

AnthropicがClaudeファミリーの新モデル「Claude 3.5 Sonnet」をリリースしました。このモデルは、各種ベンチマークで同ファミリーの旧最上位モデルClaude 3 OpusやOpenAIのGPT-4を上回る性能を示しています。ユーザーの間でも様々な使用事例が共有され、その高性能ぶりが話題となっています。
一方、GoogleやNVIDIAから資金調達を受けているAIベンチャー「Runway」は、新しい動画生成AIモデル「Gen-3 Alpha」を発表しました。前モデルGen-2と比較して、忠実度、一貫性、モーションの面で大幅な改善が見られるとのことです。公開されているサンプル動画からも、その高精度が確認できます。
国内では、カラクリ株式会社が国産LLMとして初めてFunction callingとRAGに対応した「KARAKURI LM 8x7B Instruct v0.1」を発表しました。このモデルは高い精度を維持しつつ、LLM開発で一般的に使用されるNVIDIAの高価なGPUではなく、AWS Trainiumを利用することでコストを抑えています。
さて、この1週間の気になる生成AI技術をピックアップして解説する、生成AIウィークリー(第52回)では、オープンソースで成長する動画生成AI「Open-Sora」の新バージョンや、精度の伸び代が見込まれるAIによる3Dメッシュ生成分野から「Unique3D」と「MeshAnything」を取り上げます。
生成AI論文ピックアップ
コーディングや数学特化型オープンソース言語モデル「DeepSeek-Coder-V2」リリース。GPT-4-Turboに匹敵する性能
数百万トークンクラスのコンテキストを扱う大規模言語モデル専用で評価するベンチマーク「LOFT」をGoogle DeepMindが開発
オープンソースの動画生成AI「Open-Sora 1.2」登場。16秒間の720p HD動画を生成
HPC-AI Tech チームが、テキストから動画を生成するモデル「Open-Sora 1.2」をリリースしました。数カ月前にリリースしたOpen-Sora 1.0の新バージョンとなります。ただし、これらはOpen AIの動画生成AI「Sora」とは関係なく、クローズドなSoraに対抗して開発されている、Soraの再現を目指したオープンソースモデルとなります。
Open-Soraの新バージョンでは、ビデオ圧縮ネットワーク(VAE)を導入し、空間次元で8×8、時間次元で4倍の圧縮を実現しました。これにより、動画の品質を維持しながらトレーニングコストを大幅に削減しています。
また、1.1Bパラメータの拡散生成モデルを訓練し、16秒間の720p HD動画をワンクリックで生成できるようになりました。生成可能な動画の品質と長さが向上し、より多様な用途に対応できるようになっています。
さらに、Stable Diffusion 3の技術を参考にした改良された拡散モデルアルゴリズムを採用することで、モデルのトレーニング速度を向上させただけでなく、動画生成時の待ち時間も短縮しました。




Open-Sora: Democratizing Efficient Video Production for All
HPC-AI Tech
GitHub | Blog | Gallery | Hugging Face
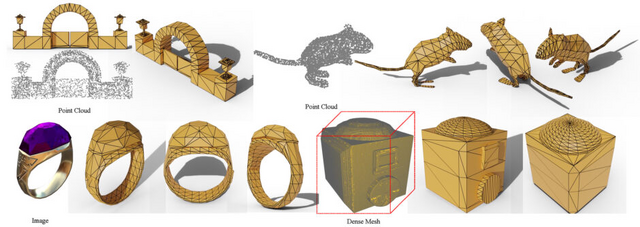
人間が作成したかのような高品質なメッシュを生成するAIモデル「MeshAnything」
従来のメッシュ抽出方法では、人間が作成したメッシュと比較して品質が劣ります。これらの課題に対応するため、研究者たちは「MeshAnything」というモデルを開発しました。
MeshAnythingは、主に点群(Point Cloud)、3D Gaussian Splatting(3D GS)、Neural Radiance Fields(NeRF)、その他の3D表現から得られた形状情報を入力として、人間のアーティストが作成したかのような高品質なメッシュを出力します。
MeshAnythingのアーキテクチャは、VQ-VAEと形状条件付きデコーダーのみのトランスフォーマーで構成されています。まずVQ-VAEを使用してメッシュ語彙を学習し、その後、この語彙に基づいて形状条件付き自己回帰的メッシュ生成のためのトランスフォーマーを訓練します。
実験結果によると、MeshAnythingは従来の方法と比較して、数百倍少ないポリゴン数でメッシュを生成し、保存・レンダリング・シミュレーションの効率を大幅に向上させながら、同等の精度を達成しています。また鋭いエッジや平面など、オブジェクトの幾何学的特徴をより正確に再現し、人間のアーティストが作成したメッシュに近い、効率的で美しいトポロジーを生成します。
さらに、MeshAnythingの大きな強みは、様々な3D表現形式から高品質なメッシュを生成できる柔軟性です。これにより、3D再構成、3D生成、3Dスキャンなど、様々な3D資産作成パイプラインと組み合わせて使用することが可能になり、3D産業への応用を促進します。



MeshAnything: Artist-Created Mesh Generation with Autoregressive Transformers
Yiwen Chen, Tong He, Di Huang, Weicai Ye, Sijin Chen, Jiaxiang Tang, Xin Chen, Zhongang Cai, Lei Yang, Gang Yu, Guosheng Lin, Chi Zhang
Project | Paper | GitHub
コーディングや数学特化型オープンソース言語モデル「DeepSeek-Coder-V2」リリース。GPT-4-Turboに匹敵する性能
DeepSeek-AIは、コード生成や数学的推論において商用の大規模言語モデルに匹敵する性能を持つオープンソース言語モデル「DeepSeek-Coder-V2」を発表しました。MoEフレームワークに基づいて、16Bと236Bパラメータのモデルを提供します。
このモデルは、DeepSeek-V2をベースに6兆トークンの追加データで事前学習を行い、コーディングと数学的推論の能力を大幅に向上させています。対応する言語数も86から338に拡大し、最大コンテキスト長も16Kから128Kトークンに伸ばしました。
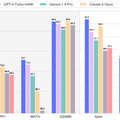
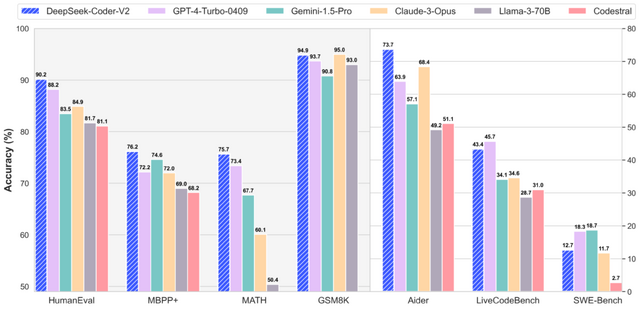
研究者らは、DeepSeek-Coder-V2が多くのベンチマークでGPT-4 Turbo、Claude 3 Opus、Gemini 1.5 Proといった最先端の商用モデルと同等以上の性能を示したと報告しています。
コード生成タスクにおいては、HumanEvalで90.2%、MBPPで76.2%のスコアを達成し、LiveCodeBenchで43.4%を記録しました。数学的推論能力においては、MATH benchmarkで75.7%の正確性を達成し、GSM8Kで94.9%のスコアを記録しました。

DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
DeepSeek-AI, Qihao Zhu, Daya Guo, Zhihong Shao, Dejian Yang, Peiyi Wang, Runxin Xu, Y. Wu, Yukun Li, Huazuo Gao, Shirong Ma, Wangding Zeng, Xiao Bi, Zihui Gu, Hanwei Xu, Damai Dai, Kai Dong, Liyue Zhang, Yishi Piao, Zhibin Gou, Zhenda Xie, Zhewen Hao, Bingxuan Wang, Junxiao Song, Deli Chen, Xin Xie, Kang Guan, Yuxiang You, Aixin Liu, Qiushi Du, Wenjun Gao, Xuan Lu, Qinyu Chen, Yaohui Wang, Chengqi Deng, Jiashi Li, Chenggang Zhao, Chong Ruan, Fuli Luo, Wenfeng Liang
Paper | GitHub
写真1枚から3Dモデルを生成するAIモデル「Unique3D」
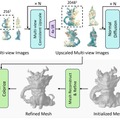
「Unique3D」は、単一の2D画像から高品質な3Dメッシュを効率的に生成するフレームワークです。Unique3Dは、複数の深層学習モデルを組み合わせた独自のパイプラインを採用しています。
まず、入力された1枚の写真をもとに、モデルが物体を様々な角度から見たイメージを作り出します。次に、それらのイメージをより鮮明にし、細部まで作り込みます。同時に、物体の表面の凹凸を表現するための情報(法線マップ)も生成します。最後に、これらの情報を組み合わせて、詳細な3Dモデルを構築します。
この全過程がわずか30秒以内で完了し、しかも生成される3Dモデルの品質が非常に高いのが特徴です。複雑な形状や細かいテクスチャまで再現できるため、プロが作ったモデルに匹敵する品質を実現しています。特に、従来の手法で問題となっている、3Dモデルの異なる視点や面で、互いに矛盾する特徴や詳細が現れる現象を効果的に回避しています。
Unique3Dの性能を既存の手法と比較するため、Google Scanned Objects (GSO)データセットから30のランダムに選択されたオブジェクトを使用して評価を行いました。また、ユーザースタディも実施されました。結果は、Unique3Dが比較対象となった他の手法(One-2-3-45、OpenLRM、SyncDreamer、Wonder3D、InstantMesh、GRM、CRM)よりも多くの指標で優れていることを示しています。特に、幾何学的な正確さ、視覚的な類似性、意味的な一致において顕著な性能を発揮しました。



Unique3D: High-Quality and Efficient 3D Mesh Generation from a Single Image
Kailu Wu, Fangfu Liu, Zhihan Cai, Runjie Yan, Hanyang Wang, Yating Hu, Yueqi Duan, Kaisheng Ma
Project | Paper | GitHub | Demo
数百万トークンクラスのコンテキストを扱う大規模言語モデル専用で評価するベンチマーク「LOFT」をGoogle DeepMindが開発
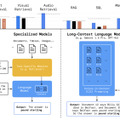
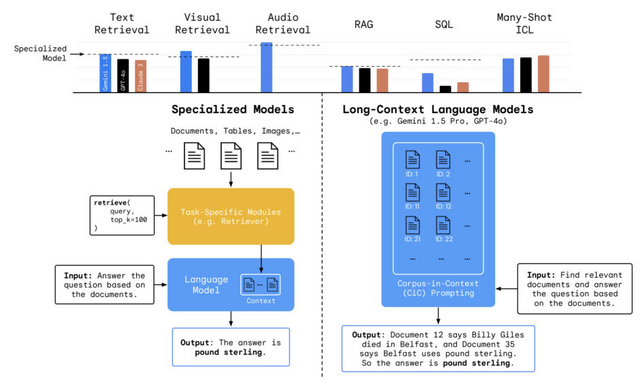
Google DeepMindの研究チームは、数十万から数百万トークンの長いコンテキストを扱う言語モデル(Long-Context Language Models, LCLMs)が従来のツールやデータベースに依存するタスクに対してどのような影響を与えるかを評価するために、LOFT(Long-Context Frontiers)というベンチマークを導入しました。
LOFTは、LCLMsの性能を測定し比較するために特別に設計された評価ツールです。35の異なるデータセットで構成されており、テキスト、画像、音声など様々なモダリティを含んでいます。
LOFTベンチマークを用いた実験では、LCLMsの多岐にわたる能力が評価されました。テキスト検索においては、Gemini 1.5 ProがGeckoという専門の検索システムと同等の性能を示し、128,000トークンのコンテキスト長ではそれを上回りました。視覚的検索では、Gemini 1.5 ProがCLIPという専門の画像検索モデルを凌駕し、テキストと画像の両方を理解する能力を証明しました。
音声検索タスクでは、Gemini 1.5 Proが5つの言語(英語、スペイン語、フランス語、ヒンディー語、中国語)で専門モデルと同等以上の性能を発揮しました。検索補強生成(RAG)タスクでは、LCLMsが専門システムと互角の性能を示し、特に複数ステップの推論を要するタスクで優れた結果を出しました。
一方で、SQLタスクのような複雑な論理推論を必要とする分野では、LCLMsは専門システムに及ばず、改善の余地があることが明らかになりました。多数事例学習では、LCLMsが数百から数千の例を一度に学習することで精度を向上させられることが分かりましたが、タスクの複雑さによっては例の数を増やしても性能が頭打ちになる場合もありました。
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Jinhyuk Lee, Anthony Chen, Zhuyun Dai, Dheeru Dua, Devendra Singh Sachan, Michael Boratko, Yi Luan, Sébastien M. R. Arnold, Vincent Perot, Siddharth Dalmia, Hexiang Hu, Xudong Lin, Panupong Pasupat, Aida Amini, Jeremy R. Cole, Sebastian Riedel, Iftekhar Naim, Ming-Wei Chang, Kelvin Guu
Paper | GitHub