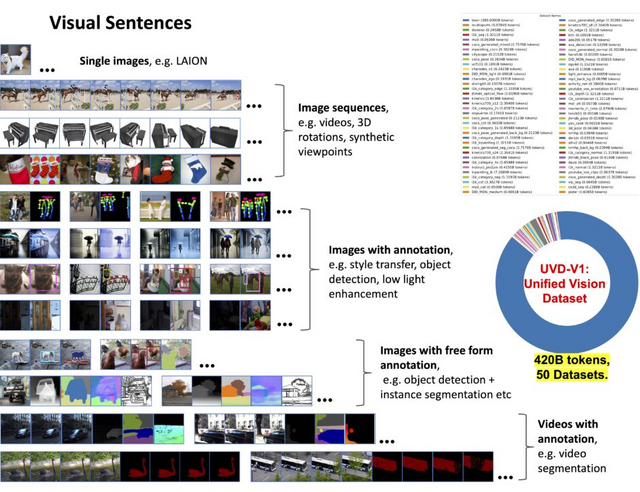
一方、新しいAIモデルである「Large Vision Model」(LVM)は、言語データを使用せずに視覚データから学習することを目的としています。LVMの開発の核となるのは、「Visual Sentences」と呼ばれる方法です。これにより、画像は離散的なトークンのシーケンスとして表現され、コンピュータによる理解が容易な形に変換されます。
LVMの訓練には、1.64億枚の画像を含む大規模なデータセットが使用されています。このデータセットは、ラベルのない画像やビデオ、注釈付きビジュアルデータ、3D合成オブジェクトなど、多様な視覚データを網羅しています。これらのデータはトークン化され、3億のパラメータを持つ自己回帰的トランスフォーマーモデルによって、次のトークンを予測するための訓練が行われます。
LVMはこのプロセスを通じて、画像やビデオを深く理解し、解析する能力を身につけます。特に、アナロジープロンプトという技法を用いて、より複雑なタスクや新しいタスクに対応できることが示されています。
アナロジープロンプトは、モデルが既存のデータやパターンから学び、それを基に新しいシナリオを推論する能力を持つことを前提としています。例えば、複数の画像を提示して、それらが共有する特定の特徴やパターンを理解させ、新しい画像が以前の画像とどのように関連しているかを判断させる場合などがあります。この技法は、モデルがデータを単に記憶するのではなく、概念やパターンを理解し、それを新しい状況に適用する能力を持つことを示しています。
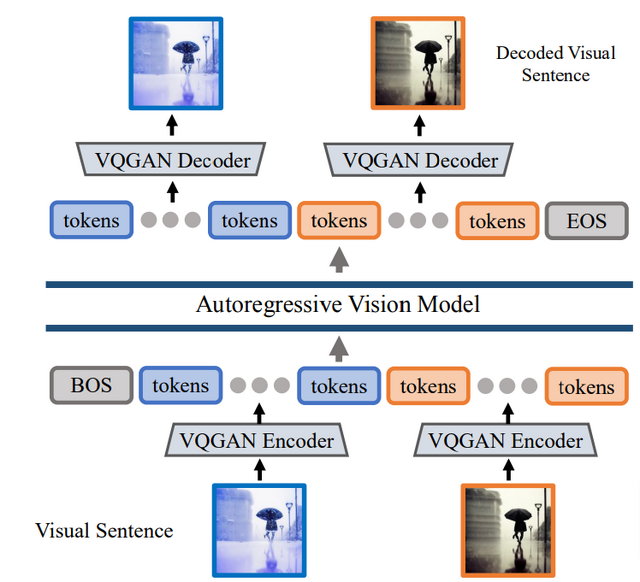


Sequential Modeling Enables Scalable Learning for Large Vision Models
Yutong Bai, Xinyang Geng, Karttikeya Mangalam, Amir Bar, Alan Yuille, Trevor Darrell, Jitendra Malik, Alexei A Efros
Project | Paper | GitHub
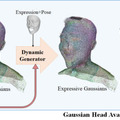
制御可能な写実的な3Dアバターを2Kで生成できるモデル「Gaussian Head Avatar」
この研究では、「Gaussian Head Avatar」という新しい方法を用いて、少ないデータから2K解像度で制御可能な表情を持つ高忠実度のリアルな顔の3Dアバターを作ることについて説明しています。このアバターは、異なる視点から見た際の姿を非常にリアルに再現できると同時に、同じ表情を異なるアイデンティティ(個性や特徴)を持つアバターにアニメーション化することが可能です。
Gaussian Head Avatarは、主に2つの部分から成り立っています。まず、制御可能な3Dガウス関数を使用してアバターの顔の基本的な形を作り出します。次に、多層パーセプトロン(MLP)を使用して、アバターの顔の表情や動きを細かく再現します。これら2つの要素が相互に作用し合うことで、細かい動きのディテールをモデル化しつつ、表情の精度を保ちます。
このプロセスを安定させるためには特定の初期設定手法が使われています。これにより、訓練プロセスが安定し、成功しやすくなります。この技術により、少ないデータからでも非常にリアルで細かい動きを持つ3Dの顔のアバターを作成することが可能で、他の方法よりも優れた結果を出しています。特に、大げさな表情でも高解像度(2K)で非常に高い品質のアバターを作成できる点が特筆されます。
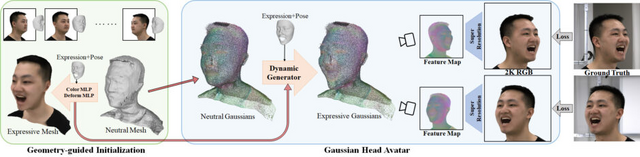

Gaussian Head Avatar: Ultra High-fidelity Head Avatar via Dynamic Gaussians
Yuelang Xu, Benwang Chen, Zhe Li, Hongwen Zhang, Lizhen Wang, Zerong Zheng, Yebin Liu
Project | Paper | GitHub
一貫したスタイルで出力する画像生成AI「StyleAligned」。Googleの研究者らが開発
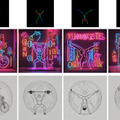
テキストから画像を生成するT2Iモデルは、その視覚的に魅力的な画像生成能力で、アートやデザインなどの創造的な分野で急速に注目を集めています。しかし、これらのモデルで一貫したスタイルを維持することは困難であり、既存の方法では細かな調整や手動介入が必要で、内容とスタイルを分離することが難しいという問題がありました。
この課題に対処するため、「StyleAligned」という新しい技術が開発されました。この技術は、生成される一連の画像間でスタイルの整合性を確立することを目的としています。
特に、拡散プロセス中に「Attention Sharing」という技術を使用します。これにより、モデルが生成する各画像間でスタイルが一貫していることを保証します。この技術により、参照スタイルを用いてスタイルが一貫した画像を簡単な反転操作を通じて作成することが可能になります。
多様なスタイルとテキストプロンプトを用いた評価では、この方法が高品質な合成と忠実さを実現し、様々な入力にわたって一貫したスタイルを達成していることが示されました。







Style Aligned Image Generation via Shared Attention
Amir Hertz, Andrey Voynov, Shlomi Fruchter, Daniel Cohen-Or
Project | Paper | GitHub













