



この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第95回)では、“検索しない”AI検索エンジン「ZeroSearch」や、AI自身が学習効率の良いタスクを生成し自分で解くことで学習する外部データ不要のAIシステム「Absolute Zero」を取り上げます。
また日本語楽曲も高速生成できる音楽AIモデル「ACE-Step」や、空気を読んで自律的に人間に話しかける会話AI「Voila」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、チャットボットAIの精度が日進月歩で向上している一方で悪化している「幻覚」(ハルシネーション)の現状について単体記事で取り上げています。
“検索しない”AI検索エンジン「ZeroSearch」
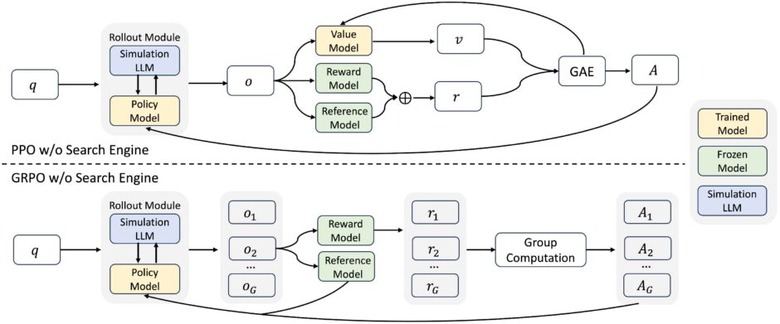
大規模言語モデル(LLM)の推論と生成能力を向上させるためには、効果的な情報検索機能が不可欠です。最近の研究では強化学習(RL)を用いて実際の検索エンジンと対話することでLLMの検索能力を向上させる試みがなされていますが、この手法には2つの大きな課題があります。
1つは検索エンジンが返す文書の品質が予測不可能であり、学習プロセスにノイズや不安定性をもたらすこと、もう1つはRLトレーニングには膨大な検索リクエストが必要となり、APIコストが高額になることです。
この課題に対応するため、研究チームは「ZeroSearch」というフレームワークを開発しました。これは実際の検索エンジン(GoogleなどのAPI)を使う代わりに、LLM自身に検索エンジンの役割を果たさせて検索能力を強化する手法です。
手法では軽量な教師あり微調整(SFT)でLLMを検索モジュールに変換し、クエリに応じて関連性のある文書とノイズの多い文書の両方を生成できるようにします。RL学習中には、生成される文書の品質を徐々に低下させることで、モデルの推論能力を段階的に引き出します。情報の質が下がっても適切に推論できる能力を身につけさせるのです。
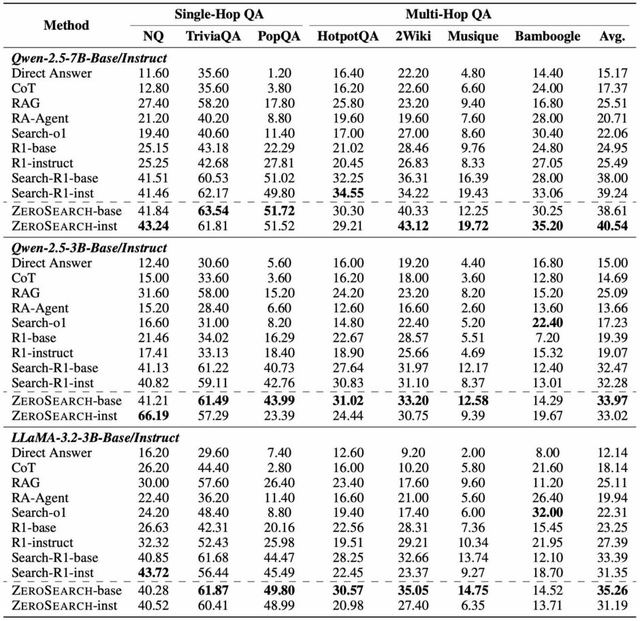
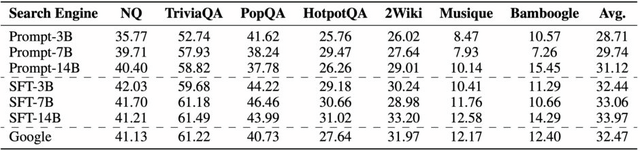
実験の結果、ZeroSearchは3BのLLMを検索モジュールとして効果的に機能することが証明されました。特筆すべきは、7Bの検索モジュールは実際のGoogle検索エンジンと同等のパフォーマンスを達成し、14Bの検索モジュールに至っては実際の検索エンジンを上回る性能を示しました。

ZeroSearch: Incentivize the Search Capability of LLMs without Searching
Hao Sun, Zile Qiao, Jiayan Guo, Xuanbo Fan, Yingyan Hou, Yong Jiang, Pengjun Xie, Fei Huang, Yan Zhang
Project | Paper | GitHub
“自分で良問を作り自分で解く”ことで学習する、外部データ不要のAIシステム「Absolute Zero」
従来の手法ではモデルの訓練に人間が作成した質問や回答のデータセットが必要でした。しかし、高品質な人間作成データの不足は、長期的なスケーラビリティに懸念を生じさせていました。研究チームはこの問題に対処するため、「Absolute Zero」を考案します。
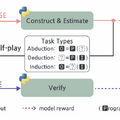
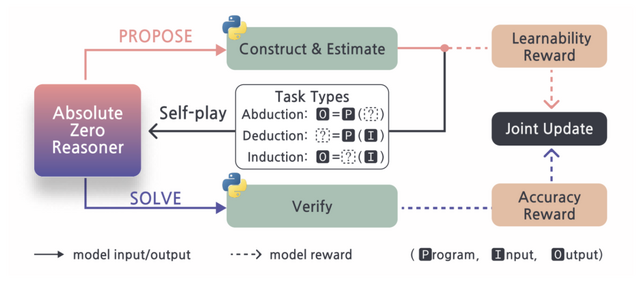
この手法では「AIが自分で学習効果が高い問題を作り、自分で解く」というセルフプレイ方式を採用しています。モデルが自身の学習進度を最大化するタスクを提案し、それを解決することで推論能力を向上させます。この過程で外部データに一切依存せず、完全に自己進化するシステムを実現しています。
実現するために「Absolute Zero Reasoner」(AZR)というシステムに基づいており、コード実行環境を活用して3種類の推論能力を鍛えます。「入力とプログラムから結果を予測する能力」「結果とプログラムから入力を推測する能力」「入出力例からプログラムを作成する能力」です。これらをバランスよく訓練することで、多様な推論スキルを獲得しています。
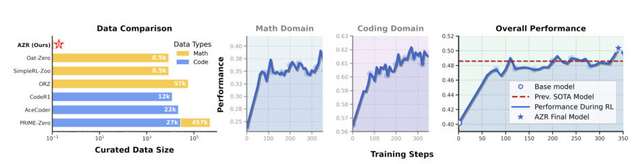
評価実験では人間が作成したデータを一切使わなかったにもかかわらず、このシステムは数学的推論とコーディングの両方で優れた成績を示しました。

Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Yang Yue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, Gao Huang
Project | Paper | GitHub
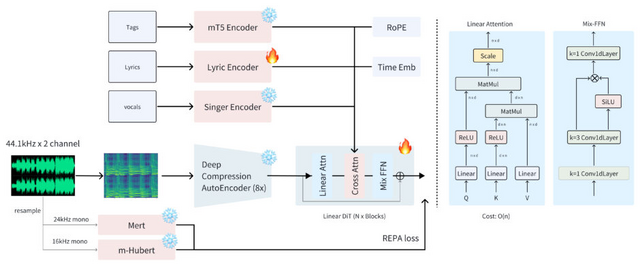
日本語楽曲も高速作成できるオープンソース音楽生成AI「ACE-Step」
従来の音楽生成AIには大きく分けて2種類ありました。大規模言語モデル(LLM)ベースのモデル(Yue、SongGenなど)は歌詞と音楽の調和に優れていますが処理が遅く、一方で拡散モデル(DiffRhythmなど)は速いけれど音楽的なまとまりに欠ける傾向がありました。
この両方の良いところを組み合わせた「ACE-Step」という、新しいオープンソース音楽生成AIモデルを開発しました。処理速度はA100 GPUで4分の楽曲を20秒で生成できるといいます。これは従来のLLMモデルより15倍高速です。それでいて音楽の一貫性や歌詞との調和も高品質を維持するといいます。
幅広い音楽スタイルに対応しており、ポップ、ロック、ジャズからダブステップ、メタル、サルサまで様々なジャンルを生成できます。また、英語、中国語、日本語、ロシア語など19の言語をサポートしています。
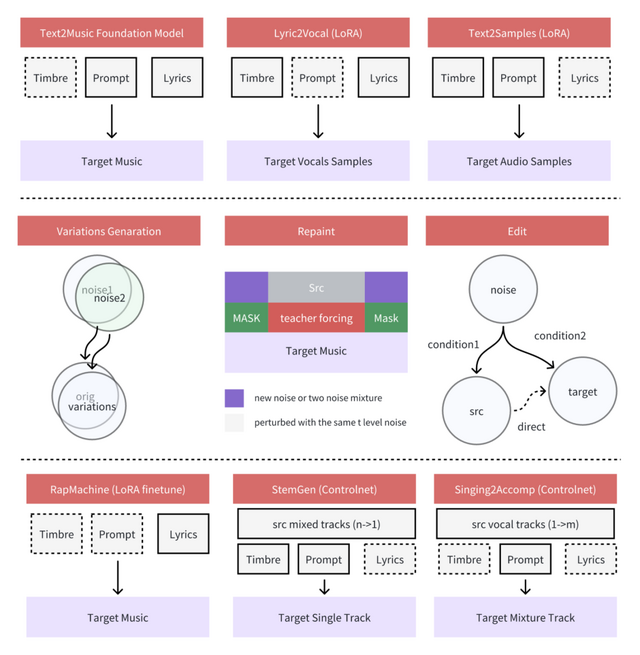
モデルには3つの機能があります。「バリエーション生成」は同じ曲の別バージョンを作り出せます。「リペインティング」は曲の特定部分だけを変更できます。「歌詞編集」はメロディや声質、伴奏はそのままで歌詞だけを変える機能です。

ACE-Step: A Step Towards Music Generation Foundation Model
Junmin Gong, Sean Zhao, Sen Wang, Shengyuan Xu, Joe Guo
Project | GitHub
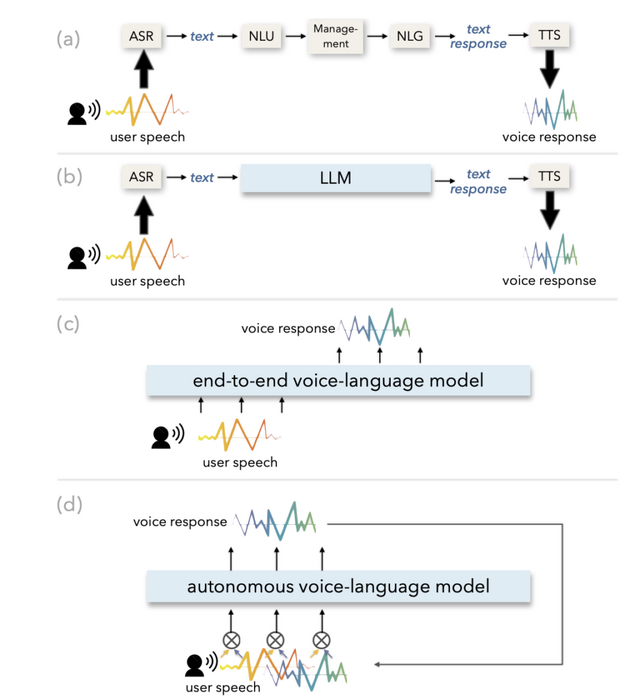
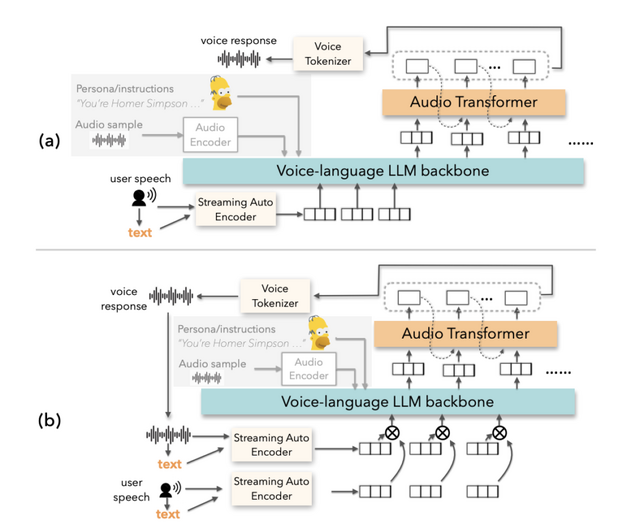
空気を読んで自律的に人間に話しかける会話AI「Voila」
現在のAIシステムの多くは受動的です。例えばSiriやChatGPTなどは、ユーザーからの問いかけに対して応答するという反応型の仕組みを採用しています。これに対して今回開発された「Voila」は、常に周囲の状況を評価し、リアルタイムでユーザーのニーズを予測して、いつ、どのように対話するかを判断します。
Voilaは低遅延の会話を可能にしながら、トーン、リズム、感情などの豊かな音声ニュアンスを保持します。応答遅延はわずか195ミリ秒で、平均的な人間の応答時間よりも優れています。
人間らしい対話になるよう設計されており、ユーザーの注意を引いて対話を開始するために話しかけたり、会話の流れを変えるために割り込んだり、「うーん」や「はい」などの簡単な相槌を使って相手が話している時に注意を払っていることを伝えたりします。
ユーザーはテキスト指示を書くだけで、話者のアイデンティティやトーンなどの特性を定義できます。さらに、Voilaは100万以上の事前構築された音声をサポートし、10秒という短い音声サンプルからでも新しい音声を効率的にカスタマイズすることができます。
Voilaは英語、中国語、フランス語、ドイツ語、日本語、韓国語の6言語に対応しており、音声認識や音声合成だけでなく、音声翻訳なども一つのモデルで処理できます。
Voilaモデルの評価では、ASRタスクで単語誤り率(WER)4.8%を達成し、TTSタスクでも3.2%のWERを記録するなど、競争力のある性能を示しています。

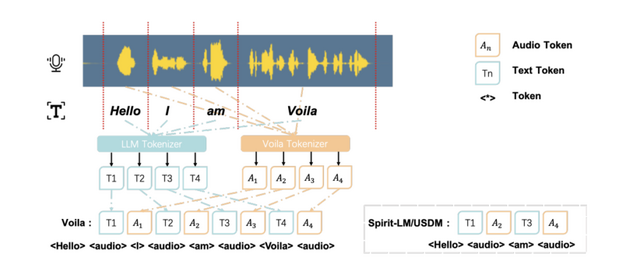
Voila: Voice-Language Foundation Models for Real-Time Autonomous Interaction and Voice Role-Play
Yemin Shi, Yu Shu, Siwei Dong, Guangyi Liu, Jaward Sesay, Jingwen Li, Zhiting Hu
Project | Paper | GitHub







![イヤホン 有線 [HIFI音質]イヤホン 有線 3.5mmジャック ノイズ低減 通話/音楽 音量調節対応 防水 通勤・会議・運動 | 原音再現 MFi認証 重低音 遅延なし コンパクト 軽量 インイヤー 人体工学 image](https://m.media-amazon.com/images/I/31CBe3mkz-L._SL160_.jpg)






