1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、現在AIモデル評価の業界標準とされているランキング形式(リーダーボード)のAIベンチマーク「Chatbot Arena」における問題を明らかにした研究「The Leaderboard Illusion」を取り上げます。
▲Chatbot Arenaの問題を明らかにすることで、より公平で透明性のある評価プラットフォームとなるための改善策を提案する
この研究では、米国に本部があるAI企業の研究機関Cohere Labsの研究者らが主導し、プリンストン大学やスタンフォード大学など複数の大学の研究者らが参加し調査しました。
Chatbot Arenaは2023年に創設され、人間のユーザーが任意の質問を入力し、2つの異なるAIモデルからの匿名回答を比較評価するというテストでAIモデルのランキングを行っています。このプラットフォームは、世界中のAIチームがモデルの精度を競い合う重要な場として機能しています。
研究チームは200万以上のテストと42のAIチームによる243のAIモデルを詳細に分析しました。その結果、いくつかの問題が特定されました。
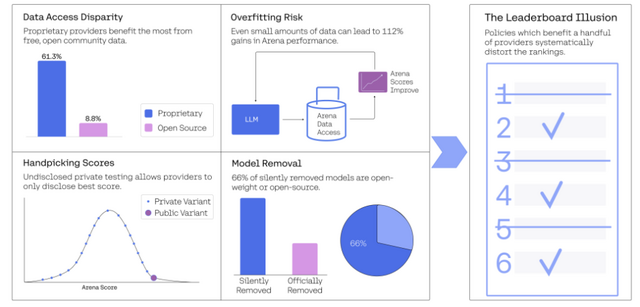
最初の問題は、一部のAIチームが複数のモデルバリアント(モデルの変種や派生バージョン)を非公開でテストし、最良のスコアだけを公開できるという未公表の方針が存在することです。
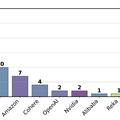
研究者たちが2025年1月から3月の間にChatbot Arenaを定期的に調査したところ、Metaは27の非公開モデル、Googleは10の非公開モデル、Amazonは7つの非公開モデルをテストしていました。特にMetaの場合、Llama 4リリースに先立つ1カ月間だけで27もの非公開モデルをテストし、さらにビジョン専用のリーダーボードで追加の16モデルをテストしていたことが判明し、合計43のバリアントに達していました。
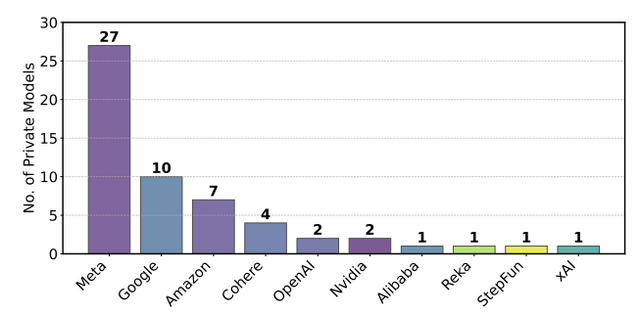
▲各AIチームが非公開でテストしていた件数
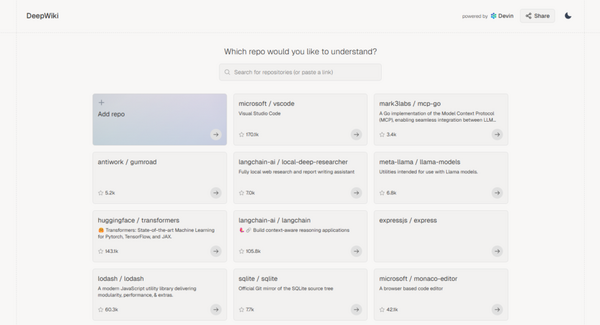
次に別の問題として、プロプライエタリ(独自)モデルとオープンソース/オープンウェイトモデルの間に顕著なデータアクセス(テストに選ばれる頻度)の格差が存在しています。
分析によれば、GoogleとOpenAIはそれぞれArenaの全テストプロンプトの19.2%と20.4%を取得している一方で、41のオープンソースモデルが受け取っているのは合わせても全体のわずか8.8%に過ぎませんでした。
さらに詳しく見ると、大手AIチーム(OpenAI、Google、Meta、Anthropic)の4社だけでArenaデータの62.8%を占めており、これはAllen AI、Stanford、Princeton、UC Berkeleyといった主要な学術機関や非営利研究所の合計シェアの68倍という圧倒的な差があります。
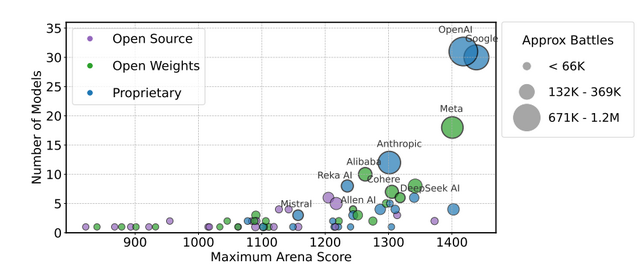
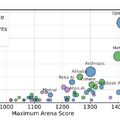
▲各AIチームの公開モデル数と最大Arenaスコアの関係を示しており、円の大きさはデータアクセス数を表し、プロプライエタリモデルの方が多くのテスト機会を得てより高いスコアを獲得する傾向が見られる
このデータアクセス格差の重要性を調べるため、言語モデルのトレーニングにおけるArenaデータの割合を変えた実験を実施しました。結果は、その使用率を増加させることで、モデルの勝率が23.5%から49.9%へと最大112%も向上することが示されました。このことから、テストに選ばれる頻度が高いプロプライエタリモデルは、実質的な性能向上という形で優位性を得ていることが分かります。
さらに、モデルの廃止(リーダーボードからの除外)もプロプライエタリモデルとオープンソース/オープンウェイトモデルに対して不均衡に適用されており、これがテストプロンプトのアクセス頻度の優位性の長期的な不公平を生み出しています。
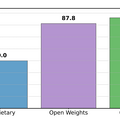
公式に廃止されているモデルは47個ですが、実際には205個のモデルがデータアクセスをほぼゼロに削減されています。これは提供者への通知なしにリーダーボードから“除外”されているのと同等を意味します。具体的には、オープンウェイトモデルの87.8%とオープンソースモデルの89%が廃止されているのに対し、プロプライエタリモデルの廃止率は80%と低くなっています。
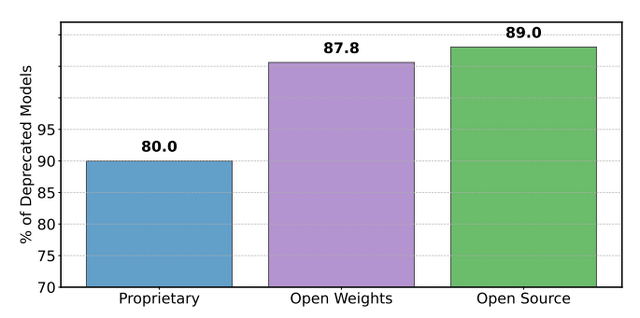
▲2025年3月~4月の期間中、リーダーボードの統計に基づき、除外となったプロプライエタリモデルとオープンモデルの割合
この不均衡な廃止は、Bradley-Terryモデル(ランキングの基礎となる数学モデル)の前提条件を崩し、ランキングの信頼性を低下させます。研究チームのシミュレーションによれば、モデルが廃止されると、そのモデルのデータアクセス履歴が最新の評価条件を反映しなくなり、残りのモデル間のランキングが歪められる結果となります。
他に分かった点として、Arenaのプロンプト(質問)に高い重複率があることが示されています。2024年11月から2025年4月の間で、月内での重複率は平均20.14%に達し、月をまたいだ重複も約7.3%存在しました。これは、過去のデータにアクセスできるAIチームが次の月のテストでより良い性能を発揮できる可能性を示唆しています。
今回の研究はChatbotArenaの欠陥を指摘していますが、研究者たちはリーダーボードの価値そのものを否定するのではなく、より公平で透明性のある評価プラットフォームとなるための改善策を提案しています。