




画像生成は出来たけど…何かもう一捻りしたい!
自分でも生成AI画像を作ってみたい人向けに、これまでAUTOMATIC1111とFooocus、そしてFooocus-MREとご紹介した。おそらくPromptを使って出したい絵がそれなりに生成できたのではないだろうか?


今回はそれだけでは面白く無いので、元画像を絵柄そのまま高精細なフルHDにアップスケールしたい、もしくはそのまま使って絵を変えたい、構図やポーズをある程度固定したい、Photoshopのジェネレーティブ塗りつぶし的な機能は?…と言った、もう少しStable Diffusionっぽい使い方を順に説明する。
image-2-image / Upscale
Promptから画像を得る方法を一般的にText-2-Imageと呼んでいる(txt2imgやt2iとも)。文字通りテキストから画像を…と言う意味だ。
Stable Diffusionでは、加えて画像から画像を得る方法があり、これをImage-2-Imageと呼んでいる(img2imgやi2iとも)。言葉よりも画像の方がより多くの情報を持っているので、それを使おうと言う意図だ。
これまで生成した画像の解像度は、832✕1,216や1,024✕1,024など、決まった解像度になっているはず。これはSDXLが生成するにあたって最適な解像度を使っているためだ(SDだと512✕768や512✕512など)。
ではそれ以外の解像度を指定するとどうなるか?試して見ると分かるが、胴体が異様に長かったり、変なところから顔がもう一つ出たり、かなりオカルト的になる可能性が高い。
もっと大きい、例えばフルHDなどの画像を得るにはどうすれば?と言う疑問を持つ。筆者も当初、1,920✕1,080など入れて試したことがあるものの、結果はメモリ不足か、先にあげた様に変な画像が出来上がる。
そこで登場するのがimage-2-imageのUpscaleだ。元画像をメモリが許す限り、絵柄そのまま大きな解像度で生成できる。
Fooocus-MREでは、解像度を直接入れるのではなく、image-2-imageタブのImage-2-Image Scaleを使う。フルHD相当だと、気持ち大きめだがx1.7に設定すると、832✕1,216の元画像が1,408✕2,064に高解像度化できる。
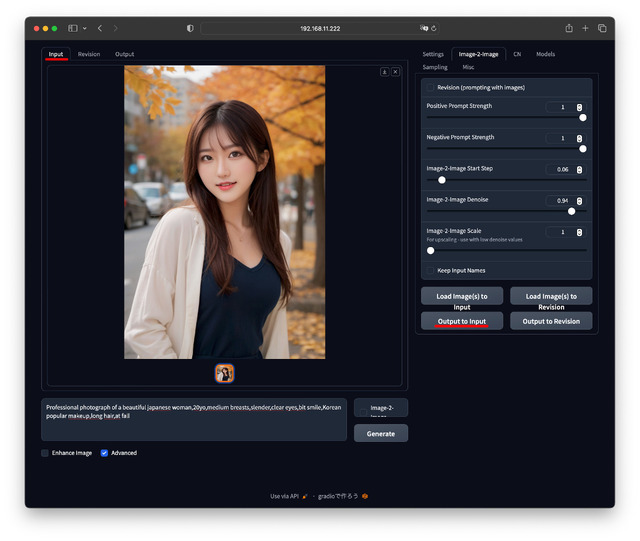
方法としては、いま生成した画像をそのまま大きくしたい時は、image-2-imageタブの下にある[Output to Input]ボタンを押す。
保存済のものを元画像にしたい場合、その上にある[Load images(s) to Input]を押しファイルを指定する。これで左上のInputタブに画像がセットされるはずだ。
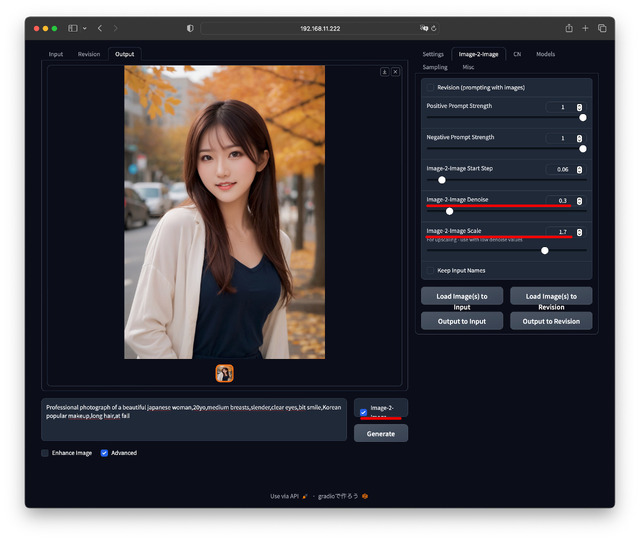
次はImage-2-Image Denoise。これは単に引き伸ばすと間がスカスカになるので、周囲の絵を参考にしつつ追加書込する時のパラメータだ。
デフォルトでは0.94と大きめの数値になっているが、これだと顔が大幅に変わってしまうので、筆者はいつも0.3をセットしている。この辺りは好みや絵柄もあるので、0.1刻みで試して欲しい。
そして先に上げた倍率、Image-2-Image Scaleをセットする。元画像が832✕1,216ならフルHD相当は1.7となる。
実行は[Generate]ボタンの上にある[image-2-image]にチェックを入れてから[Generate]ボタンを押す。しばらくすると、大きくなった画像が[Output]タブに出ているはずだ。
画像は、[Fooocus-MREを入れたフォルダ]/outputsの下にyyyy-mm-ddのフォルダがあるのでその中。
またlog.htmlは各画像生成時のいろいろなパラメータが画像と共に記録されている。Chromeなどでそのまま開くので興味のある人は見て欲しい。
image-2-image / +Prompt
image-2-imageのもう一つの機能として、Promptを追加することで元画像を変化させる事ができる。例えばカフェの背景をビーチにすることも。
先のUpscaleでは、Image-2-Image Denoiseを0.3程度にしないと…と書いたが、今度は逆に大きめにする。効き具合は0.6辺りから0.1ステップで順に試す感じだろうか。
但し顔は変わる。ここは諦めるしかない。別に生成して切り貼りや、後述するInpaintで対応もできなくはないが、時間と手間を考えると再生成したほうが効率的だ。
また効き過ぎると全く違う構図になってしまうので丁度良いところを探すことになる。

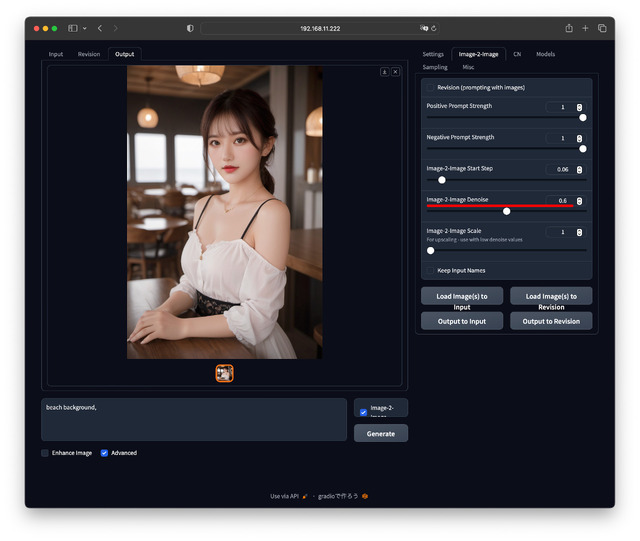
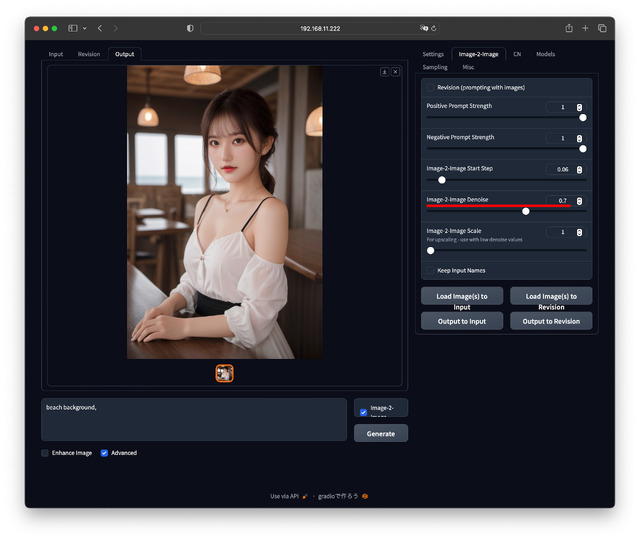
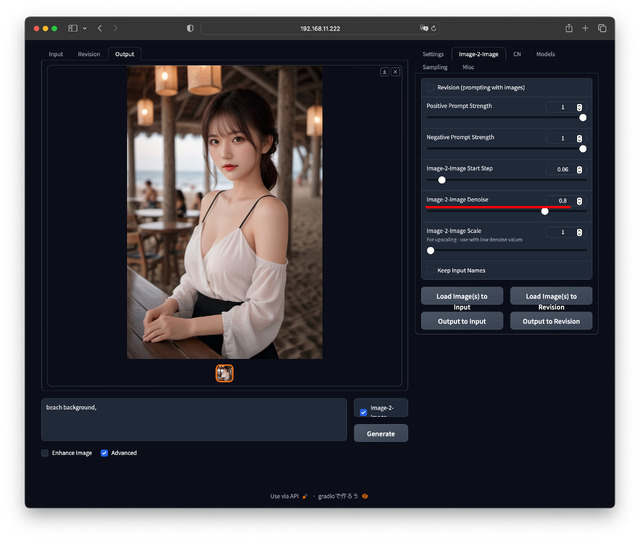
Promptは例えば beach background とする。これもUpscaleと同じく[image-2-image]へチェックを入れ、[Generate]ボタンを押す。Promptで指定した内容に(ほどほどに)変わっていれば成功だ。
なお、以降解説する機能については、[image-2-image]へチェックは入れないので注意して欲しい。
ControlNetのCannyとDepth
ControlNetとは…を説明すると難しく且つ長くなるので省略するが(筆者も完全には理解していない)、Cannyは線でDepthは深度で絵柄をある程度固定できる。
論より証拠。以下3枚の画像を見て欲しい。順にオリジナル画像、オリジナルを元にしたCannyデータ、オリジナルを元にしたDepthデータとなる。

Fooocus-MREのControl-LoRA: CannyとDepthは、この変換後の情報とPromptを組み合わせて絵柄を出す仕掛けだ。
ただこの変換後の画像を作るには一手間かかるので(AUTOMATIC1111のControlNetで作成可能)、普通の絵をInputにセットすれば大丈夫な様になっている。
もちろん変換後の画像でも問題無く、特にCannyの方はちょっと絵心ある人なら手書きでも行けそうだ。CNタブにControl-LoRA: CannyとDepthがあるのでどちらかにチェックを入れて、Promptを入力、[Generate]ボタンを押す。上記のオリジナル画像を使った生成結果は以下の様になる。
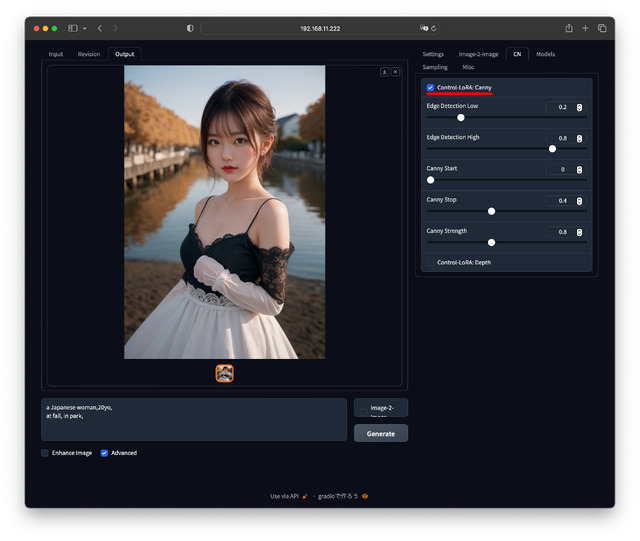
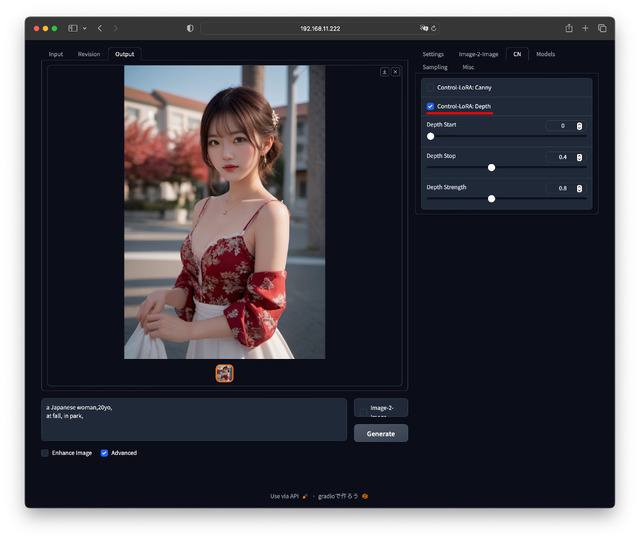
如何だろうか。以前ご紹介したOpenPoseよりもっと絵柄を忠実に固定できる。なおCannyは顔の輪郭まで線が入っているので、違う顔にしたい時はDepthの方が無難かも知れない。
Inpaint / Outpaint
このInpaint / Outpaintは、本家のFooocusに搭載され、Fooocus-MREにマージされた機能だ。
image-2-image関連が二箇所に分かれるのでUI的には微妙なのだが、先とはまた違うUpscaleとInpaint / Outpaintに対応し、左下にあるEnhance Imageをチェックすると現れる。
Inpaint / Outpaintは、最近話題になっているPhotoshopのジェネレーティブ塗りつぶしと同じだ。絵の中の特定部分を別のものに書き換えるのがInpaint、元絵の上下左右に余白を付けサイズを広げ、そこを書き加えるのがOutpaintとなる。
Inpaintは書き換えたい部分を塗り潰す。Outpaintは広げたい部分のLeft、Right、Top、Bottomにチェックを入れる。実行前と実行後で一目瞭然。手作業でやろうとすると不可能に近い処理がほんの数十秒。驚くべき機能だ。
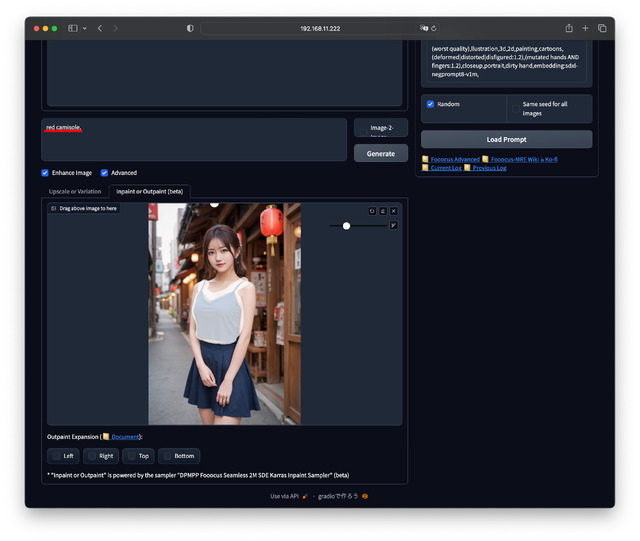
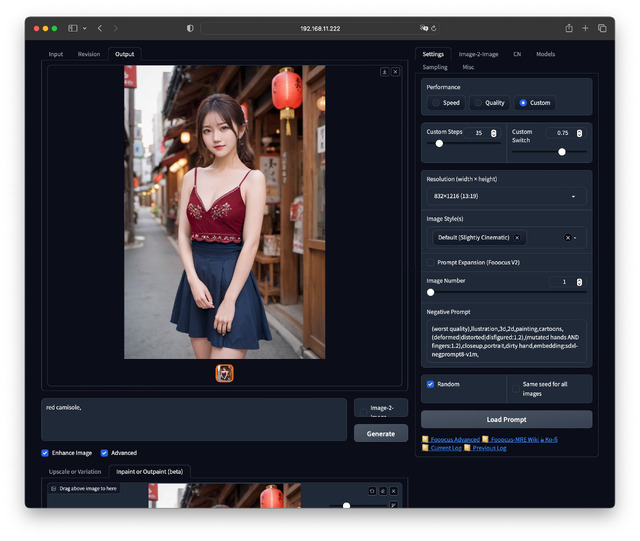
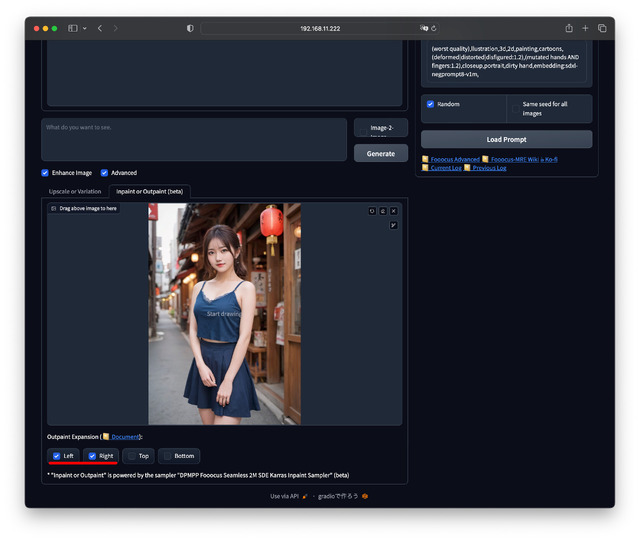
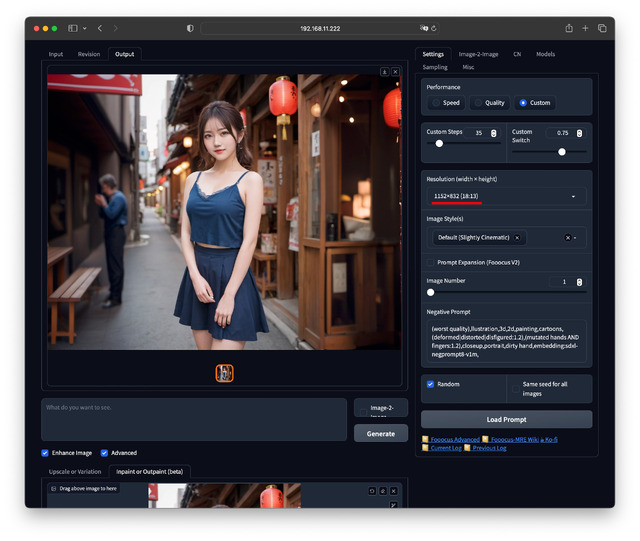
image-2-image / +Promptでのカフェの背景をビーチにするパターンもInpaintで被写体の周囲を塗り潰せば対応でき、こちらは顔や衣装、構図/ポーズなどは変わらない。どちらを使うかは欲しい絵柄次第と言ったところ。
もちろん何をしてもPhotoshopのジェネレーティブ塗りつぶしの様に「規約違反」は出ないのでご安心を(笑)。この点はローカルで動かす強みでもある。
Revision (prompting with images)
元画像から新しい画像を作ると言う意味では、image-2-image / +Promptと似ているが、仕掛け的には全く違うのがRevision。上記でも少し触れたが、テキストより絵の方が情報量が多く、それをPromptにすると言うものだ。最大4枚の絵からPromptを得ることが出来る。

元画像はありがちなランチ中のテーブルの上(実写)。これを[Output to Revision]もしくは[Load Image(s) to Revision Output to Input]でRevisionタブへセット。
Revision (prompting with images)にチェックを入れ、Revision Strength for Image 1: 1, Positive Prompt Strength: 0(つまりPromptは無し)で生成すると、なるほど、元画像からPromptを作った的な絵柄になる。更にPositive Prompt Strength: 0.4, Prompt: cakeとすると先の雰囲気のままケーキが出てきた…と言う具合だ。
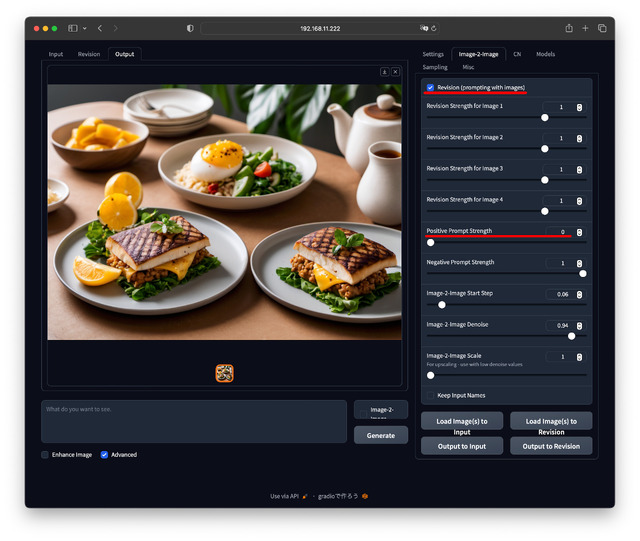
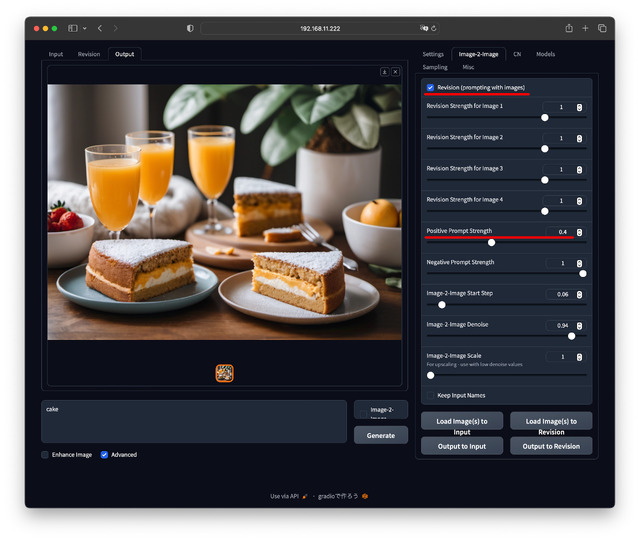
この時、Revision Strength for Image 1が-2~+2、Positive Prompt Strengthが0~+1の設定が可能。指定できる数値の幅が広すぎるのと、全部で4枚画像を使えるなど、やり過ぎ感がしないでもない。
筆者的にこれをどう使えば効果的かイマイチ良くわからないものの、面白い機能だとは思う。
今回の締めのグラビア
以上のような機能を使うことにより、単純にPromoptで書くより、更に絵柄の幅は広がるのがお分かり頂けただろうか。
特に構図やポーズなどはPromptで書いてもなかなかそうならず結構イライラするが、CannyやDepthを使えば一撃で終わる。
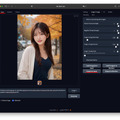
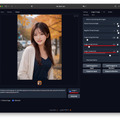
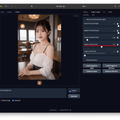
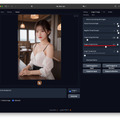
今回はFooocus-MREのControlNet / Depthを使ったグラビアとなる。元絵は前回のグラビア。これをInputに入れ、ModelにRealVisXL V2.0、顔LoRAにayame_LoRAを使用した。ぱっと見、実写ではと思うほどの出来だ(扉の写真はまた別の設定)。
仕上げはimage-2-image2のUpscaleでx1.7とし、Photoshopで長辺を1,920へ縮小、短辺を1,280にトリミングして2:3へ。気持ちシャープネスとノイズを乗せている。

3回続けて生成環境の話しになったので、次回からはまた初心に戻ってModelやLoRAの話しにするか、最近AnimateDiff(Promptによる動画生成)が凄いことになっているので本連載の趣旨から少し外れるもののそれか、sd-scriptsを使ったLoRAの作り方…のどれかを考えている。お楽しみに!













