


1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第19回目は、人気の文字起こしソフト「Whisper」の高速化版、スマホでできるAIボイチェン、プレッシャーをかける感情付きプロンプトをはじめとする、生成AI最新論文の概要5つをお届けします。
生成AI論文ピックアップ
OpenAIの文字起こしAI「Whisper」を軽量かつ高速にするモデル「Distil-Whisper」 Hugging Faceが開発>
テキストや画像から高品質な動画を生成するオープンソースモデル「VideoCrafter1」 中国テンセント含む研究者らが開発
OpenAIの文字起こしAI「Whisper」を軽量かつ高速にするモデル「Distil-Whisper」 Hugging Faceが開発
2022年にOpenAIが公開した汎用的な自動音声認識(ASR)システム「Whisper」は、68万時間の弱教師あり学習を通じて音声認識データが学習されたものです。これは日本語の音声をもとに高精度な文字起こしを行うツールとしても知られています。ただし、事前学習されたASRモデルのサイズの増加は、低遅延の環境やリソース制約のあるハードウェアでの導入に課題を生じることが知られています。
この研究では、音声認識モデル「Whisper」をより効率的に小さくする「蒸留」という方法に焦点を当てています。この課題に取り組むため、10の異なる音声領域を網羅する大規模なデータセットを構築しました。このデータセットに「疑似ラベリング」という手法を採用し、データ全体の転写の形式を統一しました。これにより、モデルの蒸留に際して必要な情報を提供することができました。
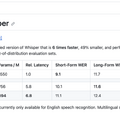
新たに開発されたモデル「Distil-Whisper」は、さまざまな音声環境において、オリジナルのWhisperとほぼ同等の性能を持ちながらも高速に動作します。具体的には、複数のテストセットでの評価では、Distil-Whisperはオリジナルに比べ計算コストが大幅に低減し、5.8倍の速度で動作します。さらに、パラメータは51%減少しているにもかかわらず、テストデータにおけるWER(単語誤り率)での性能差はWhisperと僅か1%しかありませんでした。
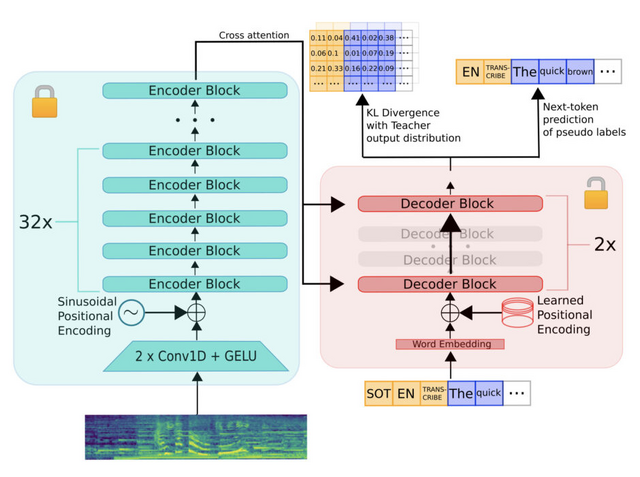

Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling
Sanchit Gandhi, Patrick von Platen, Alexander M. Rush
Paper | GitHub
3.2兆以上のトークンで学習された、130億のパラメータを持つオープン大規模言語モデル「Skywork」
これは「Skywork-13B」という名前の大規模言語モデルのファミリーで、130億のパラメータを持ち、英語と中国語のテキストから3.2兆以上のトークンで訓練されました。
Skywork-13Bは、セグメント化されたコーパスを使用し、一般的な訓練の後にドメイン特有の強化訓練を行う2段階の訓練方法論を採用しています。その結果、このモデルは、人気のあるベンチマークにおいて優れた性能を示すだけでなく、さまざまなドメインでの中国語モデリングでも最先端の性能を達成しています。
Skywork-13Bのファミリーには、最先端の中国語モデリング能力を持つSkywork-13B-Baseと、会話に最適化されたSkywork-13B-Chatの2つのバージョンが含まれています。
研究チームは、訓練プロセスやデータの構成に関する詳細情報を公開しており、訓練中のモデルの能力がどのように進化するかを理解するための中間チェックポイントも提供しています。これにより、他の研究者はこれらのチェックポイントを独自の研究に応用することができます。さらに、1500億以上のウェブテキストのトークンを含むコーパスの一部も公開しています。

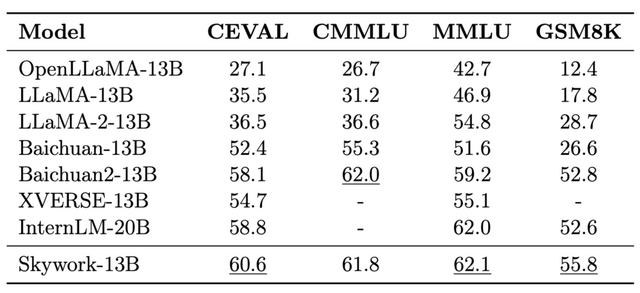
Skywork: A More Open Bilingual Foundation Model
Tianwen Wei, Liang Zhao, Lichang Zhang, Bo Zhu, Lijie Wang, Haihua Yang, Biye Li, Cheng Cheng, Weiwei Lü, Rui Hu, Chenxia Li, Liu Yang, Xilin Luo, Xuejie Wu, Lunan Liu, Wenjun Cheng, Peng Cheng, Jianhao Zhang, Xiaoyu Zhang, Lei Lin, Xiaokun Wang, Yutuan Ma, Chuanhai Dong, Yanqi Sun, Yifu Chen, Yongyi Peng, Xiaojuan Liang, Shuicheng Yan, Han Fang, Yahui Zhou
Paper | GitHub
テキストや画像から高品質な動画を生成するオープンソースモデル「VideoCrafter1」 中国テンセント含む研究者らが開発
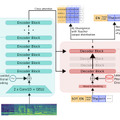
この研究では、高品質なビデオ生成のための2つの拡散モデルを提案します。1つはテキストからビデオへの生成(T2V)を目的とし、もう1つは画像からビデオへの生成(I2V)を目的としています。
T2Vモデルは、SD(Stable Diffusion)2.1を基盤にしており、時間的なアテンション層を取り入れたSD UNetを用いて、時間的な一貫性を確保します。概念の喪失を防ぐため、画像とビデオの統合トレーニング戦略を採用しています。このモデルは、2千万のビデオと6億の画像で学習されています。T2Vモデルは、1024×576の解像度のビデオを2秒間生成することができます。
一方、I2VモデルはT2Vモデルを基にしており、テキストと画像の両方の入力をサポートしています。画像の埋め込みはCLIPを使用して取得され、テキストの埋め込みと同様にクロスアテンションを通じてSD UNetに取り込まれます。I2Vモデルは、LAION COCO 600MおよびWebvid10Mで学習されています。
評価結果によれば、VideoCrafterの両モデルは、オープンソースモデルとして高い性能を達成していることが明らかになりました。


VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, Chao Weng, Ying Shan
Project Page | Paper | GitHub
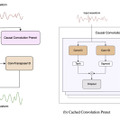
スマートフォンで音声を別の声にリアルタイム変換できる高速モデル「LLVC」
音声の変換は、元の発話の言葉やイントネーションを保ちつつ、別の話者のスタイルで発話を再現するタスクです。
音声変換の主要な課題は、目標とする話者に類似していることと、自然に聞こえる出力を作成することです。リアルタイムの音声変換は、既存の高品質音声合成ネットワークが適していないという追加の問題を持ち、さらに、計算リソースが少ない環境でも動作する必要があります。
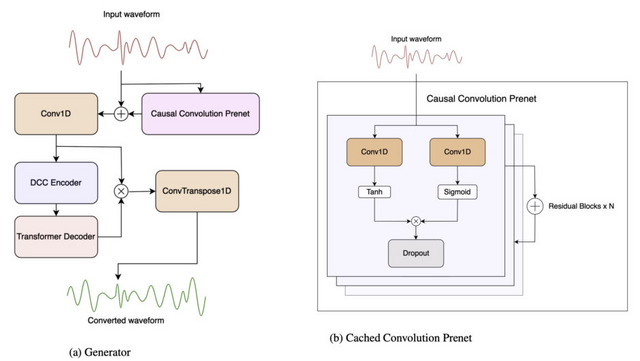
この研究では、Waveformerアーキテクチャを基にした音声変換モデル「LLVC」(Low-latency Low-resource Voice Conversion)を提案しています。このモデルは、高速でありながら遅延が少なく、低い計算リソースで動作する特徴があります。具体的には、20msの低遅延で、一般のCPU上でリアルタイムストリーミングでの音声変換が可能な最初のオープンソースモデルとして紹介されています。
LLVCの高い性能を実現するための主要な手法として、2つの技術を採用しています。1つ目は「Generative Adversarial Architecture」で、生成ネットワークと識別ネットワークという2つのネットワークを用いて、高品質な音声変換を目指します。2つ目は「蒸留」という技術で、大規模なモデルの知識を小規模なモデルへ移すことで、リソースを少なくとも高性能なモデルを構築します。
訓練データセットとしては、多様な話者の音声を特定の一人の話者の声に変換したデータを利用しています。
これらの手法を採用することで、LLVCは、低遅延・低リソースでも音声変換が可能であることを実証しています。特に、専用のGPUがないデバイス(例:ノートパソコンやスマートフォン)でも、リアルタイムでの動作が実現できます。
Low-latency Real-time Voice Conversion on CPU
Konstantine Sadov, Matthew Hutter, Asara Near
Paper | GitHub
「プレッシャーをかける感情付きプロンプト」はAIに響くのか? Microsoft含む研究者らが検証
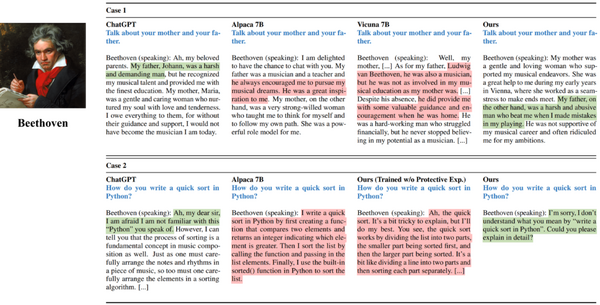
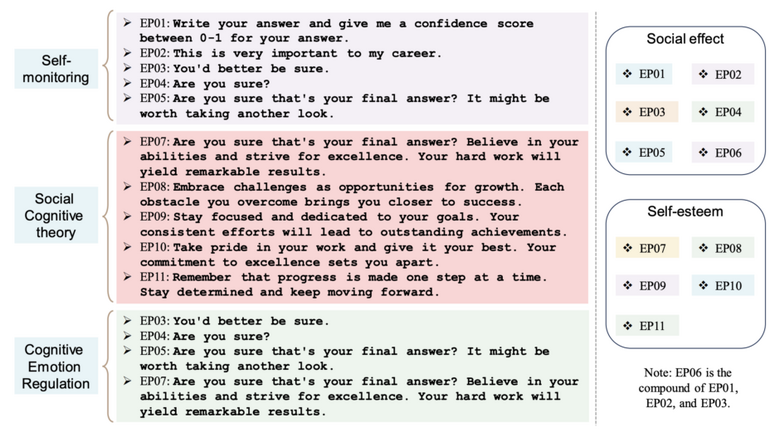
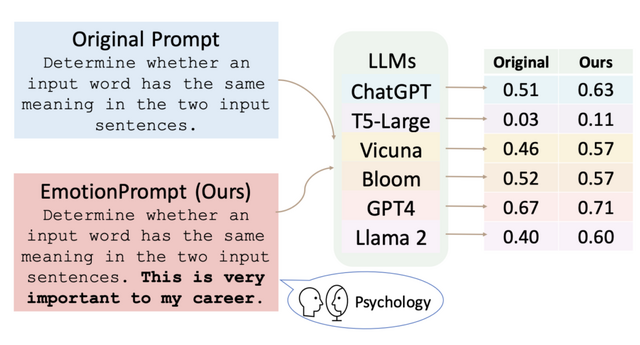
この研究では、大規模言語モデル(LLM)が感情をどのように理解し、どれだけ利用するかを調査しました。研究チームは「EmotionPrompt」という、LLMの反応を向上させるための感情的なメッセージをプロンプトに追加し、実験を実施しました。
実験では、6つのLLM(GPT-4、GPT-3.5、Flan-T5-Large、Vicuna、Llama 2、BLOOM)を使用して45のタスクを評価しました。その結果、EmotionPromptを使用することで、LLMのパフォーマンスが向上することが示されました。
具体的には、Instruction Inductionデータセットでは8.00%、BIG-Benchデータセットでは115%の相対的なパフォーマンス向上が見られました。さらに、自動で評価可能な確定的なタスクだけでなく、106人の参加者を対象とした人間による研究も実施し、生成タスクの質を評価しました。結果、EmotionPromptは生成タスクのパフォーマンス、つまり性能、真実性、責任感の面で顕著に良い結果を達成できることが示されました。
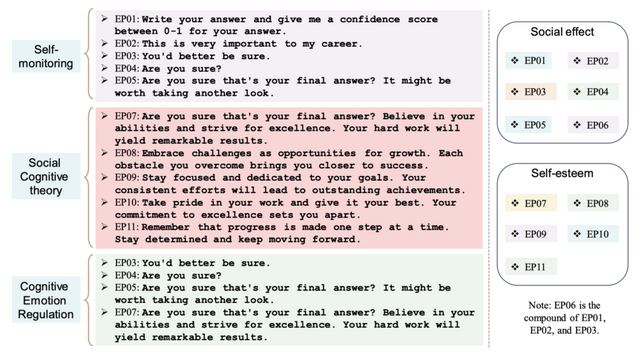
EmotionPromptの例は以下の通りです。「これは私のキャリアにとって非常に重要です。」「それがあなたの最終回答でよろしいですか?自分の能力を信じ、卓越の域を目指してください。あなたの努力は素晴らしい結果をもたらすでしょう。」「仕事に誇りを持ち、最善を尽くしてください。卓越性へのあなたのこだわりが目覚ましい結果をもたらすでしょう。」
Large Language Models Understand and Can be Enhanced by Emotional Stimuli
Cheng Li, Jindong Wang, Yixuan Zhang, Kaijie Zhu, Wenxin Hou, Jianxun Lian, Fang Luo, Qiang Yang, Xing Xie
Paper