AI自動作曲サービスの「Suno」を使って1曲作って記事にしましたが、ミュージシャンの方々からの反応も寄せられてきています。
制作マニュアルはこちら。


脅威に感じたり、まだまだ不足している部分を指摘する一方で、「こういう使い方なら効率がすごく上がる」といったポジティブなアイデアが次々と生まれていて、さすがシンセサイザー、サンプリング、物理モデリング、ループベース制作、VOCALOIDといった破壊的技術をいくつもくぐりぬけてきただけのことはあります。
前回はSunoが作ったものをそのまま公開したのですが、全体的な完成度は相当に高いとはいえ、不満なポイントはいくつかあります。
・ボーカルと伴奏が合っていない部分がある
・節回しで不自然なところがある
・全体的に音質が良くない
・無理やり展開しているところがある
・エンディングまで到達しておらず尻切れトンボ
でも、楽曲としては非常に気に入っているので、部分的に直すことができればベスト。じゃあこれをベースに作り直してみようと考えたのです。最小限のアレンジを施した「歌ってみた」。これが目標です。
今回は、その試行錯誤の過程をお見せすることで、Sunoで生成された楽曲が現状どういうものなのかを理解しやすくなるのではないかと思います。
Suno楽曲をパート別に分離する
Sunoが出力するサウンドは48kHzのMP3ファイル。2ミックス(ステレオミックス)で、ボーカルとオケが音源分離されておらず、MIDIデータも提供されていないため、その後のデータ取り回しが難しいです。そこをどうするかというのが
まずポイント。
▲Sunoが生成したMP4ファイル
少なくともボーカルとオケを分離できれば、オケに自分のボーカルを重ねることで簡単に「歌ってみた」ができます。まずそれを試しましょう。
Apple MusicやSpotifyにはAIを使ってボーカルをオフにできる機能がありますが、同様のものはフリーソフト、商用ソフトで出ています。今回は「UVR5」(Ultimate Vocal Remover)というフリーソフトを使用します。
UVR5はDemucsをはじめとする複数の音源分離アルゴリズムを使うことができ、さらに複数のアルゴリズムのいいとこどりをすることで最適なボーカルトラック取り出しができるのが特徴です。
今回はそこまではやらずに、Demucsの最新版のみを使いました。分離できるのは、ボーカル、ベース、ドラム、その他の4種類。他のソフトも大体そうなっているようです。
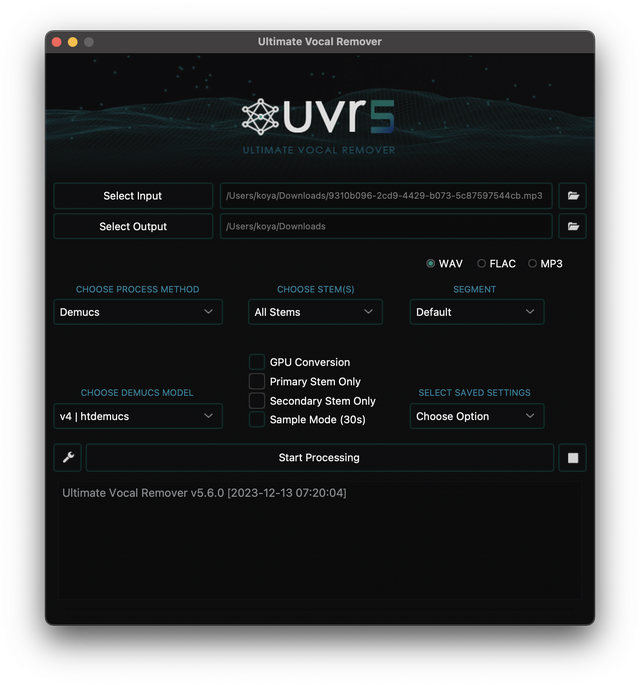
▲UVR5の設定画面
実際にやってみましたが、「その他」に入っているはずの、ピアノの音の減衰が激しく、ちょっと使い物にならないことが判明。いったんDAW(Logic Pro)に取り込んで、1トラックずつ耳コピしていく方針に切り替えました。
まずテンポを合わせます。129BPMで決定。ベーストラックはちゃんと分離されていて、そこからコードはなんとか類推できるようになりました。
ベースは、FlexPitchという機能を使うとピアノロールのノートが表示されるので、音高がわかります。ソフト音源を使って、同じベース音を別トラックに。それを元にコードを推定してピアノトラックも追加します。
コードに関しては、ヤマハがiPhoneアプリで出している「Chord Tracker」など、MP3やWAVファイルを取り込めばそのコードを使った伴奏のスタンダードMIDIファイルをエクスポートしてくれるものがあるので、それを使うこともできます。今回は単純なコードだったので、それを使うまでもありませんでした。
ドラムはほとんどなかったので、無視。これで耳コピは完了です。
ボーカルは分離できたので、オリジナルの歌を入れれば「歌ってみた」ができます。ただその前にもう一つやることがあります。
Sunoが出力した音楽で、途中で伴奏と歌メロが合っていないところがあるので、そこをなんとかしたい。
1小節分足りない状態で無理やり歌っている状態だったので、そこに1小節インサートして、歌詞とメロディーラインを当てはめます。ピアノとベースはソフト音源なので、簡単に追加できます。
そのほか、日本語のメロディーとして不自然なところを修正していきます。大体はFlexPitchで音符を前後左右に動かすことでなんとかなります。FlexPitchというのは、Logic Proが標準で持っている機能で、短音のメロディーの音の高さ、長さ、タイミング、ピッチの遷移などを自在に操ることができます。
こうした機能は「Melodyne」が有名で、現在世に出ているポピュラー音楽のほとんどのボーカル曲で使われているといっていいと思います。
これを使うと、節回しの不自然なところは変えられます。
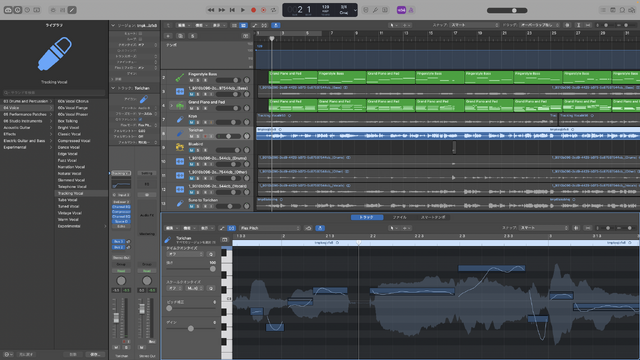
▲Logic ProのFlexPitchでボーカルのメロディーは自在に変更できる
分離したSunoのボーカルを元データにして、ターゲットボーカルである妻音源とりちゃん[AI]にRVCを使った声質変換することを試みました。AI声質変換をかけることで、オリジナル音源の音質は、AIによるクリアなものに変換されるというメリットもあります。
大体はうまくいったのですが、オリジナルのボーカルが伴奏を排除しきれずに一部ビープ音みたいになるところがあるので、録り直しは必要だと感じました。また、今回は問題なかったのですが、途中でハモリが入っている部分があって(これもすごいことです)、そのせいでピッチ(f0)取得が難しいケースも考えられます。
結局、参照ボーカルは、自分で歌ってみることにしました。声域はギリギリなんとかなりました。
日本語メロディーの不自然さもこれで解消できるはずです。そこからRVCにかけて妻音源とりちゃん[AI]に変換します。自分の声から妻の歌声にという変換は何度もやってきていることなので、うまくいきました。
比較の動画も作ってみました。
名も知らぬSunoの歌手
ボーカルを分離して比較してみて分かったのですが、Sunoのボーカルはかなり上手いです。自分では真似できないくらい雰囲気があります。前半はしっとりした、発音も曖昧な感じだったのが、曲の後半では徐々にはっきりしてくるくらいの表現力があり、これはちゃんと歌詞を分かった上で盛り上げているのでは疑惑もあります。というか、Sunoは歌詞の内容を理解していて、そこから曲作って演奏しているでしょう疑惑があります。
Sunoの歌手、名前がついていない「仮歌の子」なのがもったいない。須野すのこ、とかどうでしょうか。奈須きのこっぽいですが。
16年前、初音ミクがまだ16歳だったころ(今もそうですが)、「歌ってみた」が生まれました。その頃の初音ミクは「機械の声」として、自己投影したような歌がオリジナル曲(自己言及曲とか言ってましたね)として作られていました。もちろん書いているのは人間なのですけどね。
機械としてのAIとしてのロボットとしての哀しみを歌ったものが結構あり、それを実際にAIが作詞・作曲して、自分で歌えるようになったのです。これは胸が熱くなります。
さらにそれを人間(筆者)が歌い、それをAIを使った別の人の歌声(妻音源とりちゃん[AI])にした「歌ってみた」ができました。古参ボカロPたちはどう感じてくれるでしょうか。
音楽のあり方はどう変わるか
さて、このSuno、完成品としての使い方はいろいろ考えられます。これは、SF作家の野尻抱介さんが「南極点のピアピア動画」の中で描いていた、シチュエーションによって歌の中身が変わっていくような音楽の作り方。楽曲データの中に、リスナーの状況に応じて変化する要素を組み込んでおくことが可能になるような未来を描いています。Sunoの発展系で考えれば、プロンプト(歌詞と音楽スタイル)を、マルチモーダルな大規模言語モデルがその時の気象状況、位置、本人の生体センサー、他人とのインタラクションなどを考慮して出力し、それをSunoで楽曲として生成するようなことは考えられるでしょう。それを聴くための専用デバイスも出てくるかもしれません。

Ai PinのようなAIネイティブデバイスに、こうした機能が必須となる未来。

GoogleやMetaなどは楽曲を含む音声生成AIもすでに技術として持っているので、わざわざSunoのような外部サービスと連携する必要すらないでしょう。
人間が作るものではなく、AIが自分のために作ってくれる、お抱えの宮廷音楽家をはべらすパトロンみたいなことができるのかもしれません。
その歌声はそれぞれの楽曲に合った、名前も知らない歌手のボーカルになるでしょうが、それをあえて、この声で、この表現で歌わせてという指定も可能になるかもしれません。
そんな状況になったら、既存の音楽著作権の枠で考えるのは非常に困難になるでしょうね。
音楽制作の現場はどうなるか
Sunoは、今のところ、MP3の比較的音質の低いもの(それでも他のサービスと比べると相当いい)ですが、これを音楽制作に利用しようとすると、前述のように、完成後にそこから楽器パート別に分離するというやり方しかできません。
それでもボーカルのメロディーパターン、コード進行、バッキングのアイデア、構成など、利用できるものはいくらでもあります。
元の音質を上げる手法としては、楽曲の超解像ソフトであるAudioSR(9月以降、アップデートが止まっているのが残念)が使いやすくなれば、それに頼ってもいいでしょう。
画像生成AIによる生成物を3Dモデルに変換する技術が日進月歩で爆速アップデートされているように、Sunoの完成品からMIDIデータを取り出すような技術も生まれてきそうです。いや、すでにあるのかもしれません。
画像生成AIにおけるControlNetのように、不自然な部分を指定したり、手本を見せることで思い通りに変えていくような技術も望まれるでしょう。
ChatGPTに作詞させてコード進行を提示させて、それを元に曲を作ってみたのが今年の1月末。

そこから1年も経たずにこれだけのことができるようにしたSunoの衝撃は、ひょっとしたら初音ミクレベルかもしれません。「Suno以降、Suno以前」で時代が分けられるのかも。これからは音楽のいろいろなところが大きく変わっていくのは間違いないでしょうから、その途中経過を楽しみながら体験していきたいと思います。
同じ歌詞で別バージョンもできました。メロディーは単調だけど、こっちの方がよりユーミンっぽいです。歌声も含めて。