


マイクロソフトが、たった3秒間のサンプル音声から誰かの声をシミュレートし、テキストを読み上げさせられる音声AI「VALL-E」を公開しました。
この音声AIは単に声色を似せるだけでなく、抑揚や周囲環境をカスタマイズして喋らせらることも可能なため、使い方を誤ればティープフェイクの音声版にもなり得ると研究者は述べています。
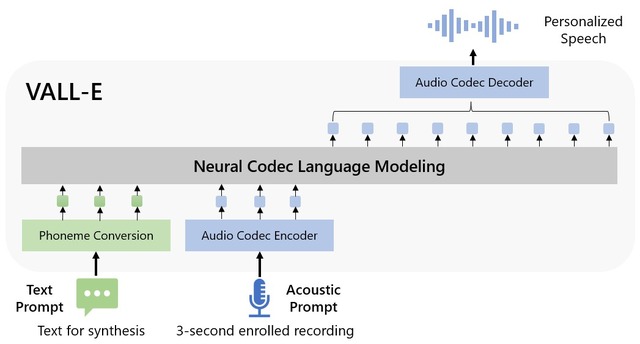
通常の音声合成は、音の波形を操作編集して目的の音声を作り出しますが、VALL-Eは何かを喋っている音声データとテキストを組み合わせて個別の音声コーデック用のデータを作り出す「neural codec language model」と称する言語モデルです。
Metaが開発したニューラルネットワークを使用した音声技術「EnCodec」をベースにしていて、基本的には人の声を分析し、その情報をEnCodecによって「トークン」と呼ばれる個別の要素に分解。そこに学習データを用いて、3秒間の音声サンプルに含まれていないフレーズをしゃべった場合にどのように聞こえるかを再現します。
学習データには、こちらもMetaが構築したオーディオライブラリ「Libri-Light」が用いられています。このライブラリには7000人以上、6万時間におよぶ英語音声が収録されています。この音声データはパブリックドメインのオーディオブック「LibriVox」を元ネタにしているとのこと。
大量の音声サンプルによる学習は、VALL-Eが3秒サンプルと同じように聞こえる声を再現するため、学習データの中から似た声を探し出す過程に不可欠とされています。
大量の学習データを用いたおかげで、VALL-Eの紹介サイトで試聴できるたくさんの合成音声はどれも本物と聞き分けられないほど同じ声で、流暢に話すことが確認できます。
このページではVALL-Eが音声を真似るための3秒間のサンプル音声が「Speaker Prompt」、サンプル音声の人物が、比較のためにVALL-Eが合成するのと同じ文章を話した音声を「Ground Truth」、従来の音声合成で作った音声を「Baseline」、そしてVALL-Eが出力した音声を「VALL-E」として並べ、聞き比べられるようにしています。
なお、VALL-Eはサンプルの声色だけでなく、音声の収録環境の特性や、周波数特性を再現することもできます。たとえば電話音声をサンプルにすれば、電話で話したような声を再現でき、話し方に怒りや冷静さ、呆れた様子などのニュアンスを混ぜ込んで再現することも可能になっています。
つまり誰かの短い音声サンプルさえあれば、まったく話した覚えがない内容を、感情を込めて本人そっくりに話したような音声が合成可能です。このため、誰かに対していたずら目的や、さらに悪意を持った、誤った使い方ができてしまうことも意味します。
研究者らは、この技術が社会的に害をもたらす可能性を認識しており、そのコードを公開することは差し控えているとのことです。また、AIモデルの開発については今後もマイクロソフトが自主的に定める「責任ある AI の原則」を実践していくとのこと。















