

この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第99回)では、人間のようにPC画面を見て操作するMicrosoft開発のAIエージェント「GUI-Actor」や、理論上無限の長さのリップシンク映像を生成できる動画AI「SkyReels-Audとio」を取り上げます。
また大規模言語モデルの推論能力を飛躍的に向上させるNvidia開発「ProRL」や、家庭用PCで動くロボットAI「SmolVLA」、著作権問題に配慮した巨大データセット「Common Pile v0.1」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、AIを用いて死海文書の筆跡を分析した研究を別の単体記事で取り上げています。

“著作権フリー”のコードやテキストが含まれるAI向け大規模データセット「Common Pile v0.1」
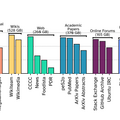
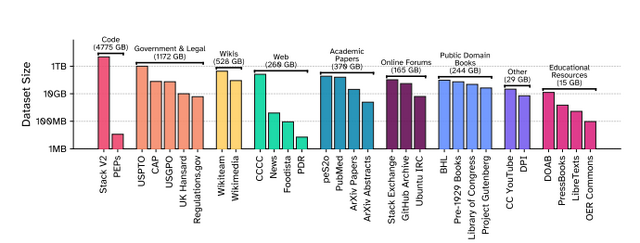
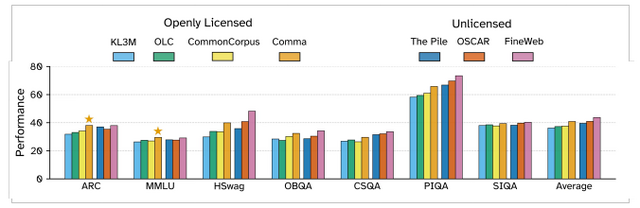
著作権問題に配慮したデータセット「Common Pile v0.1」が開発されました。これは8テラバイトという大規模なデータセットでありながら、すべてパブリックドメインやオープンライセンスのコンテンツのみで構成されています。
従来の大規模言語モデルは、インターネットから無断で収集したデータで訓練されることが多く、著作権侵害の訴訟リスクを抱えていました。Common Pileは、研究論文、オープンソースコード、政府文書、歴史的書籍など30種類の合法的なソースから収集されており、この問題を解決します。
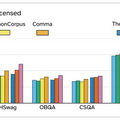
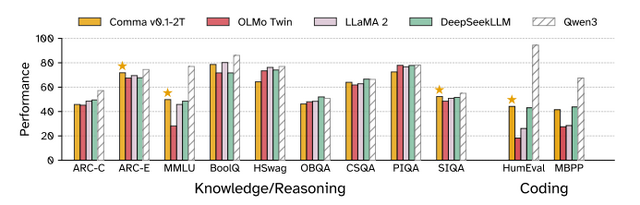
研究チームは、このデータセットで「Comma v0.1」という70億パラメータのモデルを訓練し、その有効性を実証しました。従来の非ライセンスデータで訓練されたLlama 2 7Bなどのモデルと同等の性能を達成し、特に科学的知識やコーディングタスクでは優れた結果を示しました。
The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
Nikhil Kandpal, Brian Lester, Colin Raffel, Sebastian Majstorovic, Stella Biderman, Baber Abbasi, Luca Soldaini, Enrico Shippole, A. Feder Cooper, Aviya Skowron, John Kirchenbauer, Shayne Longpre, Lintang Sutawika, Alon Albalak, Zhenlin Xu, Guilherme Penedo, Loubna Ben Allal, Elie Bakouch, John David Pressman, Honglu Fan, Dashiell Stander, Guangyu Song, Aaron Gokaslan, Tom Goldstein, Brian R. Bartoldson, Bhavya Kailkhura, Tyler Murray
Paper | GitHub
理論上無限の長さの映像を生成できる音声駆動の動画AI「SkyReels-Audio」
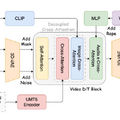
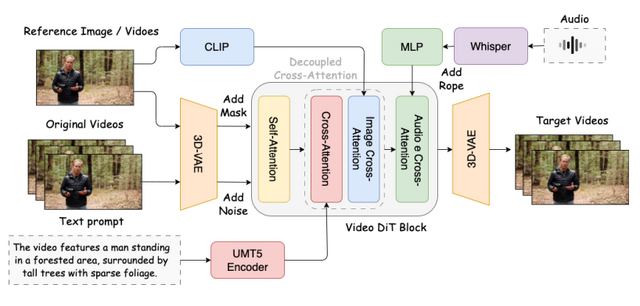
Skywork AIが、音声に合わせて自然に話す人物の動画を生成するAI技術「SkyReels-Audio」を発表しました。この技術は、音声入力だけで口の動きを正確に同期させた高品質な動画を生成できます。
この技術は、BLF(Bidirectional Latent Fusion)という新しいアルゴリズムにより、長時間の動画でも品質を維持しながらスムーズに生成できます。BLFは隣り合う短い動画の端を双方向に混ぜ合わせることで、理論的には無限の長さの動画を作ることができます。
技術的にはWhisperで音声をエンコードし、Video Diffusion Transformersを基盤として動画を生成します。訓練には厳選された1000時間の高品質データを使用し、8つのA800 GPUで80フレームの動画を約1分で生成できるまで高速化されています。
実験では既存手法を上回る性能を示し、特に口の同期精度と視覚的品質で優れた結果を記録しました。実写の人物動画で訓練されているにもかかわらず、アニメや彫刻などのスタイル化されたポートレートにも適用できる汎用性も確認されています。



SkyReels-Audio: Omni Audio-Conditioned Talking Portraits in Video Diffusion Transformers
Zhengcong Fei, Hao Jiang, Di Qiu, Baoxuan Gu, Youqiang Zhang, Jiahua Wang, Jialin Bai, Debang Li, Mingyuan Fan, Guibin Chen, Yahui Zhou
Project | Paper | GitHub
人間のようにPC画面を見て操作するAIエージェント「GUI-Actor」をMicrosoftが開発
PC画面上のボタンやアイコンを自動的にクリックするGUI用AIエージェントの開発において、画面上の正しい位置を特定することは重要な課題の一つです。従来の手法では、AIが「x=0.125、 y=0.23」のような座標を文字として生成していましたが、この方法には問題がありました。
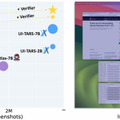
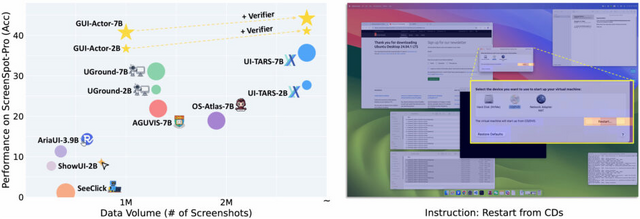
Microsoftなどの研究チームが開発した「GUI-Actor」は、正確な座標を計算してからクリックするのではなく、人間のように目的の要素を見て直接クリックするよう設計されています。
GUI-Actorは特殊なトークンを導入し、このトークンが画面上の関連領域に注意を向ける仕組みを採用しています。画面を小さなパッチに分割し、どのパッチが目的の要素に対応するかを判定します。さらに、提案された複数の候補位置から最適なものを選ぶ検証器も搭載しています。
実験結果、GUI-Actor-7Bは720億パラメータを持つ大規模モデル「UI-TARS-72B」を上回る性能を示した。また、訓練データの60%だけで最高性能に到達し、従来手法より効率的な学習が可能であることも実証されました。
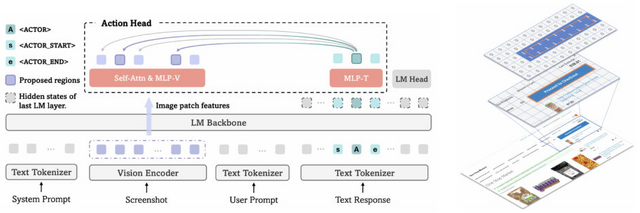
GUI-Actor: Coordinate-Free Visual Grounding for GUI Agents
Qianhui Wu, Kanzhi Cheng, Rui Yang, Chaoyun Zhang, Jianwei Yang, Huiqiang Jiang, Jian Mu, Baolin Peng, Bo Qiao, Reuben Tan, Si Qin, Lars Liden, Qingwei Lin, Huan Zhang, Tong Zhang, Jianbing Zhang, Dongmei Zhang, Jianfeng Gao
Paper
家庭用PCで動くロボットAI「SmolVLA」をHugging Faceなどが開発
Hugging Faceなどの研究チームが、小型で効率的なロボット制御AIモデル「SmolVLA」を開発しました。このモデルは、従来の大規模なビジョン言語行動モデル(VLA)の約10分の1となる4億5000万パラメータという小規模サイズながら、同等以上の性能を実現しています。
SmolVLAの特徴は、一般的な消費者向けGPUやCPUでも動作可能な点です。また、世界中のコミュニティメンバーが低コストロボット「SO-100」で収集した約2万3000の軌道データのみで学習されており、従来モデルの100万以上のデータと比べて大幅に少ないデータで済みます。
性能評価では、シミュレーション環境で70億パラメータのOpenVLAや33億パラメータのπ0といった大規模モデルと同等以上の成功率を達成しました。実世界のロボットタスクでも78.3%の平均成功率を記録し、より大規模なモデルを上回っています。
SmolVLAは、Hugging Facegaがロボティクス分野で展開するオープンソースプロジェクト「LeRobot」の制御システムです。LeRobotは2万円弱で作ったロボットアームを家庭用ノートPCによって数分で学習させることができる、一般ユーザーでも手が出せる内容になっています。
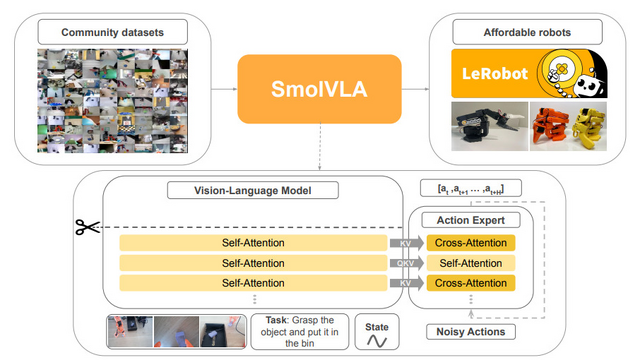


SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, Simon Alibert, Matthieu Cord, Thomas Wolf, Remi Cadene
Paper | GitHub
AI推論能力を最大54%向上させる、長期強化学習法「ProRL」をNVIDIAを開発
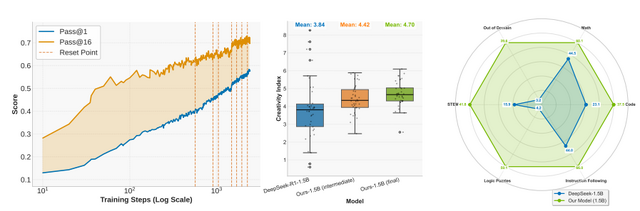
NVIDIAの研究チームが、大規模言語モデルの推論能力を飛躍的に向上させる手法「ProRL」(Prolonged Reinforcement Learning)を開発しました。この手法により、わずか15億パラメータのモデルで世界最高性能を達成し、70億パラメータのモデルと同等以上の性能を実現しています。
ProRLの最大の特徴は、従来の数百ステップではなく2000ステップ以上の長期間にわたる強化学習を可能にした点です。これにより、ベースモデルでは全く解けなかった問題を高い正答率で解けるようになるなど、推論能力の向上が見られました。
具体的な性能向上は、数学で14.7%、コーディングで13.9%、論理パズルで54.8%と大幅な改善を示しています。特に注目すべきは、訓練データに含まれていない未知のタスクでも高い性能を発揮し、モデルが抽象的な推論パターンを学習していることが確認された点です。
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
Mingjie Liu, Shizhe Diao, Ximing Lu, Jian Hu, Xin Dong, Yejin Choi, Jan Kautz, Yi Dong
Paper | Hugging Face