






1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第25回目は、生成AI最新論文の概要5つをお届けします。作曲歌唱AI「Suno」の登場で脚光を浴びている音楽生成についての新たな技術が登場。こちらはより音楽制作現場に寄り添った技術で、入力した音楽を参考にして新たな楽曲を生成する「StemGen」をはじめとして最新論文を紹介します。
生成AI論文ピックアップ
音楽から新しい音楽を生成していくモデル「StemGen」、無音からも可能。ByteDanceらが開発
現在の音楽生成モデルの多くは、テキスト記述やスタイルカテゴリなどの抽象的な情報に基づいていますが、音楽のコンテキストを直接聞き、適切な音楽的応答を生成するモデルはまだ珍しいです。この研究では、音楽を入力として新しい音楽を生成するモデル「StemGen」を提案しています。
例えば、音楽制作ソフトウェア「Ableton Live」で作成した短いドラムループを出発点とします。このドラムループをStemGenで処理すると、ドラムループに適したピアノループ(Stemと呼ばれる)を生成します。ドラムループとピアノループを組み合わせると、心地よい音楽が完成します。ピアノだけでなく、ベース、ギター、パーカッション、ハーモニック、メロディー、エレクトリックなどの生成も可能です。
これらの生成は反復可能で、ドラムから生成したピアノ、ドラムとピアノを組み合わせた音源から生成したギター、ドラムとピアノとギターを組み合わせた音から生成したエレクトリックなど、生成して組み合わせることを繰り返して、重層的な音楽を作り出すことができます。プロジェクトページではデモが公開されており、多くの音源を組み合わせた結果は、非常に調和がとれた複雑で高品質な音楽に仕上がっています。
このように何らかの音源から始めることも可能ですが、無音からStemGenを使用して音楽を生成することもできます。例えば、SlakhデータセットベースのStemGenモデルにピアノループを生成してもらうところから始め、異なるStemも複数生成してミックスしていきます。
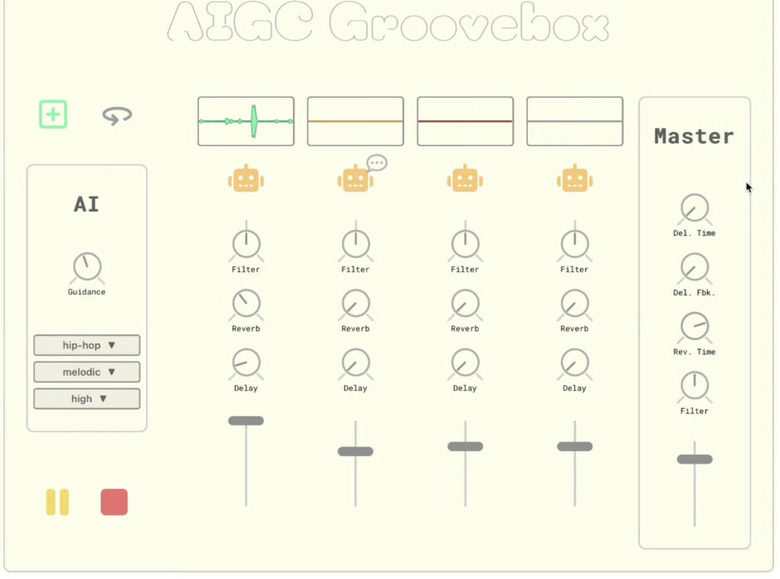
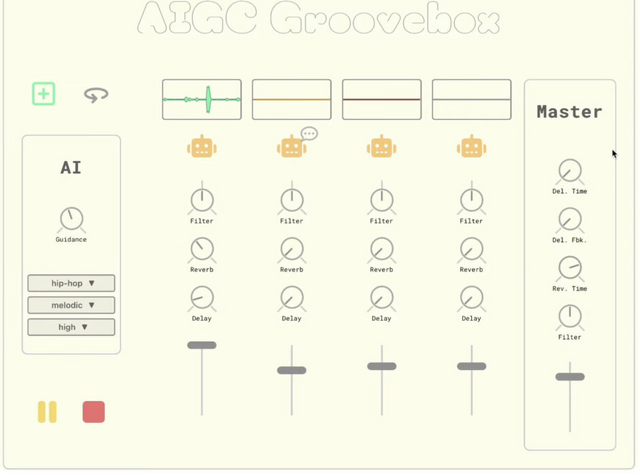
さらに、ユーザーがインタラクティブに操作して即興で音楽を生成できるStemGenベースのアプリケーションも開発しています。このアプリケーションでは、4チャンネルの音楽をループさせることができ、各チャンネルにリバーブ、ディレイ、DJスタイルのローパス/ハイパスフィルターを適用できます。各チャンネルには、「生成」ボタン(ロボットアイコン)があり、これを押すとStemGenモデルが現在のミックスされたループをコンテキストとして受け取り、望ましいStemを返します。
StemGen: A music generation model that listens
Julian D. Parker, Janne Spijkervet, Katerina Kosta, Furkan Yesiler, Boris Kuznetsov, Ju-Chiang Wang, Matt Avent, Jitong Chen, Duc Le
Project | Paper
画像内のキャラクターや人物を着せ替えできる拡散モデル「Outfit Anyone」、アリババグループなどが開発
バーチャル試着は、画像内の人物の姿はそのままで、服だけを変更する技術です。ユーザーが実際に服を試着しなくても、ファッションを試すことができるという点で注目されています。
ただし、現在の手法では、高い忠実度と細部の一貫性を持つ結果を出すのが難しいとされています。拡散モデルは高解像度で現実感のある画像を生成するのに適していますが、バーチャル試着のような特定のシナリオでは、制御と一貫性を保つのに課題があります。
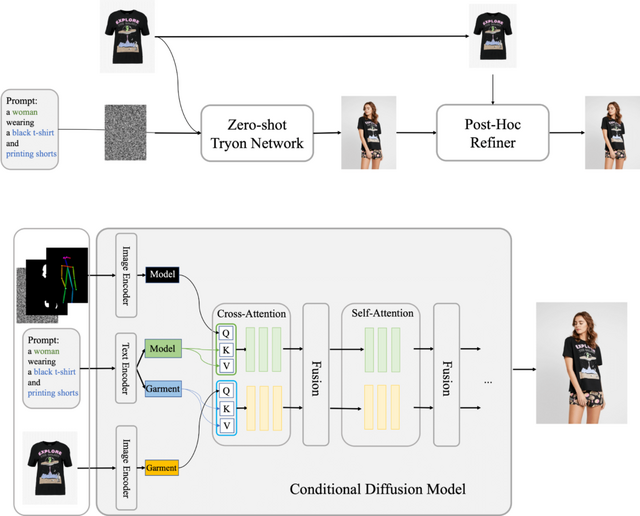
「Outfit Anyone」という新しいアプローチは、これらの課題に対処します。このシステムは、人物の写真、衣服の画像、そしてテキストプロンプトを使用して画像を処理する条件付き拡散モデルを採用しています。このモデルは、人物のデータと衣服のデータをそれぞれ独立して処理し、その後、これらのデータを統合して衣服の詳細を人物の画像に自然に組み込みます。
Outfit Anyoneは2つの主要な部分から構成されています。1つ目は初期試着画像を生成する「Zero-shot Try-on Network」、2つ目は最終的な画像の衣服と肌の質感を詳細に改善する「Post-hoc Refiner」です。
デモンストレーションでは、基本となる人物(またはキャラクター)に対して、特定の衣服(または別のキャラクターの服)が参照され、その衣服が人物に調和するように適用されています。
さらに、静止画像のキャラクターをアニメ化できる「Animate Anyone」とOutfit Anyoneを組み合わせることで、あらゆるキャラクターの衣装変更とモーションビデオ生成を実現できることをデモで実証しています。

Outfit Anyone: Ultra-high quality virtual try-on for Any Clothing and Any Person
Project | GitHub | Demo
テキストや顔写真からダンス動画を生成するモデル「DreaMoving」、アリババグループなど開発
「Animate Anyone」や「MagicAnimate」などのモデルが登場し、画像内の人物やキャラクターを自由に動かすことが可能になっています。これらのモデルは、参照画像とポーズシーケンスを組み合わせてダンス動画などを生成します。
この文脈で、「DreaMoving」という新しい拡散モデルに基づいた制御可能な動画生成フレームワークが紹介されています。DreaMovingは、特定のアイデンティティ(例えば顔写真や全身写真)とポーズシーケンス、そしてテキストプロンプトを入力として、そのアイデンティティが踊る動画を生成できます。
入力としては、テキストのみのプロンプト、顔画像(または身体画像)とテキストのプロンプト、スタイル画像とポーズシーケンスなど、様々な組み合わせが可能です。生成される動画は精度が高く、滑らかな動きを提供します。
この目的のために、DreaMovingには動きを制御する「Video ControlNet」と、アイデンティティを保持する「Content Guider」が含まれています。このモデルは使いやすく、様々なスタイライズされた拡散モデルに適応可能で、多様な結果を生成することができます。




DreaMoving: A Human Video Generation Framework based on Diffusion Models
Mengyang Feng, Jinlin Liu, Kai Yu, Yuan Yao, Zheng Hui, Xiefan Guo, Xianhui Lin, Haolan Xue, Chen Shi, Xiaowen Li, Aojie Li, Xiaoyang Kang, Biwen Lei, Miaomiao Cui, Peiran Ren, Xuansong Xie
Project | Paper | GitHub
スマホ上で画像内の物体をリアルタイムで分離する高速処理システム「EdgeSAM」
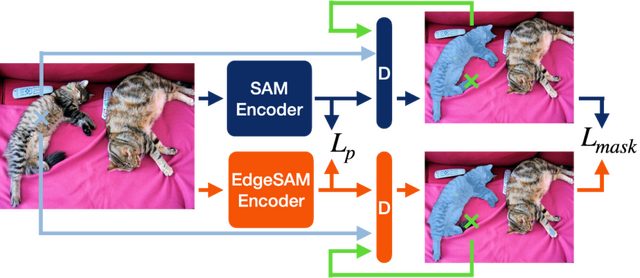
EdgeSAMは、モバイルデバイスで効率的に実行するために最適化された、画像セグメンテーションのためのプログラムです。この技術は、「Segment Anything Model」(SAM)という画像内の指定した物体を分離する画像認識システムを、モバイルデバイスに適した形に改良した高速化バージョンです。
性能の大幅な低下を抑えながら、元のViTベースのSAM画像エンコーダをCNNベースのアーキテクチャに蒸留する方法を取り入れています。この簡素化プロセスでは、ユーザーの入力と画像認識の結果の関係を正確に理解できるように工夫されています。この変換過程で生じる問題(データセットの偏り)に対処するために、特別な軽量モジュールをエンコーダに追加しています。
EdgeSAMは、元のSAMより40倍速く、NVIDIA 2080 Ti GPU上でMobileSAMより1.6倍速く動作します。またiPhone 14上では、1枚の画像をわずか14ミリ秒で処理することができ、これは同プラットフォーム上でのMobileSAMの性能の14倍の速さです。さらに、COCOとLVISというデータセットでの精度も向上しています。そして、この技術はiPhoneのようなデバイス上で、1秒間に30FPS以上のリアルタイム動作可能な画像認識を行うことができる最初のものです。

EdgeSAM: Prompt-In-the-Loop Distillation for On-Device Deployment of SAM
Chong Zhou, Xiangtai Li, Chen Change Loy, Bo Dai
Project | Paper | GitHub | Demo
スマホ上で実世界の大規模3Dシーンをリアルタイム生成できるモデル「SMERF」、Googleなどが開発
Radiance Fieldsは、3Dシーンを写実的にレンダリングするための強力な表現方法です。ニューラルネットワークに保存され、ボリュームレイトレーシングでレンダリングされます。この技術は複雑な形状や視点依存の効果を表現できますが、多くの計算資源を必要とします。画像をレンダリングする際、操作の数はピクセル数に比例するため、リアルタイムでの使用は品質、速度、またはサイズの面で妥協が必要です。
この研究では、リアルタイムで大規模な空間を高忠実度でレンダリングする新しいアプローチ「SMERF」を開発しました。SMERFは、300平方メートルまでの大規模なシーンで最先端の精度を実現します。
この方法は、2つの主要な貢献に基づいています。1つは、モデル容量を増やしつつ計算とメモリの消費を制限する階層型モデル分割スキームです。もう1つは、高い忠実度と内部一貫性を同時に達成する蒸留トレーニング戦略です。このアプローチにより、ウェブブラウザ内での完全な6自由度(6DOF)ナビゲーションが可能となり、一般的なスマートフォンやラップトップでリアルタイムにレンダリングできます。
広範な実験により、この方法は標準ベンチマークで現在の最先端技術を大規模なシーンで上回り、最先端のRadiance Fieldsモデルよりもフレームを数千倍速くレンダリングし、モバイル含む多様なデバイスでリアルタイム性能を実現できることが示されました。

SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration
Daniel Duckworth, Peter Hedman, Christian Reiser, Peter Zhizhin, Jean-François Thibert, Mario Lučić, Richard Szeliski, Jonathan T. Barron
Project | Paper | Demo