




1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第26回目は、生成AI最新論文の概要5つをお届けします。画像生成の高速化技術を大幅に向上させた、日本人著者らによる「StreamDiffusion」をはじめとした最新論文を紹介します。
生成AI論文ピックアップ
複数の動く3Dオブジェクトをテキスト指示で作成する4D生成モデル「AYG」、NVIDIAなどが開発
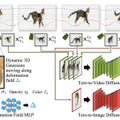
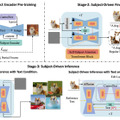
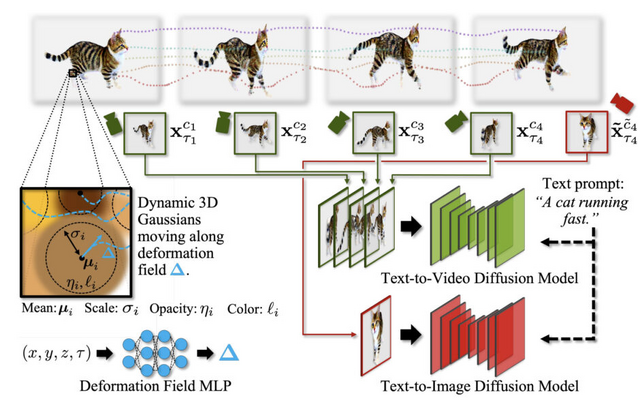
「Align Your Gaussians」(AYG)は、NVIDIAなどに所属する研究者らによって開発された、テキストから4D(時間を含む3次元)への変換を目的とする新しい手法です。AYGは、動的な3D Gaussian SplattingとDeformation Field、そして拡散モデルを組み合わせたスコア蒸留ベースの合成フレームワークに基づいています。
この手法では、まず初期の高品質な3D形状を生成するために、3D対応のマルチビュー拡散モデルとText-to-Image生成モデルを使用します。次に、Text-to-Image生成モデルとText-to-Movie生成モデルを組み合わせて、時間的ダイナミクスを捉えるDeformation Fieldを最適化し、全ての時間フレームで高い視覚品質を維持します。
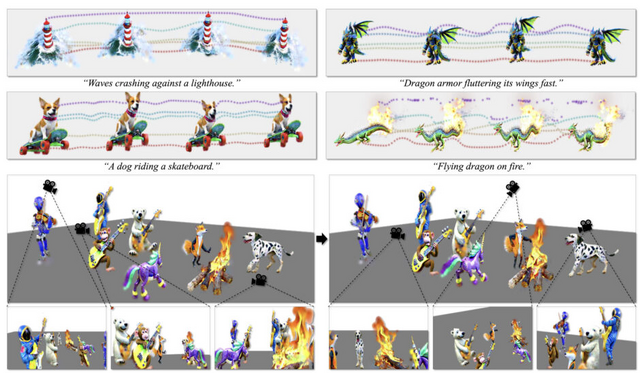
AYGは、テキストから4Dへの最先端のパフォーマンスを実現し、時間的に一貫性があり、高品質な視覚的外観を持つ動的3Dオブジェクトを生成します。さらに、これまでにない規模の大きなシーンで複数の動的オブジェクトを組み合わせることにも成功しています。

Align Your Gaussians: Text-to-4D with Dynamic 3D Gaussians and Composed Diffusion Models
Huan Ling, Seung Wook Kim, Antonio Torralba, Sanja Fidler, Karsten Kreis
Project | Paper
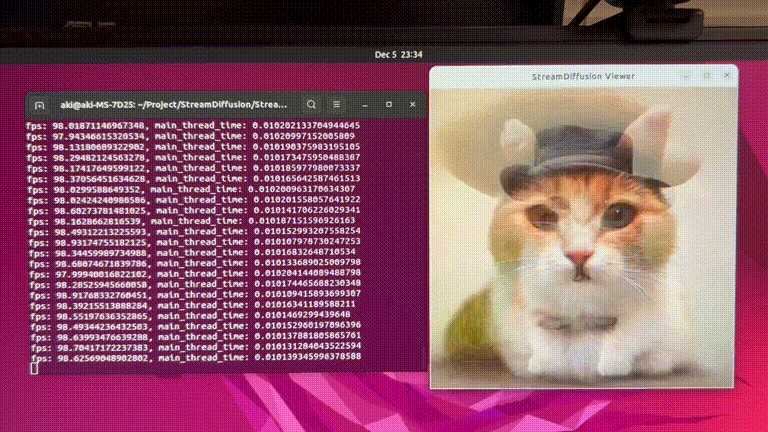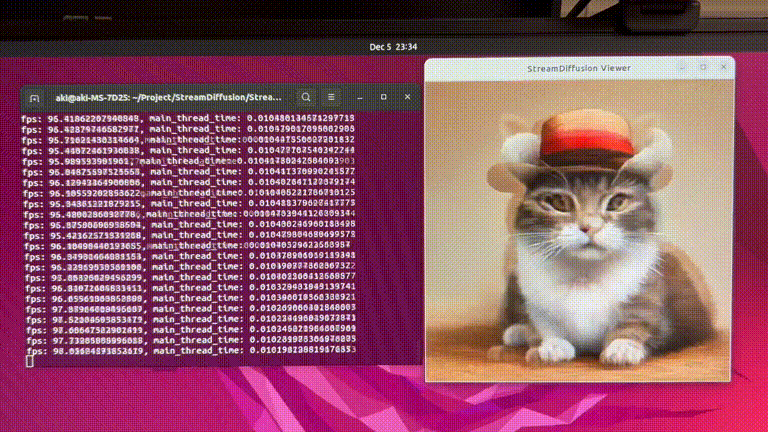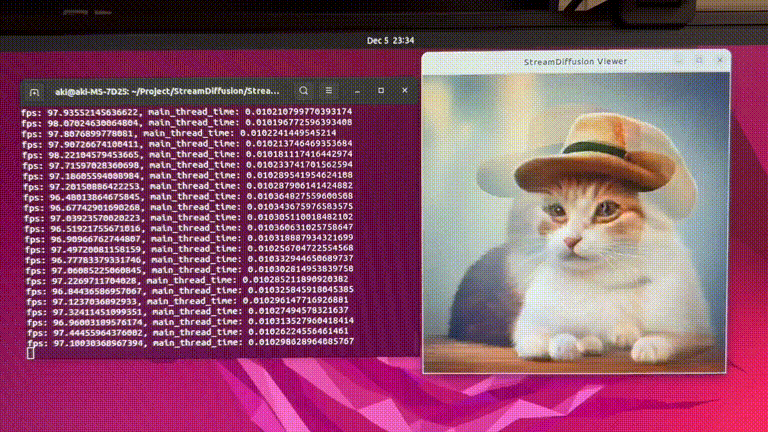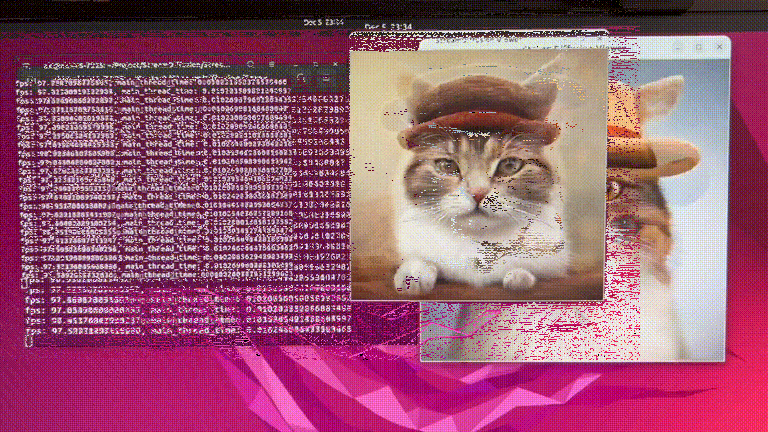
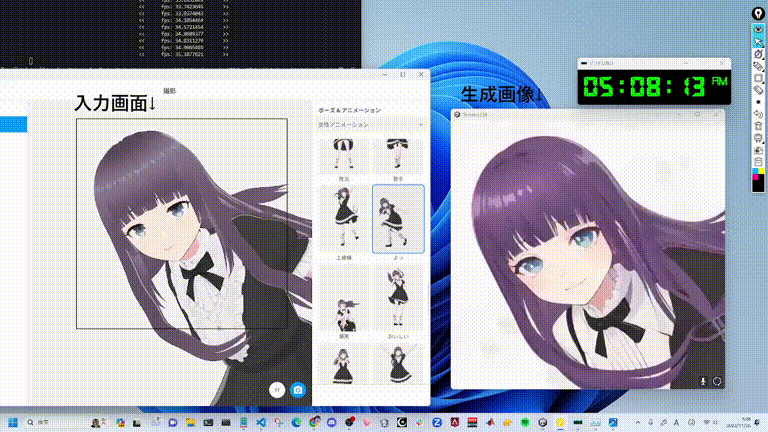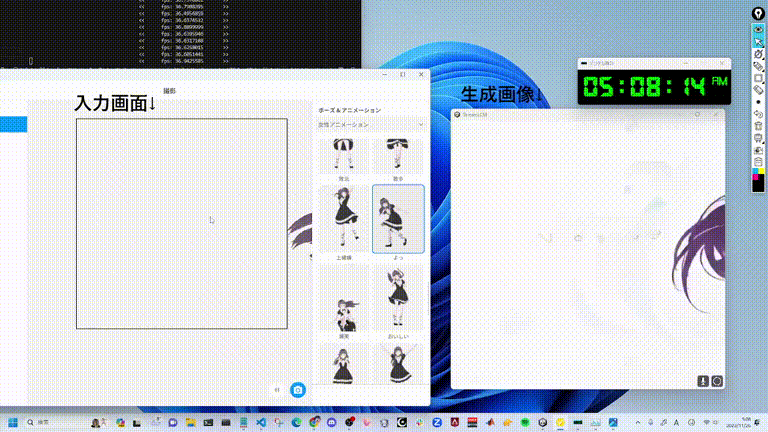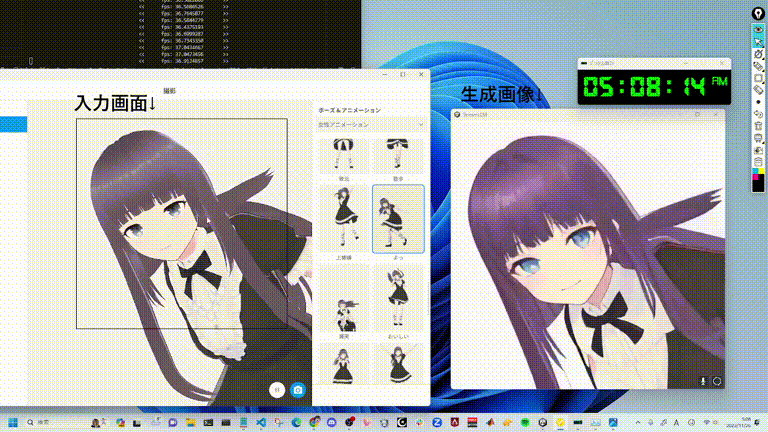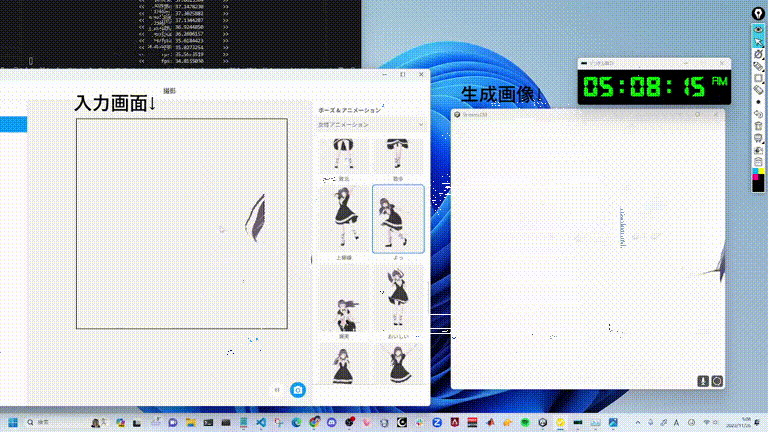
SD-turboで毎秒100枚以上の画像を生成できるシステム「StreamDiffusion」。著者による解説動画あり
StreamDiffusionはリアルタイム画像生成を実現するために最適化された新しい技術です。これには、スループットとGPU使用効率を高めるための複数の最適化戦略が含まれています。
具体的には、バッチ処理によるデータ処理効率を向上させる「Stream Batch」、計算の冗長性を最小限に抑える「RCFG」(Residual Classifier-Free Guidance)、類似度によるフィルタリングでGPUの使用効率を最大化する「Stochastic Similarity Filter」、入出力操作を効率的に管理してよりスムーズな実行を実現する「IO Queues」、高速処理のためのキャッシュ戦略を最適化する「Pre-Computation for KV-Caches」、モデルの最適化とパフォーマンス向上のための様々なツールを利用する「Model Acceleration Tools」が含まれます。
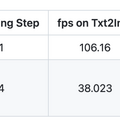
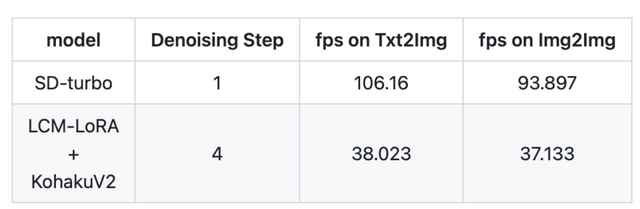
これらの要素を組み合わせることで、効率が大幅に向上します。特に、GPUがRTX 4090、CPUがCore i9-13900K、OSがUbuntu 22.04.3 LTSで、StreamDiffusion-turboを用いたテキストプロンプトから画像を生成するタスクにおいて、106フレーム毎秒(fps)のパフォーマンスを達成しました。また、LCM-LoRAとKohakuV2を組み合わせたモデルを用いた場合には、画像から画像生成タスクにおいて38fpsを達成しました。
この顕著な効率の向上は、リアルタイムの画像生成が必要な用途にとって大きな進歩であり、メタバース、オンラインビデオストリーミング、放送業界など、さまざまなアプリケーションに有益と言えます。
論文著者による使い方講座もYouTubeで公開されています。

StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation
Akio Kodaira, Chenfeng Xu, Toshiki Hazama, Takanori Yoshimoto, Kohei Ohno, Shogo Mitsuhori, Soichi Sugano, Hanying Cho, Zhijian Liu, Kurt Keutzer
Paper | GitHub | Demo
細部まで一貫性のある被写体主導の画像・動画を生成できるモデル「DreamTuner」、ByteDanceが開発
拡散ベースのモデルは、テキストから画像を生成する分野で印象的な能力を示しています。特に、個人のニーズに合わせてカスタマイズされた画像を、参照画像を使って生成することに期待が寄せられています。しかし、これまでの方法では、被写体(対象物)の特徴を学習することと、既存の生成モデルの能力を維持することのバランスをとるのが難しいという問題がありました。また、画像エンコーダを追加する方法は、圧縮の過程で重要な被写体の詳細を失うことがあります。
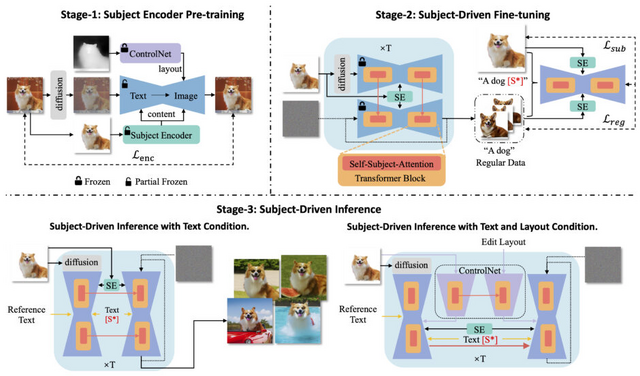
これらの問題に対処するため、「DreamTuner」という新しい方法が提案されています。DreamTurnerは、1枚の参照画像のみを使用し、テキスト指示やポーズ指示で被写体主導の画像を生成する能力を持ちます。これまでよりも一貫性が高く破綻が少ないのが魅力で、特にポーズや表情などの細部の変更で顕著に向上しています。
また1枚の参照画像とボーン動画を組み合わせることで、画像内のキャラクターを高忠実度にアニメーション化することもできます。こちらも一貫性が高く、滑らかな映像に仕上がります。
DreamTunerは被写体の情報を粗いものから細かいものへと段階的に取り入れ、「Subject Encoder」を使用して被写体の大まかな特徴を保持し、「Self-Subject-Attention Layers」によって対象被写体の詳細を精緻化します。この方法により、高忠実度の画像生成が可能になります。
最終的に、DreamTunerは被写体主導のファインチューニングを加えることで、被写体主導の画像生成において顕著な成果を達成し、テキストやポーズなどの条件で制御可能になります。例えば、ControlNetと組み合わせることで、ポーズなどの様々な条件への適用性を拡大することができます。



DreamTuner: Single Image is Enough for Subject-Driven Generation
Miao Hua, Jiawei Liu, Fei Ding, Wei Liu, Jie Wu, Qian He
Project | Paper
人間が使うようにタップやスワイプでスマホアプリを操作できるAI「AppAgent」。テンセントが技術開発
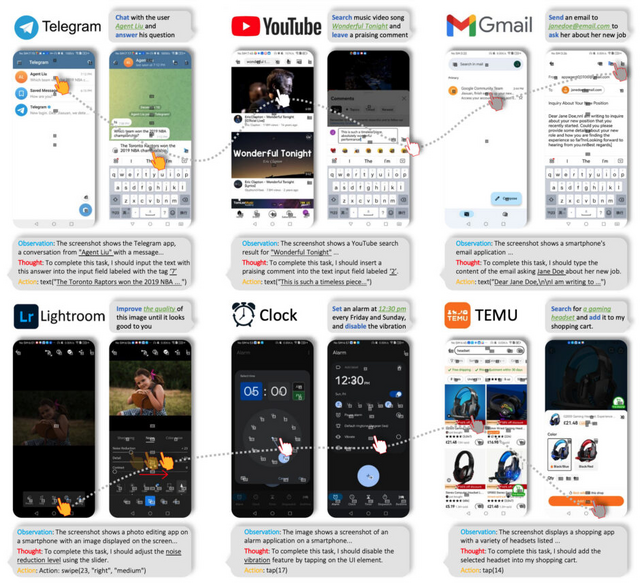
この研究では、エージェントがタップやスワイプなどの人間のようなインタラクションを模倣して、スマートフォンアプリを操作することができる、大規模言語モデルベースのマルチモーダルエージェントフレームワークを紹介しています。
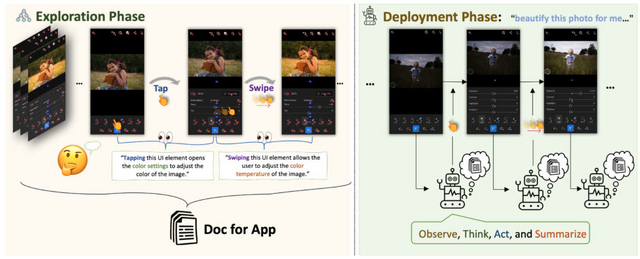
このフレームワークは2段階アプローチで構成されています。探索フェーズでは、エージェントが自律的な相互作用を通じて、または人間のデモンストレーションを観察することによって、スマートフォンアプリとのやり取りを学びます。その結果、包括的な参照文書が作成されます。展開フェーズでは、エージェントはこの文書にまとめられた情報を利用して、アプリを効果的に操作しナビゲートします。
このフレームワークの実用性を示すために、GPT-4を使用して、ソーシャルメディア、メール、地図、ショッピング、高度な画像編集ツールなど、10種類のアプリケーションで50のタスクにわたる広範なテストを行いました。
具体的な例としては、Google Mapsでのナビゲーションタスクや、Gmailでの電子メールの管理と分類、Lightroomを使用した画像編集タスクなどが含まれます。これらの実験では、提案されたエージェントが高レベルのタスクの多様な配列を効果的に扱う能力を持つことが示されました。
AppAgent: Multimodal Agents as Smartphone Users
Zhao Yang, Jiaxuan Liu, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, Gang Yu
Project | Paper | GitHub | Demo
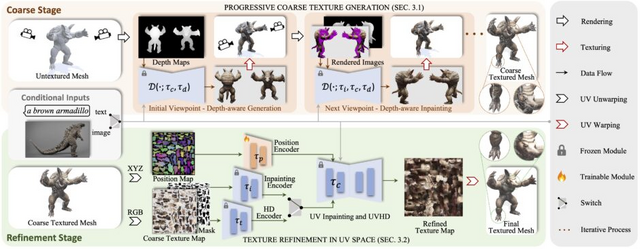
3Dモデルのテクスチャを文章や画像から生成するモデル「Paint3D」、テンセントなどが技術開発
この研究では、新しいテクスチャ生成フレームワーク「Paint3D」を紹介しています。Paint3Dは、テキストや画像を入力として使用し、3Dモデルのための高解像度テクスチャを生成できます。これらのテクスチャは照明の影響を受けないため、後から照明を変更したり加工したりしやすいのが特徴です。
Paint3Dは粗から細への2段階プロセスを採用しています。初めに、事前に訓練された2D画像拡散モデルから多視点画像を生成し、これらを3Dメッシュの表面に逆投影して初期のテクスチャマップを作成します。次に、UVインペインティングとUVHD拡散モデルを使用して、テクスチャマップを洗練し、照明の影響を取り除きます。
これにより、照明の影響を受けない、意味的に一貫したテクスチャが生成されます。実験結果では、Paint3Dは既存の最先端技術と比較して、テクスチャ生成の品質と多様性において優れた性能を示しました。
特に、テキストと画像からのテクスチャ生成では、Frechet Inception Distance (FID) と Kernel Inception Distance (KID) において最高のスコアを達成しました。これらの結果から、Paint3Dは3Dオブジェクトのテクスチャ生成において高い品質と多様性を実現していることが分かります。


Paint3D: Paint Anything 3D with Lighting-Less Texture Diffusion Models
Xianfang Zeng, Xin Chen, Zhongqi Qi, Wen Liu, Zibo Zhao, Zhibin Wang, BIN FU, Yong Liu, Gang Yu
Paper | GitHub