
1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第47回目は、生成AI最新論文の概要5つを紹介します。
生成AI論文ピックアップ
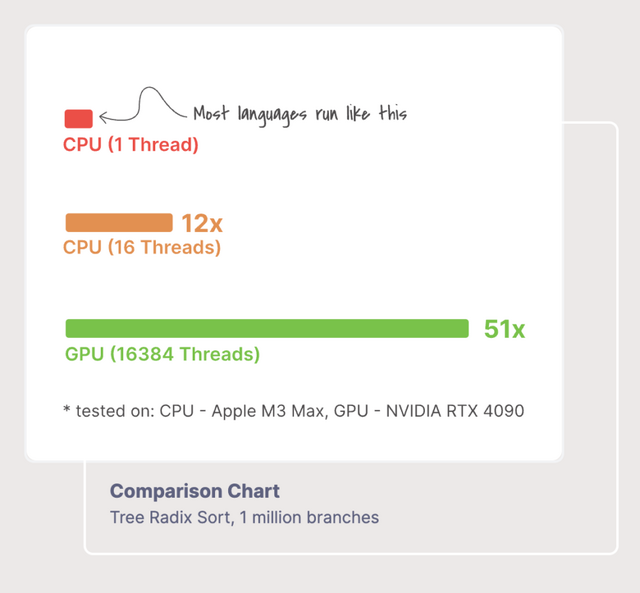
GPU上でネイティブ動作する並列処理が可能な新プログラミング言語「Bend」とランタイムシステム「HVM2」
「Bend」と「HVM2」(Higher-order Virtual Machine 2)は、Higher Order Companyというスタートアップが開発した、新しい並列プログラミング向けの言語とランタイムシステムです。
Bendは高級言語でありながらGPU上で並列処理できる新しいプログラミング言語です。PythonやHaskellのような扱いやすい文法を持ち、スレッドの生成やロック、ミューテックスなどを明示的に記述する必要がなく、並列処理の詳細を意識せずにコードを書くことができます。
Bendのランタイムである「HVM2」が、自動的に並列化を行ってくれます。例えば、((1 + 2) + (3 + 4)) という式では、(1 + 2) と (3 + 4) が独立しているため並列に計算できます。このように並列化可能な部分を自動で検出し、GPUのようなマルチコアの並列ハードウェア上で高速に処理します。コア数が増えるほど、実行速度が向上するのが特徴です。

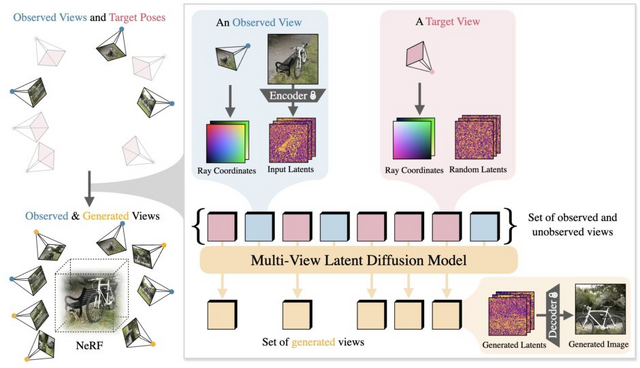
2D画像から3Dコンテンツを生成する「CAT3D」をGoogleが開発
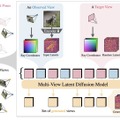
この研究では、CAT3Dと呼ばれる新しい3Dコンテンツ生成手法が提案されています。CAT3Dは、任意の数の入力画像から高品質の3Dシーンを生成できます。この手法の中核となるのは、多視点拡散モデルです。このモデルは、1つまたは複数の入力画像から、3D的に整合性の高い多数の新規視点画像を生成します。
生成された多視点画像を、ロバストな3D再構成パイプラインに入力することで、あらゆる視点からリアルタイムにレンダリング可能な3D表現が得られます。CAT3Dでは、わずか1分程度で3Dシーン全体を生成可能です。
単一画像からの3D生成や、少数の視点画像からの3D再構成などのタスクにおいて、CAT3Dは既存手法を上回る性能を示しています。特に、複雑で大規模なシーンの再構成において、大幅な品質向上が見られました。
CAT3Dは、生成モデルと3D再構成を分離することで、効率的かつシンプルで高品質な3D生成を実現しています。テキストから画像を生成する事前学習済みモデルからの転移学習により、未知のシーンに対しても柔軟に対応可能です。



CAT3D: Create Anything in 3D with Multi-View Diffusion Models
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan T. Barron, Ben Poole
Project | Paper
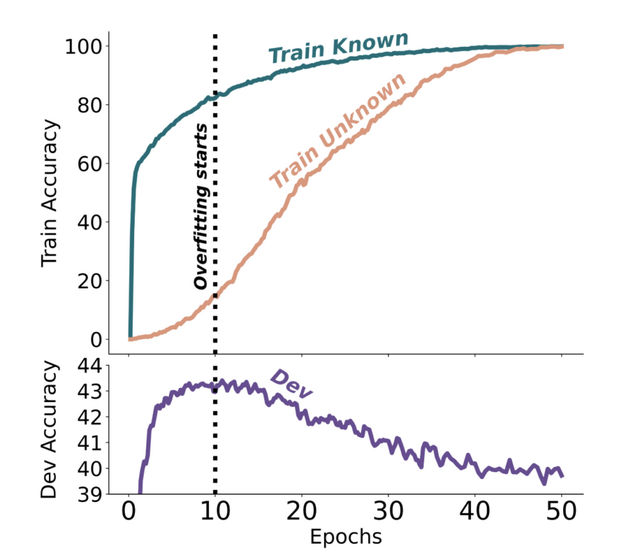
大規模言語モデルは追加学習や新知識で幻覚生成が増加。Googleなどが調査
大規模言語モデル(LLM)は、莫大なテキストデータを学習することで、多くの知識を蓄えています。しかし、LLMを特定のタスクに適応させるために追加の学習(微調整、ファインチューニング)を行う際、モデルが元々持っていなかった新しい知識を含むデータを与えることがあります。
この研究では、新しい知識を含むデータでLLMを学習させると、どのような影響があるのかを調べました。質問応答タスクを例に、新しい知識の割合を変えながら実験を行ったところ、次のことがわかりました。
新しい知識を含むデータの学習は、既存の知識と一致するデータの学習よりもかなり時間がかかります。また、モデルが微調整を通じて最終的に新しい知識を学習すると、既存の知識に関して誤った答え(幻覚、ハルシネーション)を生成する傾向が高くなります。
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
Zorik Gekhman, Gal Yona, Roee Aharoni, Matan Eyal, Amir Feder, Roi Reichart, Jonathan Herzig
Paper
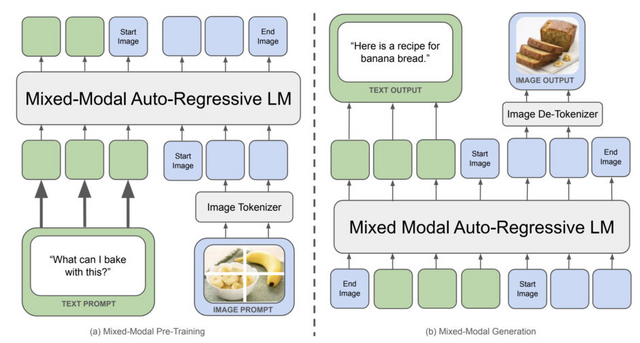
画像とテキストを使った長文生成が得意なAIモデル「Chameleon」をMetaが開発
「Chameleon」と呼ばれる、画像とテキストを任意の順序で理解・生成できるマルチモーダルモデルファミリーを紹介しています。
従来のマルチモーダルモデルは画像とテキストを別々にエンコードし、後段で統合することが多かったのですが、Chameleonは最初から画像とテキストを共有の表現空間に投影するアプローチを取っているため、より自然に2つのモダリティを結びつけられます。
視覚的質問応答、画像キャプション生成、テキスト生成、画像生成、長文のマルチモーダル生成など、幅広いタスクでChameleonの評価が行われました。その結果、Chameleonは汎用的な能力を示し、画像キャプションタスクでSOTAを達成しました。また、テキストのみのタスクでは、常識推論や読解などでLlama-2を上回り、Mixtral 8x7BやGemini Proに匹敵する性能を発揮しました。
さらに、画像とテキストが混在する長文の生成タスクにおいて、プロンプトや出力が画像とテキストの混合シーケンスを含む場合の人間評価では、Chameleon-34BがGemini ProやGPT-4Vを上回る優れた性能を示しました。


Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team
Paper
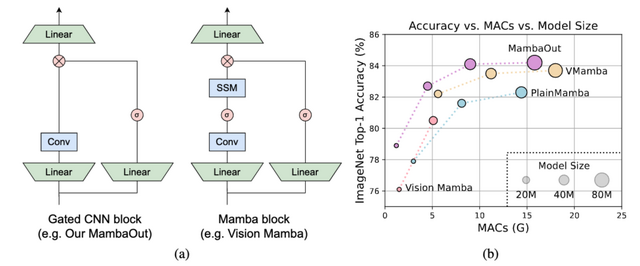
Transformerを超える「Mamba」は視覚認識タスクに必要か? 開発した「MambaOut」モデルで検証
自然言語処理で高い性能を示すMambaモデルを、画像認識のタスクに使おうという研究が行われています。Mambaモデルの心臓部分は、RNNに似たSSM(State Space Model)と呼ばれる仕組みです。
研究チームは、Mambaモデルが本当に画像認識に必要なのかを理論的に検討しました。その結果、Mambaモデルは「長いシーケンス長」と「自己回帰性」という2つの特徴を持つタスクに向いていることがわかりました。
画像分類は、どちらの特徴も当てはまらないため、Mambaモデルを使う必要はないと主張しています。一方、物体検出やセグメンテーションは長いシーケンス長という特徴を持つので、Mambaモデルの可能性を探る価値はあるとしています。
この主張を実験的に確かめるため、研究ではSSMを使わない「MambaOut」というモデルを作りました。ImageNetという画像分類のデータセットで試したところ、MambaOutモデルは全てのVision Mambaモデルよりも高い性能を示しました。これは、画像分類にMambaモデルが必要ないという主張を裏付ける結果です。
しかし、物体検出やセグメンテーションでは、MambaOutモデルは最先端のVision Mambaモデルほどの性能を出せませんでした。これは、物体検出やセグメンテーションタスクではMambaモデルが役立つ可能性を示唆しています。