




この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第101回)は、従来のトークン化を不要にしたアプローチを採用した言語AI「AU-Net」や、テキストや画像、動画の理解と生成を1つに統合したAIモデル「Show-o2」を取り上げます。
また、コンテキストウィンドウで100万トークンを処理できるオープンウェイト推論AI「MiniMax-M1」と、1枚の写真から3Dアセットを生成するオープンソースAIモデル「Hunyuan3D 2.1」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、エッセイ執筆時にChatGPTなどのAIツールを使用することによる脳への影響を調査した研究を別に単体記事で取り上げています。

“トークン化”不要の新アプローチによる言語AI「AU-Net」をMetaなどが開発
Meta FAIRなどに所属する研究チームが、従来の言語モデルの限界を突破する新しいアーキテクチャ「AU-Net」(Autoregressive U-Net)を発表しました。
現在の言語モデルは、文を理解するために文章を「トークン」と呼ばれる単位に分割してから処理します。このアプローチには、語彙サイズの制限、未知語への対応困難、文字レベルの操作への弱さなど、様々な問題が存在していました。例えば、「strawberry」と「strawberries」が似た単語だと気づかず、それぞれをまったく別のものとして扱ってしまいます。
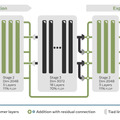
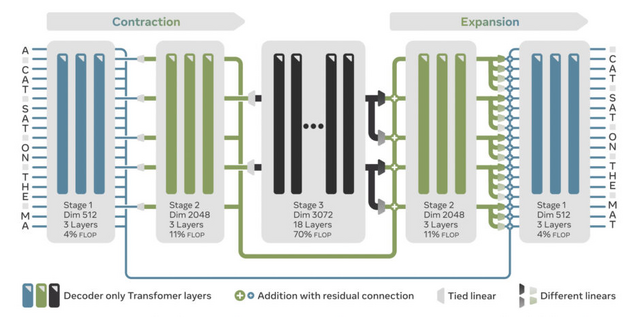
AU-Netは、生のバイトデータ(文字を一つずつ)から直接処理を開始し、それを単語、単語ペア、最大4単語のチャンクへと段階的にまとめていく方式を採用しています。U-Net技術を応用したこの階層的アーキテクチャでは、浅い層が綴りなどの細かい詳細を処理し、深い層が広範な意味パターンを捉えるという、各層が異なる役割を担う仕組みになっています。
実験では、従来手法と同じ計算コストで優れた性能を達成しました。AU-Net-3(3段階階層)やAU-Net-4(4段階階層)は、HellaSwagで73.7%、MMLUで31.7%の精度を達成し、多くのベンチマークで従来のモデルを上回りました。
文字レベルの操作テストでは、単語を逆から綴るタスクで91.7%の精度を達成し、従来手法を大きく上回りました。これは、一文字ずつ処理することの直接的な利点を示しています。
From Bytes to Ideas: Language Modeling with Autoregressive U-Nets
Mathurin Videau, Badr Youbi Idrissi, Alessandro Leite, Marc Schoenauer, Olivier Teytaud, David Lopez-Paz
Paper | GitHub
テキスト、画像、動画の理解と生成を統一的に扱うAIモデル「Show-o2」をByteDanceなどが開発
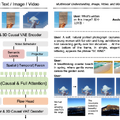
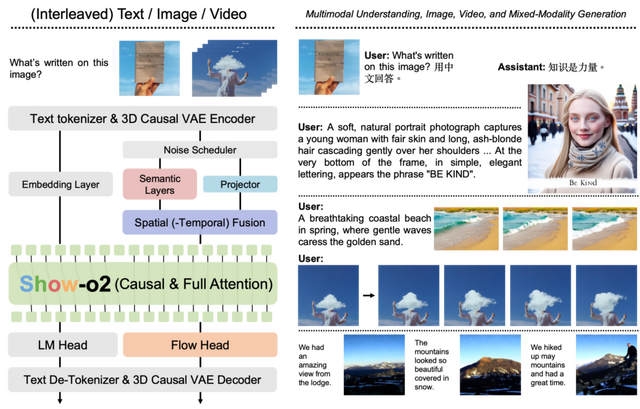
シンガポール国立大学とByteDanceの研究チームは、単一のモデルでテキスト、画像、動画の理解と生成を統一的に扱うことができるマルチモーダルモデルAIモデル「Show-o2」を発表しました。
従来のAIは、画像を理解するモデルと生成するモデルが別々でしたが、Show-o2はこれらを1つに統合しました。技術的な特徴としては「3D causal VAE」という仕組みを使い、画像と動画を同じ方法で処理できるようにしました。また、2段階の学習方法を採用することで、比較的少ないデータでも高性能を実現しています。
評価では、Show-o2は多くのベンチマークで既存手法を上回る結果を示しています。マルチモーダル理解タスクでは、MME、GQA、MMUなどの指標で最先端の性能を達成し、画像生成タスクではGenEvalやDPG-Benchで高いスコアを記録しました。1.5Bパラメータの比較的小規模なモデルでも、7Bや14Bパラメータの大規模モデルと同等以上の性能を発揮しています。



Show-o2: Improved Native Unified Multimodal Models
Jinheng Xie, Zhenheng Yang, Mike Zheng Shou
Paper | GitHub
長文(100万トークン)を処理できるオープンウェイト推論AI「MiniMax-M1」。長文理解ではClaude 4 Opus越え
「MiniMax-M1」の最大の特徴は、コンテキストウィンドウが100万トークンという長い文章を処理できることです。これはDeepSeek R1の8倍の長さで、出力として最大8万トークンの文章生成も可能です。
MiniMax-M1は、4560億のパラメータを持ち、トークンあたり459億のパラメータがアクティブになります。「Mixture-of-Experts」(MoE)と「Lightning Attention」を組み合わせた推論モデルを採用しています。
これにより、例えば生成長が10万トークンに達した場合、DeepSeek R1と比較して計算量(FLOPs)が約25%しか消費しません。
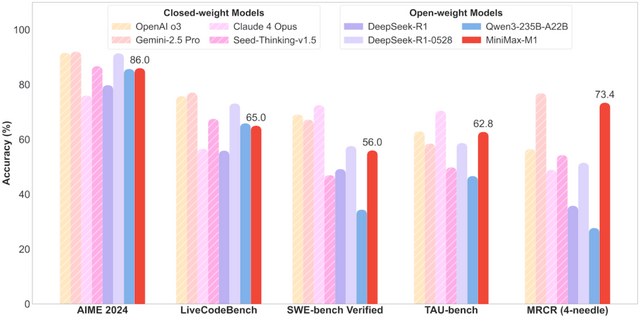
評価では、MiniMax-M1がDeepSeek-R1やQwen-235Bといったこれまでの主要なオープンウェイトモデルを凌駕しています。特にエージェントツール使用のベンチマークではGemini 2.5 Proを上回り、長文理解タスクではOpenAI o3やClaude 4 Opusの最新モデルを上回る結果を示しています。
MiniMaxは、40Kトークンと80Kトークンの最大生成長を持つ2つのバージョンをリリースしています。

MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
MiniMax: Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, Chengjun Xiao, Chengyu Du, Chi Zhang, Chu Qiao, Chunhao Zhang, Chunhui Du, Congchao Guo, Da Chen, Deming Ding, Dianjun Sun, Dong Li, Enwei Jiao, Haigang Zhou, Haimo Zhang, Han Ding, Haohai Sun, Haoyu Feng, Huaiguang Cai, Haichao Zhu, Jian Sun, Jiaqi Zhuang, Jiaren Cai, Jiayuan Song, Jin Zhu, Jingyang Li, Jinhao Tian, Jinli Liu, Junhao Xu, Junjie Yan, Junteng Liu, Junxian He, Kaiyi Feng, Ke Yang, Kecheng Xiao, Le Han, Leyang Wang, Lianfei Yu, Liheng Feng, Lin Li, Lin Zheng, Linge Du, Lingyu Yang, Lunbin Zeng, Minghui Yu, Mingliang Tao, Mingyuan Chi, Mozhi Zhang, Mujie Lin, Nan Hu, Nongyu Di, Peng Gao, Pengfei Li, Pengyu Zhao, Qibing Ren, Qidi Xu, Qile Li, Qin Wang, Rong Tian, Ruitao Leng, Shaoxiang Chen, Shaoyu Chen, Shengmin Shi, Shitong Weng, Shuchang Guan, Shuqi Yu, Sichen Li, Songquan Zhu, Tengfei Li, Tianchi Cai, Tianrun Liang, Weiyu Cheng, Weize Kong, Wenkai Li, Xiancai Chen, Xiangjun Song, Xiao Luo, Xiao Su, Xiaobo Li, Xiaodong Han, Xinzhu Hou, Xuan Lu, Xun Zou, Xuyang Shen, Yan Gong, Yan Ma, Yang Wang, Yiqi Shi, Yiran Zhong, Yonghong Duan et al. (27 additional authors not shown)
Project | Paper | GitHub
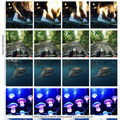
1枚の写真から3Dモデルを生成するテンセント開発のオープンソースAIモデル「Hunyuan3D 2.1」
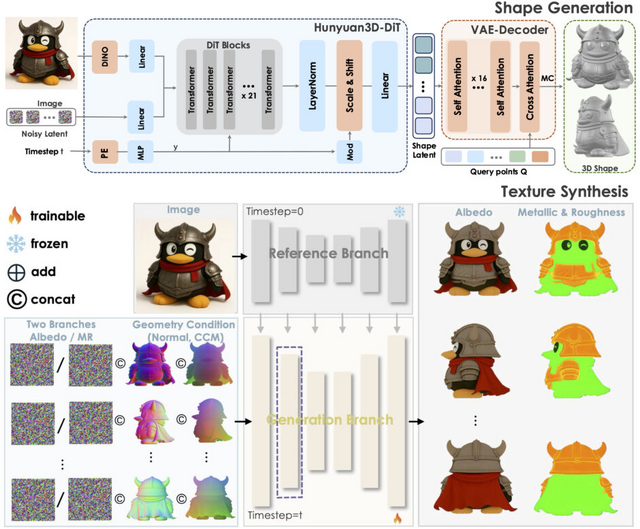
テンセントが開発した「Hunyuan3D 2.1」は、写真1枚から高品質な3Dモデルを自動生成するオープンソースAIモデルです。
このシステムの特徴は、形状の生成とテクスチャ(表面の質感)の生成を2段階に分けて行うことです。まず「Hunyuan3D-DiT」が写真から物体の形を作り、次に「Hunyuan3D-Paint」がその表面に色や質感を付けます。この方法により、より精密な3Dモデルが生成できます。
さらに「RoPE」(Rotary Position Embedding)を3Dに適応した「3D-aware RoPE」を導入することで、異なる視点から見た際のテクスチャの一貫性が大幅に向上し、従来の手法で問題となっていた継ぎ目や不自然な影の発生を抑制しています。
評価実験では、Michelangelo、TripoSG、Step1X-3Dなどの最先端モデルと比較して、Hunyuan3D 2.1が形状生成の精度、テクスチャの品質、人間の好みの観点で優れた性能を示しました。


Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Team Hunyuan3D, Shuhui Yang, Mingxin Yang, Yifei Feng, Xin Huang, Sheng Zhang, Zebin He, Di Luo, Haolin Liu, Yunfei Zhao, Qingxiang Lin, Zeqiang Lai, Xianghui Yang, Huiwen Shi, Zibo Zhao, Bowen Zhang, Hongyu Yan, Lifu Wang, Sicong Liu, Jihong Zhang, Meng Chen, Liang Dong, Yiwen Jia, Yulin Cai, Jiaao Yu, Yixuan Tang, Dongyuan Guo, Junlin Yu, Hao Zhang, Zheng Ye, Peng He, Runzhou Wu, Shida Wei, Chao Zhang, Yonghao Tan, Yifu Sun, Lin Niu, Shirui Huang, Bojian Zheng, Shu Liu, Shilin Chen, Xiang Yuan, Xiaofeng Yang, Kai Liu, Jianchen Zhu, Peng Chen, Tian Liu, Di Wang, Yuhong Liu, Linus, Jie Jiang, Jingwei Huang, Chunchao Guo
Paper | GitHub


















