



AIを使った歌声合成(というか声質変換)の最新手法である「Diff-SVC」を始めました。

Diff-SVCは、Diffusion model Singing Voice Conversionを意味します。画像生成AIソフトウェアであるStable Diffusionと同じく、Diffusionモデルという流行りの機械学習の手法を用いたものです。
その前にまずは結論から。これはとてもやばい、破壊的な技術です。
AI美空ひばりやAI荒井由実など、すでに失われた歌声をリアルに再現する手法は、多大な投資や丹念な調整、多くの人の労力によって可能となるもので、普通の人が気軽にできるものではありません。

それを、完全とは言えないまでも、かなり元の人に肉薄する品質で再現できる技術がDiff-SVCです。元になる音声データが1時間くらいあれば、与えた音声を、希望する声質に変換することが可能になるのです。
しかも、基本的にお金はかかりません。AI歌声合成が、ちょっとハードルは高いものの、無料で使えて、データさえ集めてくれば誰でも手が出せる。AI歌声合成の民主化と言っていいでしょう。
筆者は10年近く前に旅立った妻の歌声を、UTAU-Synthという、短く切り出した音素をピッチや長さを合わせながら組み合わせていくソフトウェアで再構成しています。1フレーズずつ音素を繋いで、できるだけ不自然にならないように調整していくため、短くて数日、長いと数カ月も時間をかけて完成させていきますが、もうその作業をしなくてもよくなります。
ただ、自分で歌って、もしくは他のボーカルシンセソフトでボーカルトラックをDiff-SVCで変換すれば、本人との区別がつきにくいレベルの歌唱データが得られるというわけです。
では、その音質はどうなのか。
筆者が10年くらい前に歌ったボーカルデータをDiff-SVCによる妻のAIモデルによって変換して作ったのが、次のカバー曲です。
一番低いピッチでは少し掠れていたり不自然なノイズが乗っていますが、ファーストテイクとしては、なかなかの出来栄えではないかと思います。エフェクトはリバーブをかけたくらいで、ピッチやタイミングの調整もしていません。
そんなわけで、前回は予告だけだったのですが、その直後にGoogle Colab(Proの有償プラン)で環境を構築し、ソフトウェアのインストール、データ収集、学習をし、音が出せるところまで行けたので、その流れを一通り紹介していきたいと思います。
Diff-SVCをGoogle Colabで使う
機械学習を(比較的)気軽に行うための環境としては、Google Colab(Colaboratory)が有名です。Diff-SVCでも、Google Colab用のプロジェクトが用意されており、基本的にはGoogle Colabの中だけで作業が完結します。
アマノケイさんの解説記事を見ながら進めていきます。
また、Greta GreenteethさんがYouTubeに動画をまとめてくれているので併せて見ておくといいでしょう。
Google Colabで指定されたNotebookをローカルにコピーし、Ubuntuの仮想マシンを立ち上げてPythonなどの必要なソフトウェア群を大量にインストールしていくのですが、必要なパラメータを記入する、メニューから選択する、▶️ボタンを押す、という作業だけで済みます。上から下に進めていくだけです。
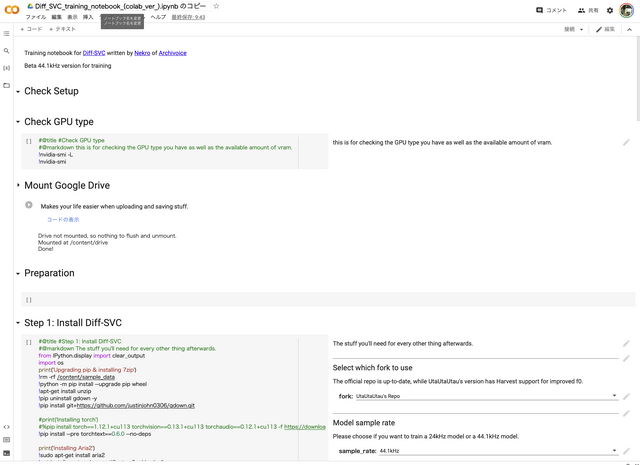
▲コマンドラインを使わずに、GUI操作だけで進められる
Google Driveを接続することで、学習させるデータ、出来上がってきた中間ファイルや音声モデルとのやりとりをします。筆者はGoogle Driveの容量は有償プランにしていますが、ストレージに余裕はあったほうがいいでしょう。
Google Colabは基本無料ですが、接続時間やGPUの使用など、有償プランの方が、非常に時間がかかる機械学習には便利だということで、月額980円のProプランにしました。
音声データを用意する
さて、Google Colab上で作業をする前にやっておかなければならないことがあります。学習用の音声データを用意することです。
アマノケイさんのアドバイスに従い、1時間分の音声ファイル(44.1kHz)を用意します。これは、同じ話者、シンガーのものであれば、歌唱音声、おしゃべり、その音声を元にした例えばUTAUの歌唱データでもいいそうです。筆者は、妻が遺した3曲分のボーカルデータはすでにUTAUのために音素で細分化しているので、それをそのまま使用。さらに、まだUTAU用に使っていない学生時代の歌声、ビデオテープに残っている比較的クリーンな会話音声、そして、妻音源とりちゃんの歌唱データなどを1つのフォルダにまとめました。1時間分ということは、約300MBということなので、そのくらいまでデータを増やしていきます。
ただし、例えば1時間分の歌唱ファイルがあればそれでいいというわけではなく、これを最大20秒の長さの44.1kHz wavファイルにスライスする必要があります。UTAUの歌唱データの1フレーズ分が20秒以下のものはそのまま使い、それでも足りない時にはAudacityで手動でファイルをエクスポートしていきます。会話音声も同様。2時間くらいかけて、全作業を終え、これをzipにアーカイブして、Google Driveの指定の場所に置き、そのパスをGoogle Colabに記入し、事前学習データのアップロードを行います。
▲ビデオに残された会話の断片も学習データに
そして事前学習が始まるのですが、ここで問題が。読めないファイルがありますとエラーを吐いて停止してしまいます。問題となっているのは「Mac OS X」という名前が含まれているファイル。macOSでzipアーカイブすると、そこに入ってしまう特殊ファイルが悪さをしているわけです。
Google Colabのターミナルから問題のファイルやフォルダを消去すればいいのですが、ターミナルがあることすらわかっていなかったので、何度もやり直してしまいました。基本的なことがわかっていない状態でしたが、それでもなんとか事前学習を終えます。
最後の難関が、学習(本番)です。これには数時間から数十時間がかかります。筆者の場合は20時19分に学習をスタートして、翌朝までかかってもさらに続いていました。モデルはきりのいい数字(ステップ数)をつけたものがGoogle Driveに生成されていきます。ファイルサイズはそれぞれ370MBくらい。数字が多い方が精度が高いものになっています。学習はまだ続けられますが、その最大のモデルを歌声変換に使います。一番進んだモデルが150000stepsで、17時間くらいかかっています。
▲生成された学習済みモデルたち
とりあえず学習はここまで。歌声変換にはまた別のNotebook「Diff_SVC_Inference.ipynb」をGoogle Colabで使います。
いよいよ歌声生成
ようやく歌声を変換できるときが来ました。しかし、このNotebookでもUbuntuでのソフトウェアインストールをし、Google Driveをアタッチするという作業をする必要があります。そしてモデル「model_ckpt_steps_150000.ckpt」を指定し、元になる歌声のwavファイルをアップロードします。
この作業はインタラクティブにやるには面倒なので、できるだけファイルは1つにまとめた方がいいでしょう。今回は3分以上の曲を全部歌い、さらにある程度の調整もした上でwavにしました。
Diff-SVCの変換は意外と短く、2分ちょっとで終わりました。Yesterday Once Moreでは1分10秒。
▲Yesterday Once Moreの1番だけの生成には1分10秒かかった
そのファイルをDAW(Logic Pro)に持っていって、さらにピッチやタイミングの調整を行なったものが、こちらの動画です。
かなり自然にできていると思うのは贔屓目(耳)でしょうか。元歌(自分)がもっとうまかったらさらに安定するでしょうが、この場合には自分でやることに意味があるかな、と考えてOKにしています。とはいえ、妻の音域の上の方はさすがに出ないので、キーを変えて戻したり、部分的にVOCALOIDなどのボーカルシンセを元歌唱として使うなども検討したいです。
UTAUでやっていたときは、特に英語曲で、不足している音素をやりくりしたり、低音の処理がノイジーになったりと、限界を感じていたのですが、それらが全て取っ払われた感じです。
まだバラードを2曲やってみただけなので、その性能限界がどの辺にあるのかはわかりませんが、これが基本無料でできるというのはかなりの衝撃ではないでしょうか。
ボイチェンを歌唱合成と呼んでいいのかという問題はあります。それでも結果的にちゃんとした歌にはなっているので、よしとしましょう。
筆者の場合には大絶賛で、これからの音楽活動には欠かせないものになるでしょうが、一方でこれによって影響を受ける人も出てくるでしょう。例えば有名な歌手のボーカルデータを学習させて、全く違う歌をうたわせたり、権利者のいるボーカルシンセの歌声をDiff-SVCに学習させたりというのたまに見かけます。これは問題化しそうです。
Diff-SVCは破壊的な技術であるだけに、その使い方には気をつけないといけません。
そんなわけで、妻が遺した歌声を元にした合成音声「妻音源とりちゃん」は、自分の声を妻の歌声に変身させる「妻音源とりちゃん[AI]」として、第2段階に進むことになりました。呪文(プロンプト)で異世界から妻の画像を呼び寄せる「異世界とりちゃん」と併せて、後ろ向きに全速力で進みたいと思います。
調整があまりにも簡単なので、どんどんできてしまいます。また1曲、妻音源とりちゃん[AI]が歌った曲です。今度は筆者とデュエットしています。
追記:と思ってたらこれですよ……。


¥57,700
(価格・在庫状況は記事公開時点のものです)



¥17,599
(価格・在庫状況は記事公開時点のものです)


















