




この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第97回)では、Tiktokの開発元として有名な中国企業「ByteDance」が発表した4つのAI技術を取り上げます。
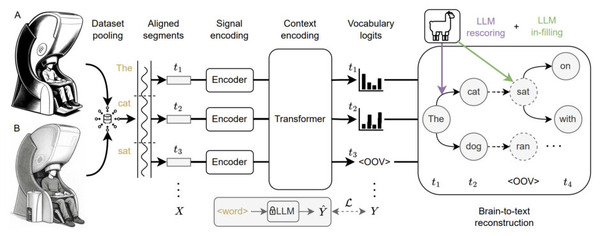
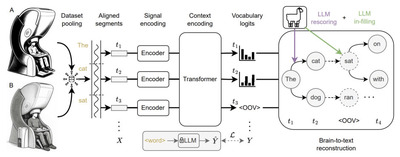
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、脳に電極を“埋め込まない”で脳活動から考えた文章を文字に起こす非侵襲AI技術(B2T)を単体記事で掘り下げています。
テキストと画像の両方が得意な生成AI「MMaDA」をByteDanceが発表
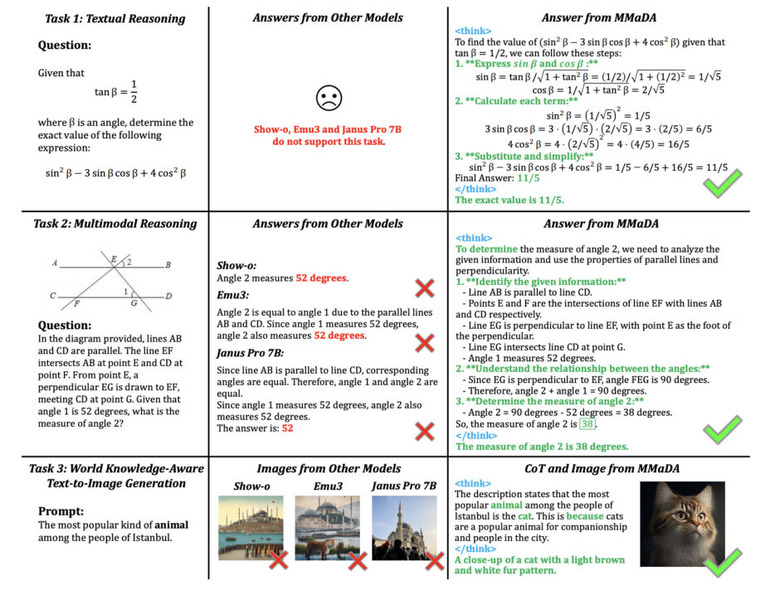
ByteDanceの研究チームが、テキストと画像の両方を統一的に扱える新しいAIモデル「MMaDA」を発表しました。MMaDAは、テキスト推論、マルチモーダル理解、テキストから画像生成という多様な領域で優れた性能を実現します。
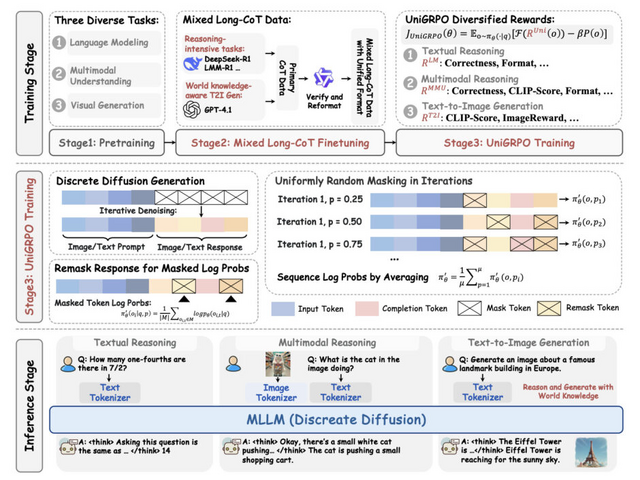
MMaDAの主な特徴は3つあります。まず、異なる種類のデータを同じ方法で処理する統一アーキテクチャを採用しています。次に、段階的な思考過程を学習する「Mixed Long-CoT」という手法で、複雑な問題を論理的に解決できるようになります。さらに、「UniGRPO」という独自の強化学習アルゴリズムを採用して継続的に改善する仕組みも備えています。
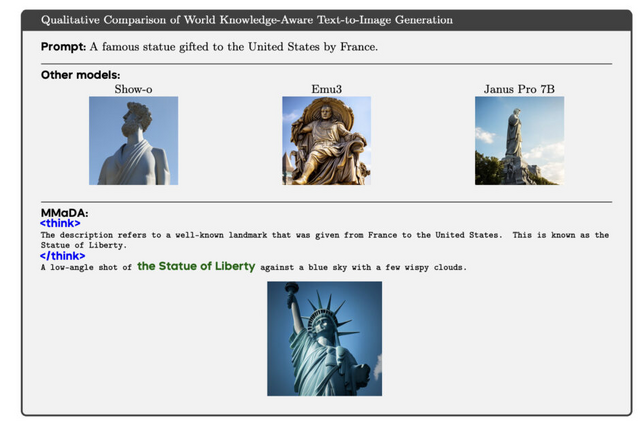
実験では、MMaDAが既存の強力なAIモデルを上回る性能を示しました。数学の問題解決ではLLaMA-3より優秀で、画像理解ではShow-oやSEED-Xを凌駕し、画像生成ではSDXLやJanusを超える結果を出しています。

MMaDA: Multimodal Large Diffusion Language Models
Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, Mengdi Wang
Paper | GitHub
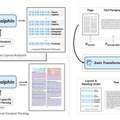
PDFや画像内の文章を抽出できるAIモデル「Dolphin」をByteDanceが発表
ByteDanceの研究チームが、文書画像解析のための新しいマルチモーダルモデル「Dolphin」を発表しました。このモデルは、PDFや画像形式の文書から構造化されたコンテンツを抽出する手法を提案しています。
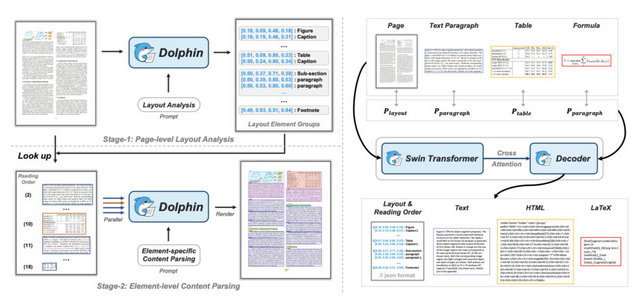
Dolphinの特徴は「分析してから解析する」という2段階アプローチです。第1段階でページ全体のレイアウトを分析し、文書内の各要素(段落、表、数式、図など)を識別して読み取り順序を決定します。第2段階では、これらの要素を並列処理することで、効率的かつ高精度な内容解析を実現しています。
性能評価では、わずか3億2200万パラメータという軽量モデルでありながら、GPT-4oやClaude-3.5-Sonnetなどの大規模モデルを上回る結果を示しました。特に複雑なレイアウトや、表・数式・図が混在する文書で顕著な改善が見られます。処理速度も従来手法より向上しています。
学習には3000万件以上のサンプルを含む大規模データセットを使用しました。HTML、LaTeX、Markdownなど様々な形式から生成された合成データや、科学論文から抽出された表・数式データが含まれています。


Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting
Hao Feng, Shu Wei, Xiang Fei, Wei Shi, Yingdong Han, Lei Liao, Jinghui Lu, Binghong Wu, Qi Liu, Chunhui Lin, Jingqun Tang, Hao Liu, Can Huang
Paper | GitHub
画像理解と生成を統合したAIモデル「BAGEL」をByteDanceが発表
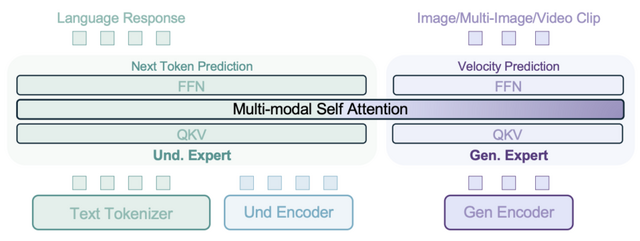
ByteDanceの研究チームは、14Bパラメータ(7Bアクティブパラメータ)を持つ画像や動画の理解と生成を単一のモデルで実現する「BAGEL」(Scalable Generative Cognitive Model)を発表しました。従来は別々に開発されていた視覚理解と生成の機能を統合し、両者が相互に強化し合うAIモデルです。
技術的な特徴として、「Mixture-of-Transformers」(MoT)という新しいアーキテクチャを採用しています。これは理解用と生成用の2つの専門家モジュールが共有の自己注意機構を通じて相互作用する仕組みで、それぞれのタスクに特化しながら知識を効果的に共有できます。
BAGELは数兆トークンという膨大なデータで訓練され、特にテキストと画像が交互に現れるインターリーブデータを活用しています。動画データから時間的変化を、ウェブデータから実世界の複雑な文脈を学習することで、従来のモデルでは困難だった高度なマルチモーダル推論を実現しています。
性能面では、画像理解と生成の両方で既存のオープンソースモデルを大きく上回る結果を示しています。さらに、複雑な推論を必要とするタスクでも優れた能力を発揮し、3D空間の理解や視点移動、未来のフレーム予測などの能力も備えています。





Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, Haoqi Fan
Project | Paper | GitHub | Hugging Face
大規模言語モデルの学習時間を大幅短縮できる手法「PMA」をByteDanceが公開
ByteDanceの研究チームが、大規模言語モデルの事前学習を効率化する画期的な手法を発表しました。「Pre-trained Model Average」(PMA)と呼ばれるこの技術は、訓練中の複数のチェックポイントを統合することで、計算コストを削減しながら性能を向上させます。
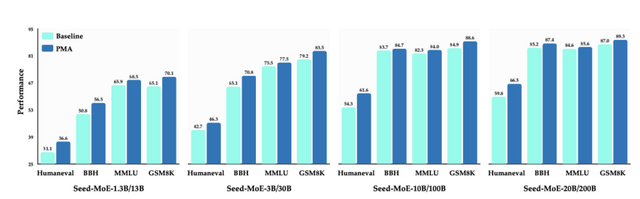
従来、モデルマージングは主に事後学習で使用されていましたが、研究チームは事前学習段階での応用に着目しました。411Mから70Bのパラメータを持つ規模のモデルとMoE(Mixture-of-Experts)を用いた実験を行いました。
その結果、プログラミング能力を測定するHumanEvalベンチマークでは、特定のモデルで顕著な性能向上が確認されました。数学的推論能力を評価するGSM8Kベンチマークにおいても、同様の改善が観察されています。
興味深いのは、一定の学習率で訓練したモデルにPMAを適用すると、訓練の後半で学習率を徐々に下げていく従来の方法と同等の性能を達成できることです。これにより、学習率の調整なしに高性能なモデルを得ることが可能になり、開発サイクルの短縮と計算資源の大幅な節約が実現します。
Model Merging in Pre-training of Large Language Models
Yunshui Li, Yiyuan Ma, Shen Yan, Chaoyi Zhang, Jing Liu, Jianqiao Lu, Ziwen Xu, Mengzhao Chen, Minrui Wang, Shiyi Zhan, Jin Ma, Xunhao Lai, Deyi Liu, Yao Luo, Xingyan Bin, Hongbin Ren, Mingji Han, Wenhao Hao, Bairen Yi, LingJun Liu, Bole Ma, Xiaoying Jia, Xun Zhou, Siyuan Qiao, Liang Xiang, Yonghui Wu
Paper