








生成AIグラビアをグラビアカメラマンが作るとどうなる? 連載記事一覧
Qwen-Image-2512リリース!
筆者は毎年大晦日に帰省(関西)するのだが、夕方のんびりスマホを眺めていると”Qwen-Image-2512リリース”の文字が! 寝耳に水で、え”という感じだ。
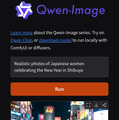
当然GPUが使える環境もなくスマホのみ。試そうにも試せない。そこでデモサイトでとりあえず試したのが以下の画像(笑)。
 |  |
Qwen-Image-2512のデモサイト(スマホから)
生成結果
人物はともかく渋谷の街の再現性はなかなか凄い。ただHugging FaceのZeroGPU Spacesはフリーアカウントだと1日何回も使えず結局出たのがこの1枚だけ(2枚目はエラーで表示されず。が、これもGPUは使ったのでこれ以上は生成できなかった)。明けて元旦はさすがに触ってる時間もなく、夜に戻って(つまり一泊二日)いろいろ試したのは言うまでもない。
余談になるが、このWebUIのコードには拡張Promptのロジックも仕込まれており、そのまま抜き出し、LM_StudioなどのSystem Promptへ設定すれば(使用するLLMにもよるが)、Promptを拡張できる。環境のある人はぜひ試してほしい。
QwenのBLOGによると主なチューンポイントは、
強化された人間のリアリズム: 「AI 生成」の外観を大幅に削減し、特に人間の被写体に対して全体的な画像のリアリズムを大幅に向上
より細かい自然の詳細: 風景、動物の毛皮、その他の自然要素のより詳細なレンダリングを実現
テキスト レンダリングの改善: テキスト要素の精度と品質が向上し、レイアウトが改善され、より忠実なマルチモーダル (テキスト + 画像) 構成を実現
この3点。どれも本当であればかなり効果的な改良となる。なおComfyUIのWorkflowは、Qwen-Imageのものをそのまま流用。checkpointとLoRAだけQwen-Image-2512に入れ替えたものとなる。
人物のリアリティは!?
まず人物のリアリティから。Promptは先のBLOGからそのままコピペ。またほぼ同時に4 steps LoRAが2種類リリースされたので、これも一緒に並べてある。
Prompt(Negativeは空):
A 20-year-old East Asian girl with delicate, charming features and large, bright brown eyes—expressive and lively, with a cheerful or subtly smiling expression. Her naturally wavy long hair is either loose or tied in twin ponytails. She has fair skin and light makeup accentuating her youthful freshness. She wears a modern, cute dress or relaxed outfit in bright, soft colors—lightweight fabric, minimalist cut. She stands indoors at an anime convention, surrounded by banners, posters, or stalls. Lighting is typical indoor illumination—no staged lighting—and the image resembles a casual iPhone snapshot: unpretentious composition, yet brimming with vivid, fresh, youthful charm.
 |  |
 |  |
Qwen-Image-2512 (40 steps, cfg 2.5)
Qwen-Image (40 steps, cfg 2.5)
Qwen-Image-2512 + Qwen-Image-2512-Lightning-4steps-V1.0-bf16
Qwen-Image-2512 + Wuli-Qwen-Image-2512-Turbo-LoRA-4steps-V2.0-bf16
見るかぎりQwen-ImageとQwen-Image-2512の差は歴然。Qwen-Imageの顔も嫌いではないが、Qwen-Image-2512の方はかなりリアルになっている。
4 steps LoRAは、Lightningは、オリジナルに忠実だが少し書き込み量が(髪の毛など)不足気味。Wuliの方はパキッとするものの、オリジナルにはあまり忠実ではない……というところか。これは好みもあると思うのでどちらが良いという話ではない。ただ今回はオリジナルに忠実という意味で、以降はLightningを使っている。
テキストの整合性は!?
次はテキストの整合性テスト。これもBLOGのPromptを使っているが、そのままだと表示する文字が中国語で良く分からないので(笑)、英語に変換したものを使用した。
Prompt: (Qwen-Image-2512-Lightning-4stepsを使用)
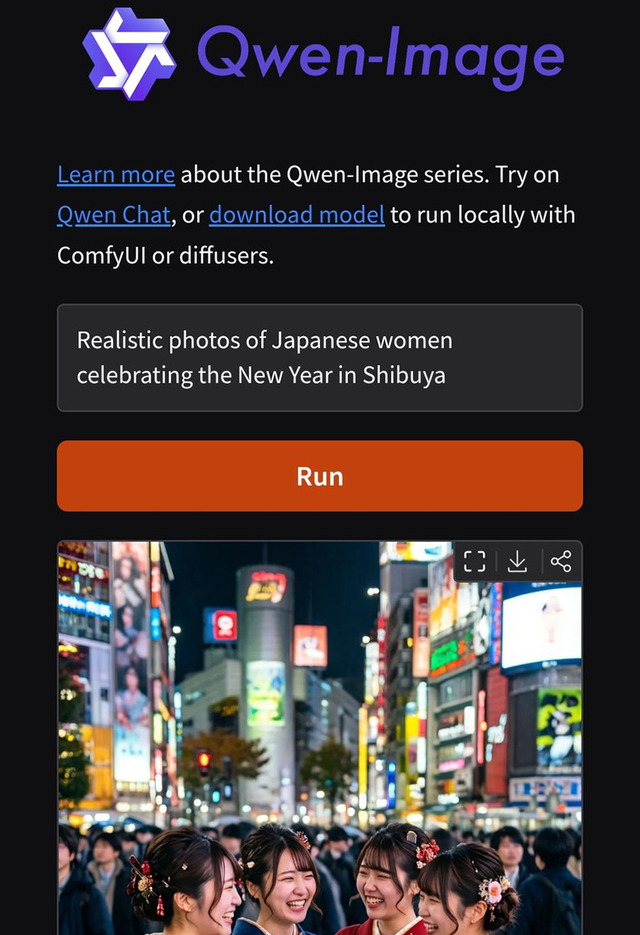
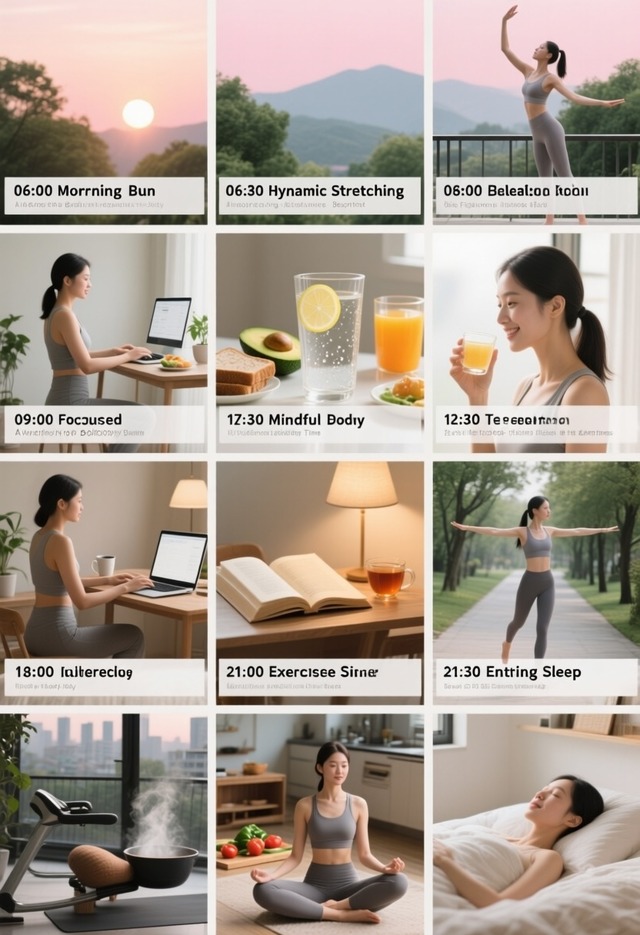
这是一幅由十二个分格组成的3×4网格布局的写实摄影作品,整体呈现"A Healthy Day"主题,画面风格简洁清晰,每一分格独立成景又统一于生活节奏的叙事脉络。第一行分别是"06:00 Morning Run Awakens the Body":面部特写,一位女性身穿灰色运动套装,背景是初升的朝阳与葱郁绿树;"06:30 Dynamic Stretching Activates Joints":女性身着瑜伽服在阳台做晨间拉伸,身体舒展,背景为淡粉色天空与远山轮廓;"07:30 Balanced Nutritious Breakfast":桌上摆放全麦面包、牛油果和一杯橙汁,女性微笑着准备用餐;"08:00 Hydration and Moisture":透明玻璃水杯中浮有柠檬片,女性手持水杯轻啜,阳光从左侧斜照入室,杯壁水珠滑落;第二行分别是:"09:00 Focused Productive Work":女性专注敲击键盘,屏幕显示简洁界面,身旁放有一杯咖啡与一盆绿植;"12:00 Mindful Reading Time":女性坐在书桌前翻阅纸质书籍,台灯散发暖光,书页泛黄,旁放半杯红茶;"12:30 Afternoon Leisurely Stroll":女性在林荫道上漫步,脸部特写;"15:00 Tea Fragrance in the Afternoon":女性端着骨瓷茶杯站在窗边,窗外是城市街景与飘动云朵,茶香袅袅;第三行分别是:"18:00 Exercise Releases Stress":健身房内,女性正在练习瑜伽;"19:00 Delicious Dinner":女性在开放式厨房中切菜,砧板上有番茄与青椒,锅中热气升腾,灯光温暖;"21:00 Meditation for Sleep":女性盘腿坐在柔软地毯上冥想,双手轻放膝上,闭目宁静;"21:30 Entering Sleep":女性躺在床上休息。整体采用自然光线为主,色调以暖白与米灰为基调,光影层次分明,画面充满温馨的生活气息与规律的节奏感。
以下、表示部分のリストアップ。
"06:00 Morning Run Awakens the Body"
"06:30 Dynamic Stretching Activates Joints"
"07:30 Balanced Nutritious Breakfast"
"08:00 Hydration and Moisture"
"09:00 Focused Productive Work"
"12:00 Mindful Reading Time"
"12:30 Afternoon Leisurely Stroll"
"15:00 Tea Fragrance in the Afternoon"
"18:00 Exercise Releases Stress"
"19:00 Delicious Dinner"
"21:00 Meditation for Sleep"
"21:30 Entering Sleep"
 |  |
 |  |
Qwen-Image-2512 (40 steps, cfg 2.5)
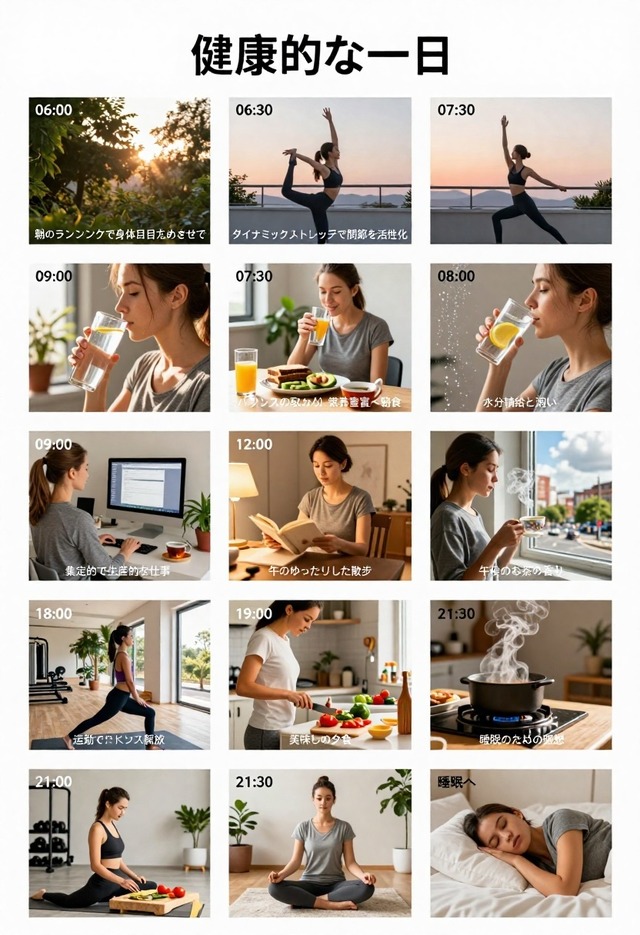
Qwen-Image (40 steps, cfg 2.5)
Qwen-Image-2512。""内日本語 (40 steps, cfg 2.5)
Z-Image-Turbo。""内日本語 (9 steps, cfg 1)
これもQwen-Image-2512の圧勝。Qwen-Imageは見るからに性能が劣る。後2枚は日本語で試した場合のQwen-Image-2512とZ-Image-Turbo。どちらもイマイチだが、前者の方がまだ何とか…というところか。この辺りは20Bか6Bかの差もあるだろう。いずれにしても英語と中国語以外はまだまだ……。仕方ないといえば仕方ない。
作例
以下は作例を6つ。4 steps LoRA以外は何もLoRAを当てていない状態。それでこれだけ出れば……という感じだろうか。ただZ-Image-Turboと比較して、丸みや奥行きがある半面、まだちょっとCGっぽさが残っている。この辺りは実写から肌を学習したLoRAを別途用意すれば変わりそうな雰囲気だ。
 |  |
 |  |
 |  |
なお解像度が同じ場合の生成時間は4 steps LoRAを使うと、Z-Image-Turboとほぼ同じ。ただしstep数が4 stepsと9 stepsなので、Qwen-Image-2512の方が少し重い。
Lightningは近々8 steps LoRAを公開する予定となっている。筆者は元々Qwen-Imageの時、8 steps LoRAを使っていたので対応版が待ち遠しい。8 stepsになれば書き込み不足もかなり低減されるはずだ。
いずれにしても出てすぐでこの状態。今後CivitaiなどでFTされたモデルが出るのが楽しみと言えよう。
もちろん高速で生成可能なNunchakuも対応してほしいところだが、未だにQwen-Image-Edit-2511にも未対応のまま。最近Nunchakuの対応が遅くZ-Image-Turboもやっと先日OKとなった。またComfyUIをUpdateすると動かなくなったり…この辺りもう少し何とかしてほしいところ。
今回締めのグラビア
扉とグラビアはもちろんQwen-Image-2512を使用。Promptもほぼ同じで横位置用と縦位置用で主にポーズだけを変えた。加えてai-toolkitがほぼ同日Qwen-Image-2512に対応したのでいくつか顔LoRAを作り、それを肌LoRA(0.4)的に当てている。
余談になるが12月にDGX Spark互換機を購入(4TB)。最近はLoRA学習環境にもなっている。というのもほぼ無音、発熱も少なく、消費電力は50Wちょい。RTX4090やRTX5090と比較すれば数時間余計にかかるものの、終わるまで放置しておけばいいのでメリットの方が上回る。加えてai-toolkitは専用のrequirements.txtがあり、これ一発でインストール可能とお手軽(専用README.mdも用意されている)。Qwen-Image-2512とZ-Image-Turboに関して、ちょっと試してみたい系のLoRA学習は全てこの環境を使っている。ハイエンドGPUと比較すると少し(いや、かなり)遅いが、128GBのVRAMをCUDAで使えるというのが最大のメリットとなる。

話戻って、Promptの書き方か何かは不明だがまだCGっぽさが少し残っている。もう少しリアルっぽくなればいいのだが…。参考までに横座りは”sitting on the floor informally”と書けばうまく出た。が、100回以上ガチャってるので正解なのかは不明(笑)。


















