





この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第116回)は、巨大AIを凌駕する、わずか700万パラメータの小型AI「TRM」や、AIが9,300人の顧客を演じて製品の購買意欲を予測する消費者調査シミュレーションシステムを取り上げます。
また、学術論文からプレゼンテーション動画を生成するAI「PaperTalker」と、AIエージェントが“人間に頼らず”自身の行動から学習するアプローチ「Early Experience」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、夢を脳波(EEG)信号で解読し、AIを用いて画像化するためのデータセット「Dream2Image」を提案した研究を別の単体記事で取り上げています。

たった700万パラメータの小型AI「TRM」が巨大AIのGemini 2.5 Proなどを凌駕
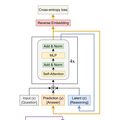
「Tiny Recursive Model」(TRM)は、わずか700万パラメータという極めて小規模なニューラルネットワークでありながら、数千億から数兆のパラメータを持つ大規模言語モデルを凌駕する性能を示しました。
TRMは、以前登場した巨大AIを蹴散らした2700万パラメータの小型AI「Hierarchical Reasoning Model」(HRM)を参考にした簡素化モデルだといいます。
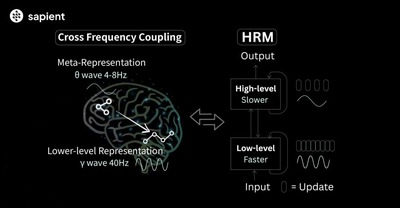
HRMでは2つのネットワークを使う方法だったのに対して、TRMでは1つの2層ネットワークを使う、よりシンプルな方法を採用しています。
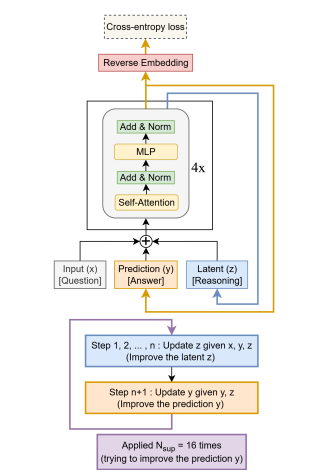
手法は、人間が難しい問題を解く時、一度答えを出してから見直し、修正を繰り返すのと同じように、TRMも最大16回まで自分の答えを改善していきます。各ステップで、前回の答えと推論過程を振り返りながら、より良い答えへと段階的に近づいていきます。
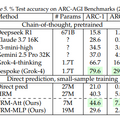
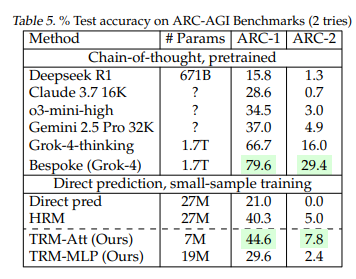
実際の成果は、難しい数独で87%、複雑な迷路問題で85%の正解率を達成。人間には簡単でもAIには難しいとされる「ARC-AGI」テストでは約45%(HRMは約40%)の精度を記録し、さらに難解な「ARC-AGI-2」でも約8%(HRMは約5%)というスコアを記録し、Gemini 2.5 Pro 32KやClaude 3.7 16K、Deepseek R1といった巨大モデルを上回りました。
AIが9300人の顧客を演じ、製品の購買意欲を予測する消費者調査シミュレーションシステム
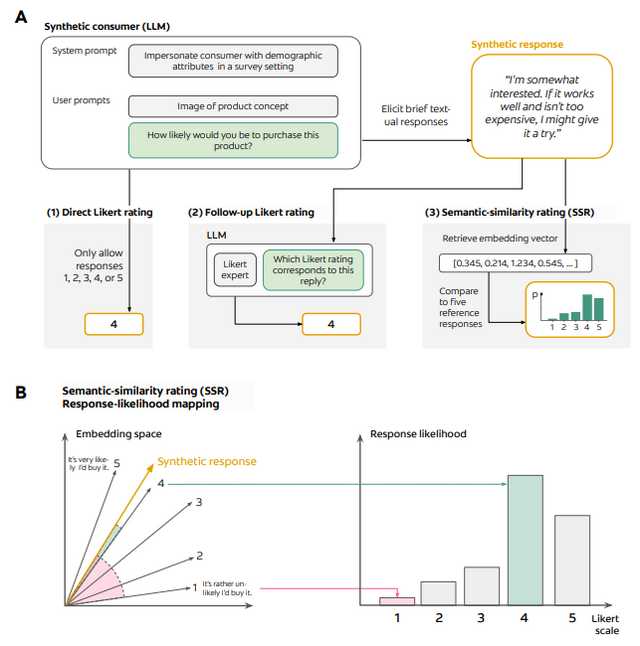
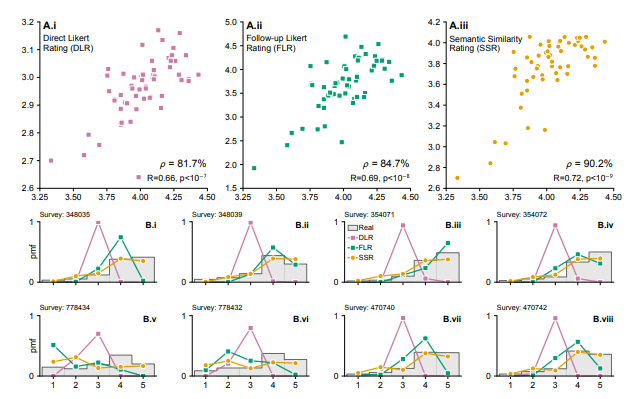
大規模言語モデル(LLM)を活用した新しい消費者調査シミュレーションシステムが開発され、従来の調査と同等の精度を達成したことが発表されました。
研究チームが開発した新手法では、LLMに数値(5段階評価など)ではなく自然な文章(自由文)で購買意向を表現させ、これらの文章を後から5段階評価に変換する仕組みを採用しています。これにより偏った回答を回避します。
パーソナルケア製品に関する57の消費者調査(計9300人の実回答)を用いた検証では、この手法は人間の再テスト信頼性の90%を達成し、実際の回答分布との類似度も0.85以上という高い精度を示しました。
またこのシステムは、若年層が高齢層より高い購買意向を示す傾向や、収入が購買意向に与える影響など、年齢や収入レベルといった人口統計学的特性による購買意向の違いも再現できます。
副次的な利点として、LLMは単なる数値評価だけでなく、製品の良い点や懸念点について詳細なフィードバックも提供します。
LLMs Reproduce Human Purchase Intent via Semantic Similarity Elicitation of Likert Ratings
Benjamin F. Maier, Ulf Aslak, Luca Fiaschi, Nina Rismal, Kemble Fletcher, Christian C. Luhmann, Robbie Dow, Kli Pappas, Thomas V. Wiecki
Paper
学術論文から著者が話すプレゼンテーション動画を生成するAI「PaperTalker」
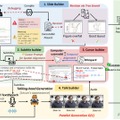
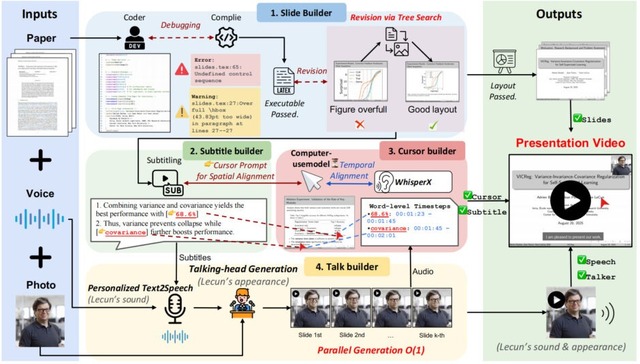
シンガポール国立大学の研究チームが、科学論文から自動的にプレゼンテーション動画を生成するAIフレームワーク「PaperTalker」を開発しました。論文と著者の顔画像、著者の音声をもとに、著者が説明するプレゼンテーション動画を生成します。
学術発表用の動画作成は、スライド設計から録音、編集まで数時間を要する作業でしたが、このシステムにより大幅な効率化が可能になります。
研究チームは、101本の論文と著者が作成した発表動画をペアにした「Paper2Video」というベンチマークデータセットを構築しました。これには機械学習、コンピュータビジョン、自然言語処理の各分野から過去3年間の査読済み論文が含まれており、1件当たり平均16枚のスライドと約6分15秒の動画で構成されています。また評価指標として、Meta Similarity、PresentArena、PresentQuiz、IP Memoryの4つが含まれます。
PaperTalkerは、LaTeXコードを使用してスライドを生成し、視覚的なレイアウトを最適化する新しい手法を導入しています。さらに、字幕とカーソルの位置を自動調整し、著者の声と顔写真から個人化された話者動画を生成します。スライドごとに並列処理を行うことで、生成速度を6倍以上高速化した点です。
評価実験では、生成された動画が論文の情報をどれだけ正確に伝えるかを測定し、人間が作成した動画と比較しても遜色ない品質を達成しました。特にPresentQuiz評価指標では、人間作成の動画よりも10%高い精度で論文の内容を伝えることができました。


Paper2Video: Automatic Video Generation from Scientific Papers
Zeyu Zhu, Kevin Qinghong Lin, Mike Zheng Shou
Project | Paper | GitHub
AIエージェントが“人間に頼らず”自身の行動から学習するアプローチ「Early Experience」をMetaが開発
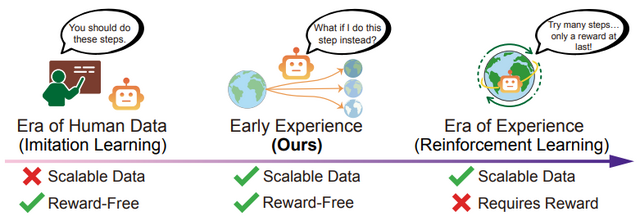
Metaとオハイオ州立大学の研究チームは、AIエージェントが自身の探索行動から学習するアプローチ「Early Experience」を発表しました。
従来のAIエージェントは、人間の手本を真似る方法で教師あり学習をしていましたが、この方法には限界がありました。質の高い手本データの収集にはコストがかかり、また新しい状況への対応が難しいという問題があったのです。
Early Experienceは、AIエージェントが自分で試行錯誤しながら学習する方法です。エージェントは様々な行動を試み、その結果として環境がどう変化するかを観察することで、報酬や評価がなくても自力で改善していきます。
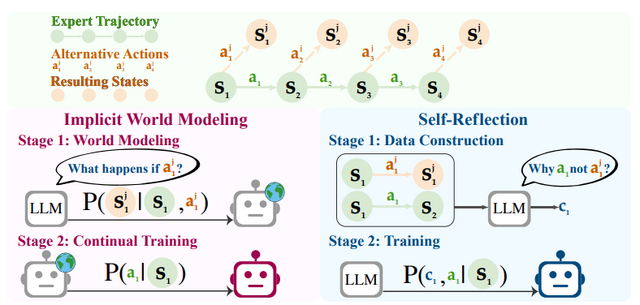
研究チームは2つの戦略を提案しています。1つ目は、色々試してエージェントが環境の仕組みを理解する「Implicit World Modeling」。2つ目は、自分の行動と専門家の行動を比較して、なぜ専門家の選択が良いのかを理解する「Self-Reflection」です。
実験では、ウェブサイトの操作やツールの使用など8つの異なるタスクで評価を行いました。その結果、Early Experienceを使った方法は、従来の方法と比べて成功率が向上しました。特に、オンラインショッピングや旅行計画のタスクで大きな改善が見られました。
Agent Learning via Early Experience
Kai Zhang, Xiangchao Chen, Bo Liu, Tianci Xue, Zeyi Liao, Zhihan Liu, Xiyao Wang, Yuting Ning, Zhaorun Chen, Xiaohan Fu, Jian Xie, Yuxuan Sun, Boyu Gou, Qi Qi, Zihang Meng, Jianwei Yang, Ning Zhang, Xian Li, Ashish Shah, Dat Huynh, Hengduo Li, Zi Yang, Sara Cao, Lawrence Jang, Shuyan Zhou, Jiacheng Zhu, Huan Sun, Jason Weston, Yu Su, Yifan Wu
Paper















![Mia(ミーア)おしゃべり猫型ロボット ブラック・充電なしモデル 全国47都道府県の方言対応 AIペット 癒やし 家族 コミュニケーションロボット 高齢者 見守り ギフト プレゼント [性格カスタマイズ/リマインド機能搭載] image](https://m.media-amazon.com/images/I/31JfsEwtA0L._SL160_.jpg)
![Mia(ミーア)おしゃべり猫型ロボット ホワイト・充電なしモデル 全国47都道府県の方言対応 AIペット 癒やし 家族 コミュニケーションロボット 高齢者 見守り ギフト プレゼント [性格カスタマイズ/リマインド機能搭載] image](https://m.media-amazon.com/images/I/31PWkfpsEPL._SL160_.jpg)