Modelに無い顔や彼女の顔を出したい!
生成AIでポートレート写真やグラビアを作っていると、同じような雰囲気の顔ばかりが結構出るのに気付く。
もちろん何パターンもあるので、毎回同じでもないのだが、XやInstagramなどの生成AI画像でよく見かける典型的なAI顔と似ているケースが多い。
美人ばかりなのでOKと言う話しもあるが(笑)、とは言え、違う顔を出したいと思う人もいるだろう。また奥さんや彼女、子供などの顔を出してみたいと言う希望もあるのではないだろうか。
これを可能にするのが顔LoRAだ。civitaiでLoRAを検索するといろいろなものが出てくる。それを使うのも一つの手だが、今回は自作してみたい。

SD 1.5 (Stable Diffusion 1.5)でも、最新の次世代バージョンSDXLでも、環境と元写真さえあれば(簡易式なら)割と簡単に作成できる。
ただ一点注意すべきなのは本人の了承を得ること。これは同じ顔で、いろいろな衣装やポーズ、アングルなどが生成できてしまうからだ。
筆者も顔LoRAを作る時は必ずモデル本人に「何が作れるか」を説明し了承を取っている。幸い知人たちは割とザックリな性格が多いので直ぐOKが出るのだが(デメリットより実現不可能なコスプレなどができる方が嬉しいらしい)、世の中そうでない人も多いだろう。
顔LoRAを作る方法は何パターンかあるが、今回はGUIを使わずコマンドラインのsd-scriptsを使用する。
用意するのも画像だけと言う簡易式だが、経験上、似た顔を出すならこれで十分な感じだ。また同じ作るなら、より似るSDXL用としたい。
学習用のWindows環境を作る
まず事前にPython 3.10.6とgitをインストールしておく。この時、Pythonのバージョンは必ず3.10.6にすること。古くても新しくても、うまく動かないなど面倒なことになる。
インストール後、PowerShellで python --version、git --version を実行し、PATHが通っているかを確認。
後はPowerShellで適当なドライブ/フォルダへ移動し以下を実行。PS D:\> や (venv) PS D:\sd-scripts> は、システムプロンプトなので入力不要だ。
PS D:\> git clone https://github.com/kohya-ss/sd-scripts.git -b v0.6.6
PS D:\> cd sd-scripts
PS D:\sd-scripts> git switch sdxlPS D:\sd-scripts> python -m venv venv
PS D:\sd-scripts> .\venv\Scripts\activate
※venvから抜けるのは deactivate
https://huggingface.co/r4ziel/xformers_pre_built/resolve/main/triton-2.0.0-cp310-cp310-win_amd64.whl
※このファイルを事前にダウンロードし、sd-scriptsフォルダへ入れておく
(venv) PS D:\sd-scripts> pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 --index-url https://download.pytorch.org/whl/cu118
(venv) PS D:\sd-scripts> pip install --upgrade -r requirements.txt
(venv) PS D:\sd-scripts> pip install xformers==0.0.20
(venv) PS D:\sd-scripts> pip install .\triton-2.0.0-cp310-cp310-win_amd64.whl
(venv) PS D:\sd-scripts> del triton-2.0.0-cp310-cp310-win_amd64.whl
※ git pullで更新する時トラブルのでインストール後消す
(venv) PS D:\sd-scripts> accelerate config
accelerate configを実行すると色々聞かれるので、
- This machine
- No distributed training
- NO
- NO
- NO
- all
- fp16
とする。これで環境の準備は完了。一見面倒そうだが、実際操作すると、コピペがほとんどなので大した手間ではない。
学習用データの準備と学習、そして確認
冒頭で書いたように今回はSDXL用で学習したい。SD 1.5でも試したが、その差は歴然。学習時間はかかるものの、生成した画像は驚くほどの激似となる。
作業用のフォルダ構造は以下のように仮定する。もちろん変えても後述する各項目を変更すれば問題無い。
D:\checkpoints\SDXL\sd_xl_base_1.0.safetensors
D:\sd-scripts\
D:\LoRA\
data\
※ここに1,024x1,024の画像が10~15枚
output\
※ここにLoRAファイルを出力する
config.toml
まず学習時にベースとなるModelはSDXL標準のsd_xl_base_1.0.safetensorsとする。SDXL用Modelであれば何でもいいのだが、多くのModelは、これを元に学習しているようなので、であれば…と言うのが筆者の考えだ。おそらく他のModelへの適応性も高くなる。
次にLoRAを作る時の学習用データはいろいろなパターンがあるのだが、顔LoRAを作るだけなら、(同一人物の)顔が構図に収まっている1,024x1,024の画像が10~15枚あればいい。
引きや寄り、上から下から後ろからなど、いくつかパターンが欲しいところだが、可能な範囲で揃えれば大丈夫。これを上記の構造だと D:\LoRA\data\ へ入れる。
もし写真に一手間かけるなら、デジイチで例えばバストアップの写真を撮ると2:3の比率の中に収まっている。これを1:1に顔中心でトリミングすると構図全てが顔になる。全身を撮ってもおそらく上半身になるだろう。そしてこの手の写真ばかりを学習させると、顔と体のバランスが崩れた絵が出易くなる。
対策としてはPhotoshopのジェネレーティブ塗りつぶしなどを使い、2:3の写真左右に余白を作り1:1としてOutpaintすることだ。上記のサムネイル画像も全身写真などはそうして左右を書き足し1:1としている。前回ご紹介したFooocus-MREやFooocusでも簡単にできるので是非試して欲しい。
学習用の定義ファイル config.toml の中は以下の様になる(#以降はコメント)。image_dir=は先の画像が入っているフォルダを指定する。
[general]
[[datasets]]
[[datasets.subsets]]
image_dir = 'D:\LoRA\data' # 学習用画像を入れたフォルダ
class_tokens = 'kaede01a woman' # identifier class
num_repeats = 10 # 繰り返し回数
class_tokens=は、ここでは kaede01a woman 。意味は前者がTrigger Word、後者が属性(woman)。Trigger Wordをkaedeではなくkaede01aとしているのは、kaedeだけだとModelによっては何か別のものを学習している可能性があるからだ。
できるだけユニークなものにするのが望ましいものの、あまりランダムな文字を並べると忘れてしまうので(笑)、ほどほどにするのが無難だろう。
準備ができたら以下のコマンドを実行する。--output_name='kaede01aXL' はLoRAのファイル名。これだと kaede01aXL.safetensors となる。Trigger Wordをファイル名の一部へ入れておくと安心だ。
(venv) PS D:\sd-scripts> accelerate launch --num_cpu_threads_per_process 1 sdxl_train_network.py --pretrained_model_name_or_path='D:\checkpoints\SDXL\sd_xl_base_1.0.safetensors' --dataset_config='D:\LoRA\config.toml' --output_dir='D:\LoRA\output' --output_name='kaede01aXL' --save_model_as=safetensors --prior_loss_weight=1.0 --resolution=1024,1024 --train_batch_size=1 --max_train_epochs=20 --learning_rate=1e-4 --xformers --mixed_precision="fp16" --cache_latents --gradient_checkpointing --network_module=networks.lora --no_half_vae
※太字にしている部分が変更可能箇所
参考までにSD 1.5で学習したい場合は、画像を512x512へ(これに伴い --resolution=1024,1024 を --resolution=512,512 へ)、学習元のModelをSD 1.5用へ、 sdxl_train_network.py を train_network.py へ、オプションの最後に --clip_skip=2 を追加すればOK。
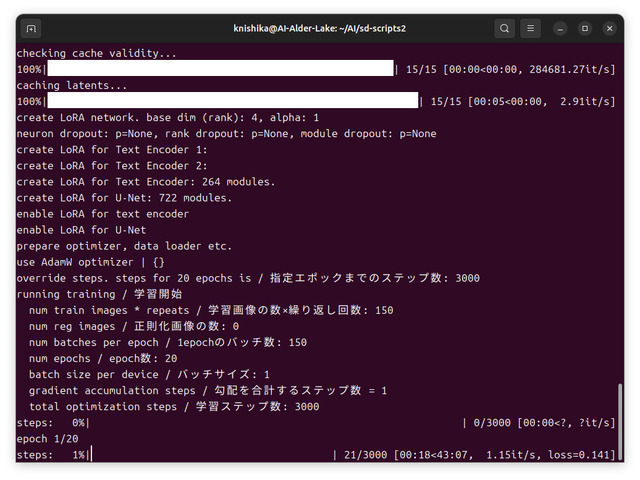
画像15枚で学習ステップ数3,000(10枚で2,000)。かかる時間はGPU性能などにもよるが、学習ステップ数3,000で1時間前後と言ったところか。
パラメータの --max_train_epochs=20 は増やすと学習ステップ数が増え、減らすと学習ステップ数が減る。試した範囲だと1,500以上でそこそこ似る感じだ。VRAM使用量は11GB前後。従ってRTX 3060(12GB)が最低ラインとなる。

¥38,398
(価格・在庫状況は記事公開時点のものです)

¥44,980
(価格・在庫状況は記事公開時点のものです)
学習が完了するとoutputフォルダに kaede01aXL.safetensors ができているので、それをWebUIのLoRAフォルダへコピー。適当にModelを選びPromptを入れる。AUTOMATIC1111だと
Photo of a japanese woman, kaede01a, … <lora:kaede01aXL:0.6>
※ Trigger Wordはどこに入れてもいいが、文頭に近い方が強くなる
的な感じになるだろうか。LoRAの重みは1だと結構ガッチリ出てしまうので0.6~0.8程度が無難。絵柄を見つつ好みの値にして欲しい。
 |  |
 |  |
モデル小彩 楓
テストで軽く出した結果はご覧の通り(ModelはCherry Picker XL)。第一回ではSD 1.5で学習させたが、全体のクオリティも含めSDXLの方が激似、そして圧倒的な絵となる。
学習用画像についての考察
上記で学習用に使う画像は10~15枚あればOKと書いた。これは実際筆者がテストした範囲の話しであり、もしかすると30枚あればもっと似るかも知れないが、現状を見る限り、個人的にはそれほど必要無いと思っている。それより自然な感じで似せるポイントは写真の質だ。
自分で撮影できない場合、ネットからダウンロードするのが一番手っ取り早いが、その画像を使っての学習することの是非は別の話しとしても、技術的な観点から以下の理由でネットにある写真を使うのはお勧めしない。
人物の商用写真(個人撮影で掲載している写真もそうだろうが)は、ほとんどが加工して盛っている。ほうれい線や眼の下のクマはもちろん、小じわなど、不自然なほどツルツルに。場合によっては眼の大きさ、鼻の形や顎のライン…修正箇所をあげだすとキリがない。それを学習するのだから肌の質感が不自然にツルツルしているのはある意味当たり前となる。
上記の修正は多くは人間の手によって行われる。従って各写真の修正内容がバラバラで学習時の特徴量が一致せず、結果あまり似なくなる。これは実際経験したことで、あるモデルから写真を受け取り、それを学習したところ全然似ない。理由は本人がアプリで(結構)加工した後の写真だったからだ。後日、筆者が直接撮影した写真をそのまま使ったところ問題なく本人に似たと言う経緯がある。
従って最適な画像は、照明なども考慮したデジイチでの撮影かつ、無修正の生画像になる(RAW現像時の明るさや色合いの調整は問題ない)。できれば白ホリのスタジオで撮影するのが望ましい。これは背景に結構引っ張られるからだ。衣装も同様なのだが、流石に何も着ないわけにもゆかない。とは言え、それなりに肌露出している方がよりベター。
実際例をあげてみたい。この2つの写真は、左がModel(Cherry Picker XL)そのまま、右が同じPromptで筆者が作った今回とは別の顔LoRAを当てたもの(元画像は白ホリのスタジオで撮影)。かなり違うのがお分かり頂けるだろうか(色合いなどはある程度揃えている)。
 |  |
画像生成Modelを作るにあたり、数千や数万枚もの写真を自前で揃えるのは非常に難しい。よっていろいろなところからかき集めていると思われるが、だとすると上記のような学習元による問題を抱えることになる。対して筆者のLoRAは筆者撮影の生画像を使っているため、肌の質感なども含め自然に出ているのが分かる。
おそらくSD 1.5では学習時の画像が512x512だったので、分解能も低く気にならなかったが、SDXLでは1,024x1,024となり、表面化した問題のような気がする。とは言え、あくまでも筆者の経験上からの仮説だ。
最近リアル系ModelのUpdateを試すと、SDXL特有の肌ツルツル感は薄れ自然な感じになってきている。おそらく、学習する元画像に変更を加えたのだろう。半年も経てばそんな話もあったね…的な昔話となりそうだ。
今回の締めのグラビア
締めのグラビアはここで作った顔LoRAを当てたものとなる。使用したModelはSDXL Yamer's Realistic。832x1,216で生成し、x1.7でUpscale、長辺を1,920へ縮小、短辺を1,280にトリミングして2:3へ、若干のシャープネスとノイズを乗せると言ういつものパターンだ。

この一枚、実際に撮れなくもないが、かなり大変なのは容易に想像つく。(少し指は怪しいが)扉のHalloweenっぽいのも今回の顔LoRAを使用した(ModelはCherry Picker XL)。
冒頭にも書いたように、顔LoRAさえあればどんなコスプレやロケーションにも対応可能…というのも生成AI画像の面白さの一つだろう。
さて、顔LoRAの作り方と言うことで内容的に写真が少なく文字ばかりで、面白くなかった人も多いのではないだろうか。次回は写真多めのModelやLoRAの紹介に一度戻るかも…!?