



1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第43回目は、生成AI最新論文の概要5つを紹介します。
生成AI論文ピックアップ
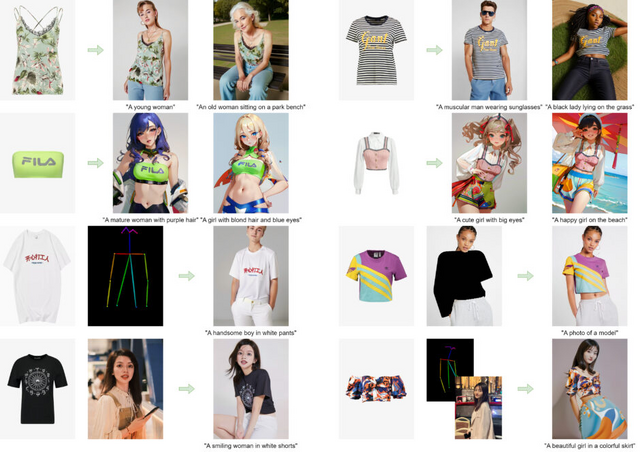
画像の衣服をキャラクターに着せる生成モデル「Magic Clothing」
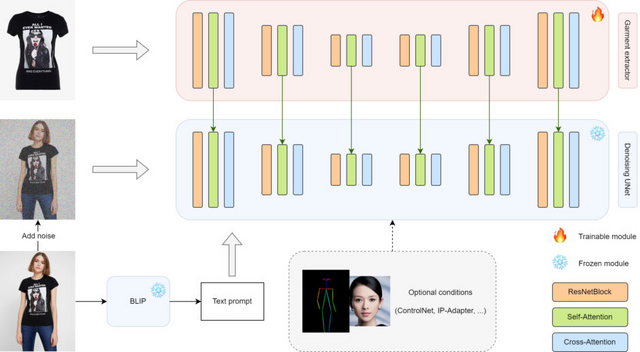
テキストと衣服画像を入力として、指定したキャラクターにその衣服を着せることができるモデル「Magic Clothing」を提案しています。この技術は、潜在拡散モデル(LDM)をベースとし、衣服の細部を忠実に再現しながら、テキストの指示にも従った多様な画像生成を可能にします。
Magic Clothingでは、garment extractorと呼ばれるモジュールを導入することで、入力画像から衣服の詳細な特徴を抽出し、LDMの潜在空間に滑らかに統合します。これにより、生成画像上で衣服の細部を忠実に再現できます。さらに、衣服の特徴とテキストプロンプトのコントロールのバランスを取る工夫もしています。
Magic Clothingは、追加学習のコストを抑えつつ、ControlNetやIP-Adapterといった他の拡張モジュールとの組み合わせが可能です。
性能評価のため、衣服と人物画像のペアからなるデータセットを構築し、CLIP scoreやLPIPSをベースとした指標を用いて定量的に比較したところ、Magic Clothingが従来手法を上回ることが示されました。質的な結果の比較でも、提案手法が衣服の細部を保持しつつ、テキストの指示に沿った多様で高品質な画像を生成できることが確認されました。

Magic Clothing: Controllable Garment-Driven Image Synthesis
Weifeng Chen, Tao Gu, Yuhao Xu, Chengcai Chen
Paper | GitHub
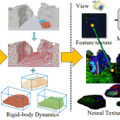
撮影した動画を操作可能な実世界3Dゲームに変換するAIモデル「Video2Game」
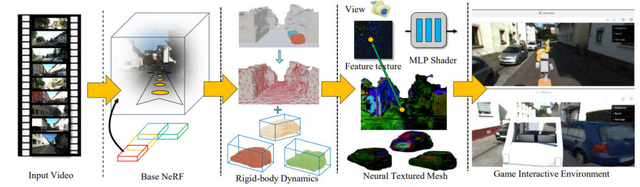
Video2Gameは、単一の動画から、リアルタイムでインタラクティブな3D環境を自動生成するアプローチです。このシステムは、NeRF(Neural Radiance Fields)、メッシュ、物理モジュールの3つのコアコンポーネントで構成されています。
NeRFモジュールがシーンのジオメトリとビジュアルな外観を効果的にキャプチャし、メッシュモジュールがNeRFの知識を蒸留することでレンダリングを高速化します。さらに、物理モジュールがオブジェクト間のインタラクションと物理的なダイナミクスをモデル化します。
これらのモジュールを巧みに組み合わせることで、Video2Gameは現実世界と見紛うようなインタラクティブな3Dバーチャル環境を構築します。この環境内では、ユーザーの操作にキャラクターがリアルタイムに反応し、自由に動き回ることができます。
研究チームは、屋内シーンや大規模な屋外シーンなど様々な環境でVideo2Gameのベンチマークテストを行い、その性能を検証しました。その結果、どのようなシーンにおいてもリアルタイムかつ高品質な3Dレンダリングを生成できるだけでなく、そこからインタラクティブなゲームを直接構築できることが分かりました。



Video2Game: Real-time, Interactive, Realistic and Browser-Compatible Environment from a Single Video
Hongchi Xia, Zhi-Hao Lin, Wei-Chiu Ma, Shenlong Wang
Project | Paper | GitHub
Metaなど、数百万トークンを入力しても効果的に処理できるAIモデル「Megalodon」開発
近年の大規模言語モデル(LLM)は、コンテキストウィンドウにおいて長い文脈を効率的に処理し、生成することが求められています。しかし、Transformerアーキテクチャは、計算量がコンテキスト長の2乗に比例するため、長い文脈での学習が非効率になってしまいます。
この問題を解決するため、「Megalodon」と呼ばれる新しいモデルが提案されました。Megalodonは大量のメモリを必要とせず、コンテキストウィンドウを数百万のトークンに拡張できます。
Megalodonは、MEGA(Moving Average Equipped Gated Attention)アーキテクチャを継承しつつ、性能と安定性を高める複数の技術要素を導入しています。
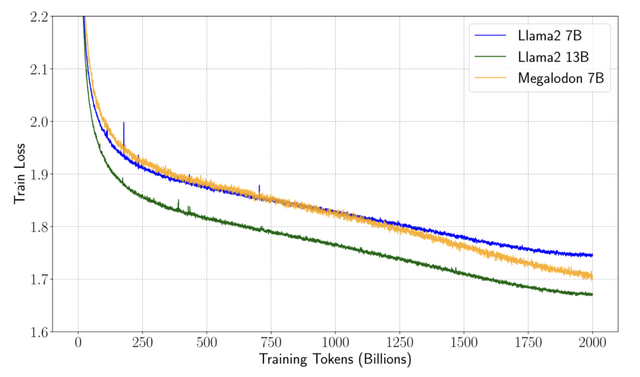
研究チームは、70億パラメータのMegalodonを2兆トークンで学習させ、Llama2-7B、13B、その他のモデルと比較しました。その結果、Llama2-7Bと比べ、Megalodonが学習効率と汎化性能において上回りました。4000トークンのコンテキストウィンドウでは、MegalodonはLlama-2よりわずかに遅いですが、コンテキストの長さが3万2000トークン以上に拡張されると、Megalodonは計算効率によりLlama-2を大幅に上回りました。

Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length
Xuezhe Ma, Xiaomeng Yang, Wenhan Xiong, Beidi Chen, Lili Yu, Hao Zhang, Jonathan May, Luke Zettlemoyer, Omer Levy, Chunting Zhou
Paper | GitHub
Adobeなど、画像4枚から高品質な3Dモデルを1秒以内に生成するAI「MeshLRM」を開発
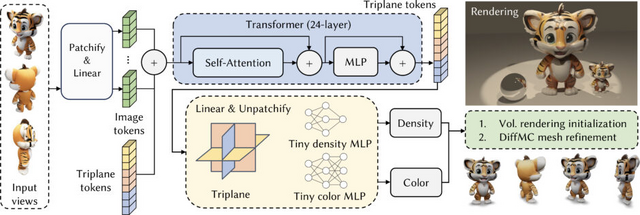
MeshLRMは、4枚の入力画像からわずか1秒以内に高品質な3Dメッシュを再構成できる手法です。従来の3Dシーンを再構成するためのモデル「Large Reconstruction Model」(LRM)とは異なり、MeshLRMは微分可能なメッシュ抽出とレンダリングをLRMフレームワークに組み込むことで、事前学習済みのLRMをメッシュレンダリングでファインチューニングし、エンドツーエンドのメッシュ再構成を実現しました。
また、MeshLRMではLRMアーキテクチャを簡略化し、低解像度から高解像度の画像を順番に使用するという新しいLRMトレーニング戦略を導入することで、速度を大幅に向上させ、より少ない計算量で高品質な結果を得ることに成功しています。
評価実験において、GSO、NeRF-Synthetic、OpenIlluminationデータセットで、他手法と比較し、レンダリング品質とジオメトリ品質において最先端の性能を達成しました。Instant3DのLRMモデルやZeroRF、FreeNeRFと比較して優位性を示した。
MeshLRMは、テキストや単一画像から3Dモデルを生成するなど、様々なアプリケーションに応用可能です。

MeshLRM: Large Reconstruction Model for High-Quality Mesh
Xinyue Wei, Kai Zhang, Sai Bi, Hao Tan, Fujun Luan, Valentin Deschaintre, Kalyan Sunkavalli, Hao Su, Zexiang Xu
Project | Paper
AI同士が教え合い質を高める、Microsoftの新型オープンソース大規模言語モデル「WizardLM-2」
つい最近、Metaがオープンソースの大規模言語モデル(LLM)「Llama 3」をリリースしました。そんな中で、MicrosoftもオープンソースなLLM「WizardLM-2」を発表しました。この新しいファミリーには、WizardLM-2 8x22B、70B、および7Bの3つのモデルが含まれています。
まだ論文は公開されていませんが、Xにおいて開発者が内容の一部を説明しています。
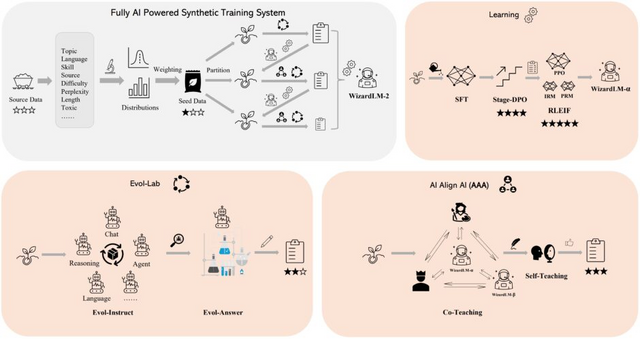
近年、LLMの訓練に使える自然言語データが不足しつつあります。そこで研究者たちは、AIが作成したデータとAIが監督したモデルによる訓練システムを構築し、WizardLM-2を開発しました。
訓練では、事前処理したデータを一度に使うのではなく、異なる区分に分けて段階的に行います。各段階では、まずデータを多様な指示・応答ペアに変換します。次に、「AI Align AI」(AAA)という仕組みを使って、最先端のLLMをグループ化し、お互いに教え合い、改善し合います。また、自らトレーニングデータを生成して学習に使用します。最後に、さまざまな種類の学習を行なってモデルを最適化します。
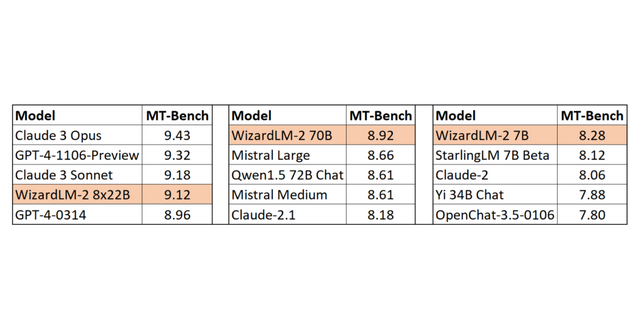
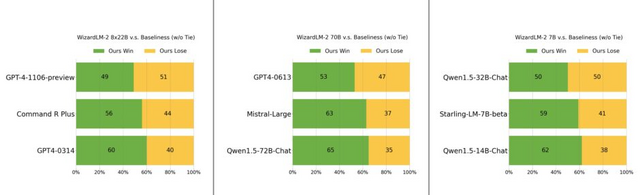
ベンチマーク評価では、WizardLM-2 70Bは同じサイズと比べて最高レベルを達成しました。WizardLM-2 7Bは、既存の10倍の規模のオープンソースの主要モデルと同等のパフォーマンスを実現します。WizardLM-2 8x22Bは、クローズドモデルの「Claude 3 Opus」や「GPT-4-1106-Preview」に対して非常に競争力のあるパフォーマンスを示しました。
WizardLM-2
Microsoft
Blog | Hugging Face