



この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第94回)では、1ビットLLMの進化版「BitNet v2」と、AIに何度も自己議論させることで精度が向上していく手法「CoRT 」を取り上げます。
またAIが生成した動画内における動きの一貫性を評価する手法「TRAJAN」と、マイクロソフトが新しく開発した小型言語モデル「Phi-4-reasoning」を紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、現在AIモデル評価の業界標準とされているランキング形式(リーダーボード)のAIベンチマーク「Chatbot Arena」における問題を明らかにした研究を単体記事で掘り下げています。
AIが生成した動画の“動きの一貫具合”を評価する手法「TRAJAN」をGoogleが開発
Googleの研究チームは、AIが生成した映像の動きの品質を評価する手法「TRAJAN」(TRAJectory AutoeNcoder)を開発しました。現在の動画生成AIモデルは見た目の良いフレームを生成できても、一貫した自然な動きの表現が課題となっています。
従来のFVD(Fréchet Video Distance)などの評価指標はフレーム内容に敏感である一方、動きの品質を適切に評価できませんでした。
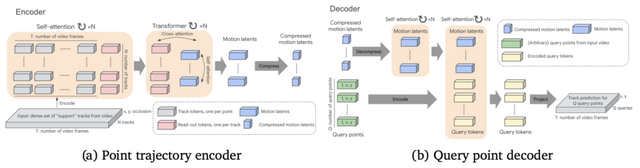
TRAJANは映像内の点の軌跡(ポイントトラック)を活用して動きの特徴を直接モデル化します。BootsTAPIRモデルでビデオから点の軌跡を抽出し、自動エンコードして高レベルの動きの特徴を取得する仕組みです。このTRAJANの潜在空間を使用して、ビデオの分布(1つの生成と1つの実写、または2つのデータセットなど)を比較したり、TRAJANからの再構成エラーを使用してビデオごとの動きの不一致を推定したりすることができます。
特に、UCF-101データセットでの時間的歪みの検出感度が高く、WALTモデルで生成されたビデオと実写ビデオの動きの類似性を適切に捉え、EvalCrafterやVideoPhyデータセットでは人間による評価との高い相関を示しました。


Direct Motion Models for Assessing Generated Videos
Kelsey Allen, Carl Doersch, Guangyao Zhou, Mohammed Suhail, Danny Driess, Ignacio Rocco, Yulia Rubanova, Thomas Kipf, Mehdi S. M. Sajjadi, Kevin Murphy, Joao Carreira, Sjoerd van Steenkiste
Project | Paper | GitHub
o1超えの精度を示す小型AIモデル「Phi-4-reasoning」をマイクロソフトが開発
Microsoftが140億パラメータモデルの小規模言語モデル「Phi-4-reasoning」を開発しました。Phi-4-reasoningは、同社のPhi-4をベースに推論能力を強化したモデルです。このモデルは、問題を段階的に分解し、内部で反省し、複数の問題解決戦略を検討する能力を持っています。
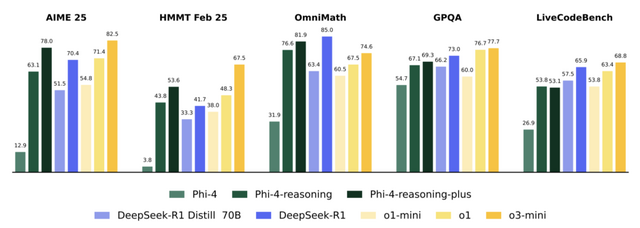
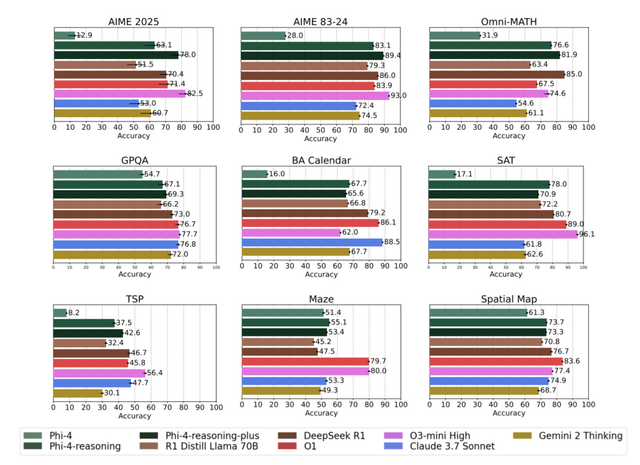
特に注目すべき点は、パラメータ数が比較的少ないにもかかわらず、はるかに大きなモデル(DeepSeek-R1-Distill-Llama-70Bなど)よりも優れた性能を示していることです。
開発チームは、問題を選定し、o3-miniモデルから生成された思考過程を含む回答を使用して教師あり微調整(SFT)を行いました。さらに、Phi-4-reasoning-plusというバリエーションでは、強化学習(RL)を追加的に適用し、特に数学分野でのパフォーマンスを向上させています。
評価では、数学的推論、科学、コーディング、アルゴリズム問題解決などの多様なベンチマークで高いスコアを記録しました。特に数学ベンチマーク(AIME 2025)ではベースモデルから50%以上の精度向上を達成し、DeepSeek-R1やo1を上回る結果を出しています。
Phi-4-reasoning Technical Report
Marah Abdin, Sahaj Agarwal, Ahmed Awadallah, Vidhisha Balachandran, Harkirat Behl, Lingjiao Chen, Gustavo de Rosa, Suriya Gunasekar, Mojan Javaheripi, Neel Joshi, Piero Kauffmann, Yash Lara, Caio César Teodoro Mendes, Arindam Mitra, Besmira Nushi, Dimitris Papailiopoulos, Olli Saarikivi, Shital Shah, Vaishnavi Shrivastava, Vibhav Vineet, Yue Wu, Safoora Yousefi, Guoqing Zheng
Paper
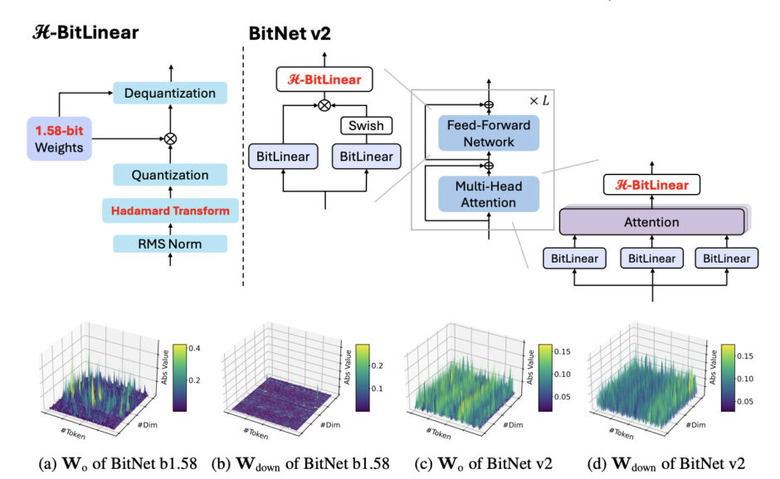
1ビットLLMの進化版「BitNet v2」をマイクロソフトが発表
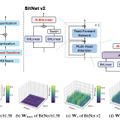
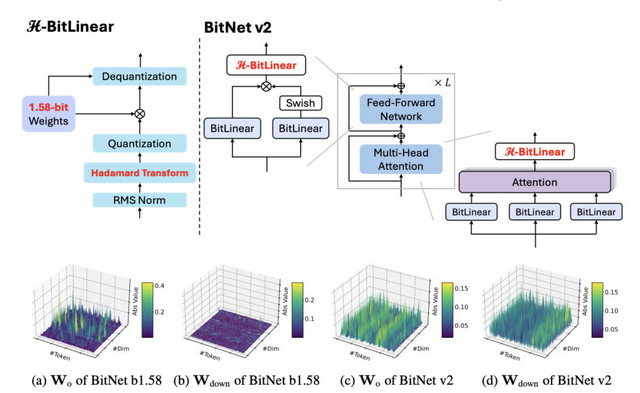
BitNet v2は、大規模言語モデル(LLM)を効率的に動作させるための技術です。この技術の最大の特徴は、モデルの重みを1ビット相当に抑えながら、アクティベーションも4ビットまで削減できることにあります。
従来のBitNet b1.58では、重みは1.58ビットに削減できていましたが、アクティベーションは8ビットでした。BitNet v2では「H-BitLinear」という新しいモジュールを導入し、アダマール変換という数学的手法を用いてアクティベーションの分布を改善しています。
これが重要な理由は、LLMのアクティベーションには多くの「外れ値」が存在し、これが低ビット化を難しくしていたからです。アダマール変換を適用することで、この分布をより均一に近づけ、4ビットでも十分な精度を保てるようになりました。
実験では、BitNet v2はBitNet b1.58性能をほとんど落とさずに計算効率を向上させることに成功しています。これにより、最新のGPUの4ビット計算能力を最大限に活用でき、LLMの実行に必要なコストとエネルギーを削減できます。
BitNet v2: Native 4-bit Activations with Hadamard Transformation for 1-bit LLMs
Hongyu Wang, Shuming Ma, Furu Wei
Paper
AIに繰り返し自己議論させる→考えが深くなりより洗練された回答が出力される手法「CoRT 」
「CoRT」(Chain of Recursive Thoughts)は大規模言語モデル(LLM)に自身の回答を批評させたり、異なる視点から問題にアプローチさせることで、より洗練された回答を導き出そうとするものです。
CoRTの仕組みは次の通りです。まずAIが初期の回答を生成します。次に、AIは必要な「思考ラウンド」の数を決定します。各ラウンドでは、3つの代替回答を生成し、すべての回答を評価した上で最良のものを選びます。最終的な回答は、この「AI内バトルロイヤル」を勝ち抜いたものとなります。
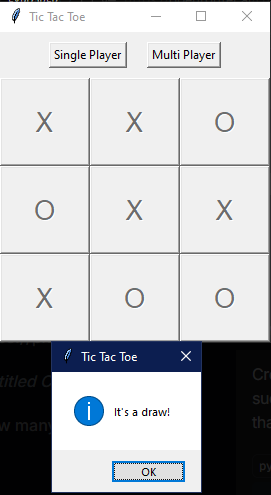
実験では、Mistral 3.1 24Bを用いてプログラミングタスクにおける三目並べを精度評価に使用しました。結果は、CoRTを使用したバージョンの方がCoRTを使用しなかったバージョンよりも精度が向上したといいます。
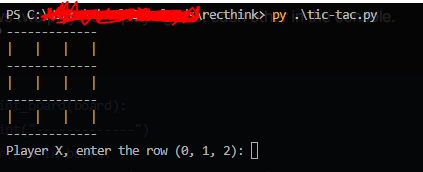
CoRT (Chain of Recursive Thoughts)
GitHub








![イヤホン 有線 [HIFI音質]イヤホン 有線 3.5mmジャック ノイズ低減 通話/音楽 音量調節対応 防水 通勤・会議・運動 | 原音再現 MFi認証 重低音 遅延なし コンパクト 軽量 インイヤー 人体工学 image](https://m.media-amazon.com/images/I/31CBe3mkz-L._SL160_.jpg)






