


1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第45回目は、生成AI最新論文の概要5つを紹介します。
生成AI論文ピックアップ
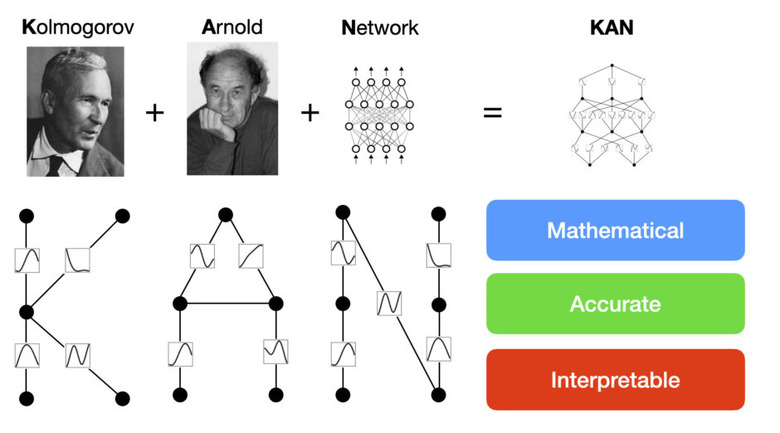
高精度なニューラルネットワーク・アーキテクチャ「KAN」をMITなどの研究者らが開発
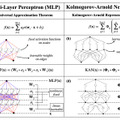
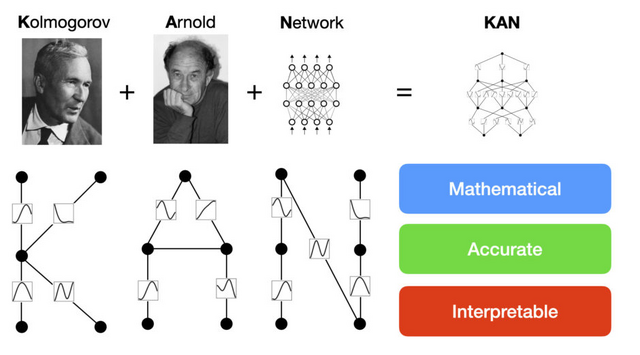
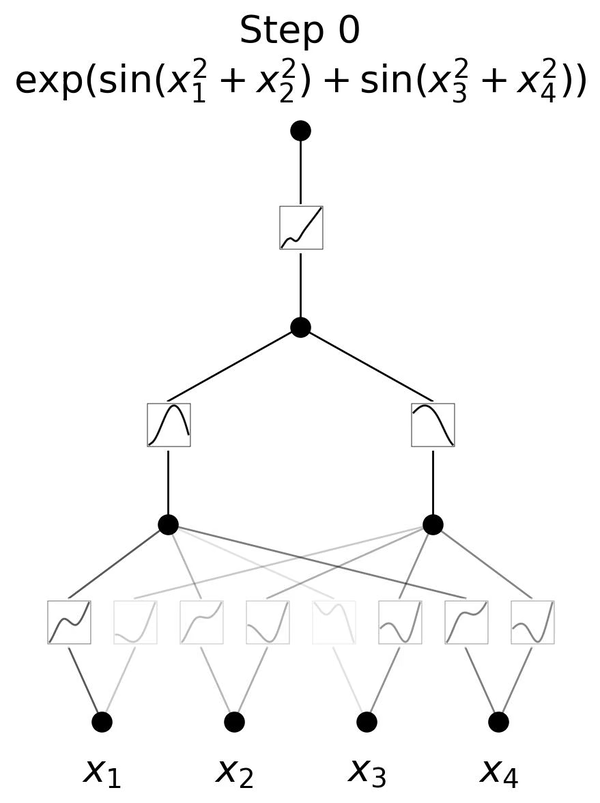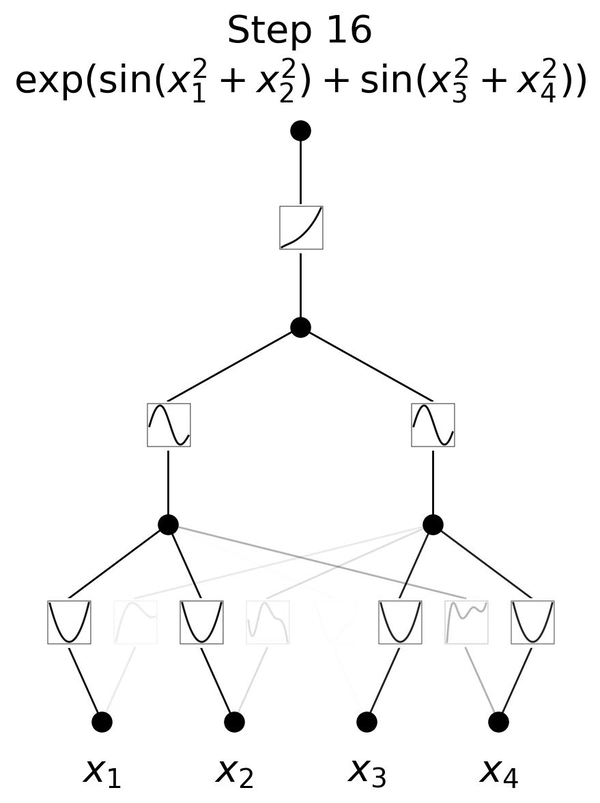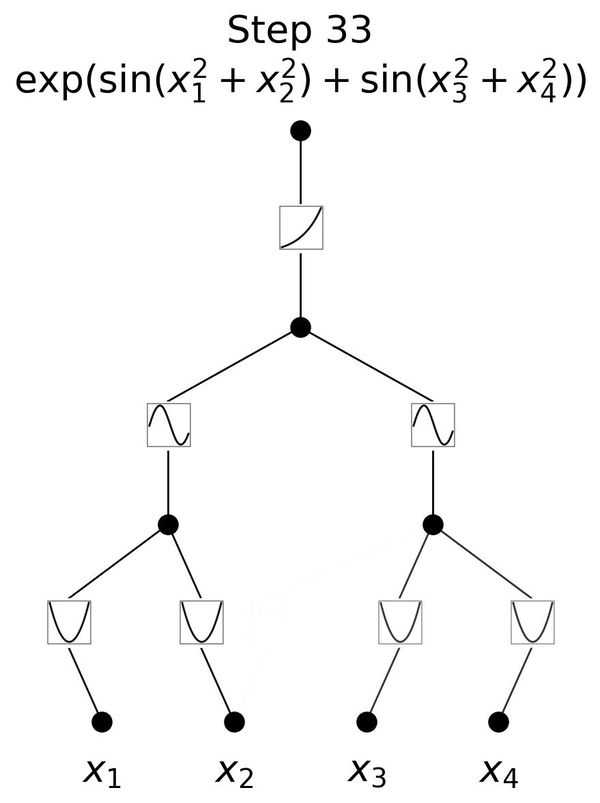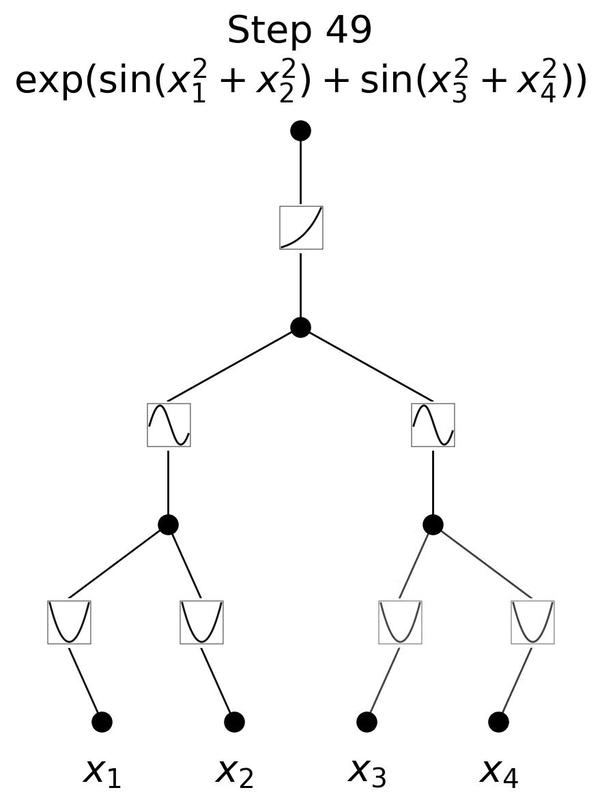
「KAN」(Kolmogorov-Arnold Network)は、ニューラルネットワーク(NN)の新しい形であり、これまでの代表的なNNアーキテクチャである「MLP」(Multi-Layer Perceptron、多層パーセプトロン)とは異なります。
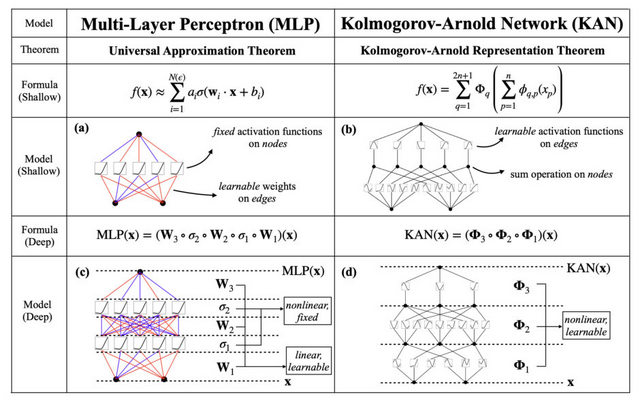
MLPでは、入力された数字を変換して出力しますが、点(ニューロン)とそれらを繋ぐ線(エッジ)で複雑に構成されたネットワークを通過しながら変換していきます。通常、ニューロンからの情報をエッジで重みによる掛け算を行い、次のニューロンで足し合わせて活性化関数で変換を行い、次のニューロンへと出力します。
MLPでは活性化関数はニューロンに置いてありますが、KANではニューロン同士をつなぐエッジに活性化関数を配置しています。さらに、MLPの活性化関数が固定されているのに対し、KANではスプライン(区分多項式)を用いた学習可能でパラメータ化された活性化関数を使用しています。スプラインは任意の滑らかな曲線を表現できるため、MLPの線形重みに比べてより柔軟で精密な非線形変換を可能にし、全体の表現力を向上させています。
この一見単純な変更により、KANはMLPと比較して、精度で優れた性能を発揮します。実験において、小規模なKANが、大規模なMLPと同等かそれ以上の精度を、データフィッティングや偏微分方程式(PDE)の解法において達成しています。またKANはMLPに比べてパラメータ効率が良く、少ないパラメータで同等またはそれ以上の性能を発揮します。
KAN: Kolmogorov-Arnold Networks
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljačić, Thomas Y. Hou, Max Tegmark
Paper | GitHub
1手先のトークン予測ではなく、4手先のトークンを同時に予測するモデルをMetaなどが開発
大規模言語モデルは通常、次のトークン予測という学習方法で訓練されます。これは、入力テキストの次に来る単語を1つずつ順番に予測していく方法です。
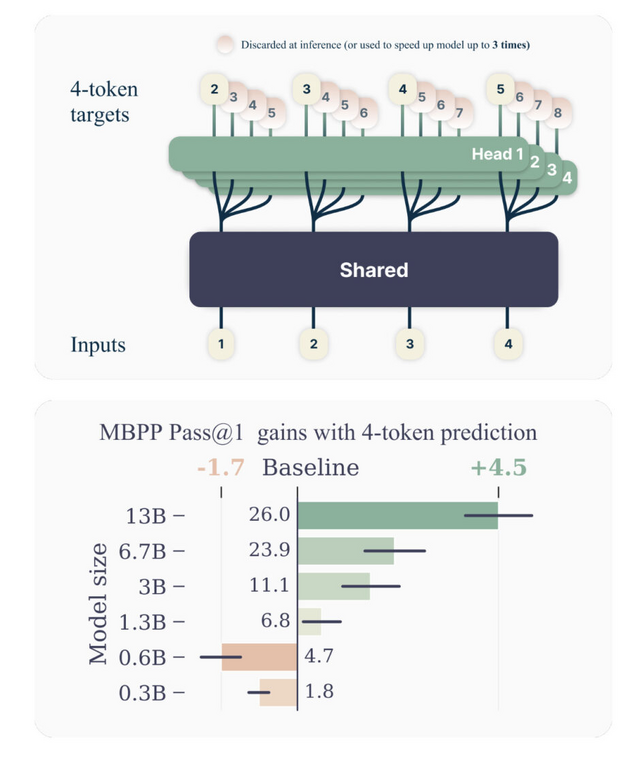
しかし、この研究で提案されている多重トークン予測という手法では、次の単語だけでなく、その先の複数の単語も同時に予測するようモデルを訓練します。例えば、4トークン予測の場合、次の4つの単語を一度に予測するわけです。
この多重トークン予測は、大規模言語モデルの性能を向上させるのに非常に有効であることが実験的に示されました。特にモデルのサイズが大きくなるほど、その効果が顕著になります。コーディングタスクなどでは、従来のトークン予測と比べて10%以上の精度向上が見られました。
また、多重トークン予測で訓練したモデルは推論時の速度も速くなります。先読みした複数の予測結果を利用する推論手法を使うことで、最大で3倍の高速化を実現できました。
Better & Faster Large Language Models via Multi-token Prediction
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, Gabriel Synnaeve
Paper
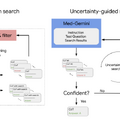
医療分野に特化したマルチモーダル大規模言語モデル「Med-Gemini」をGoogleが開発
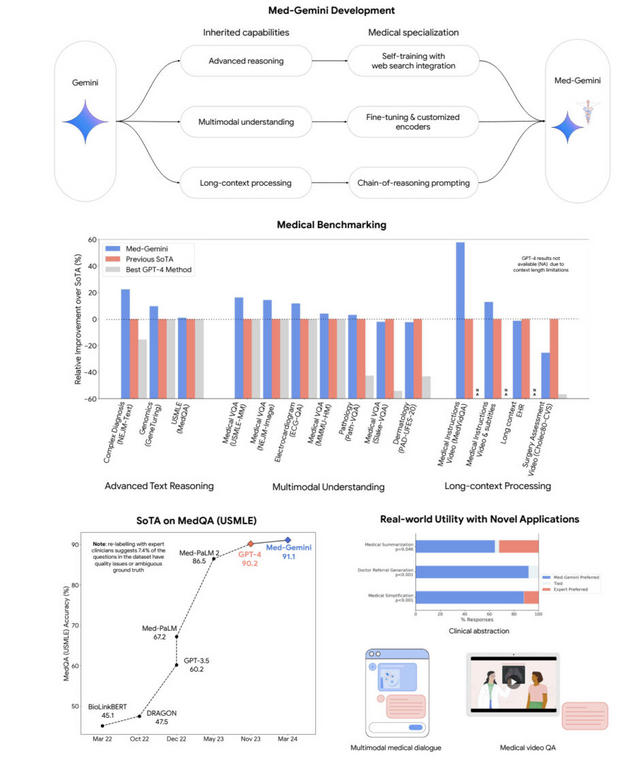
「Med-Gemini」は、Googleが開発した大規模マルチモーダル言語モデル「Gemini」を基に、医療分野に特化して開発されたAIモデルファミリーです。テキストデータだけでなく、画像や動画なども統合的に理解・生成できます。
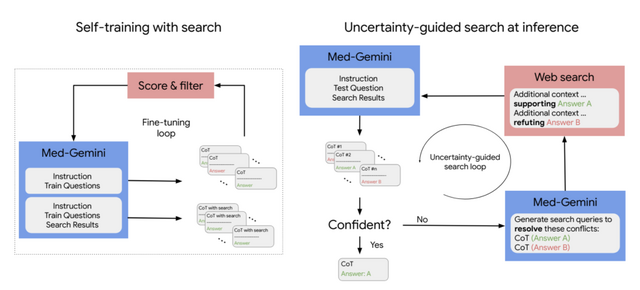
自己学習とウェブ検索の統合により、最新の医学情報を活用した複雑な臨床推論や、ファインチューニングとカスタムエンコーダーを用いた放射線画像、病理画像、心電図などの多様な医療データ形式への適応ができます。また、MoE(Mixture of Experts)アーキテクチャにより、数百万トークン以上におよぶ長い電子カルテデータや医療動画の効率的な処理も可能です。
14の医療ベンチマークタスクで評価したところ、10のタスクで最先端の性能を達成しました。特にMedQA(医師国家試験問題データセット)では91.1%の高精度を実現し、専門医の平均正解率を上回る結果となりました。
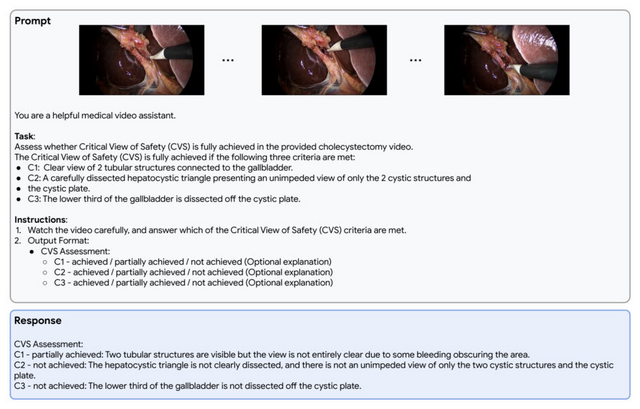
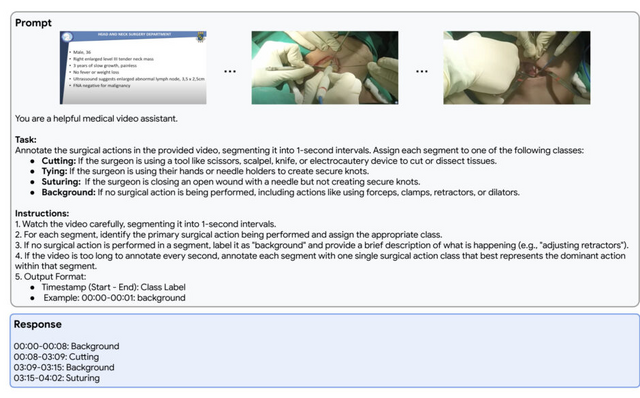
また、実際の臨床応用を見据え、退院時サマリー作成や専門医への紹介状作成など、医師の作業を補助するタスクでも専門医と同等以上の品質を示しました。さらに、皮膚科や放射線科におけるマルチモーダル対話、外科手術動画の解析など、将来の応用例についても議論されています。

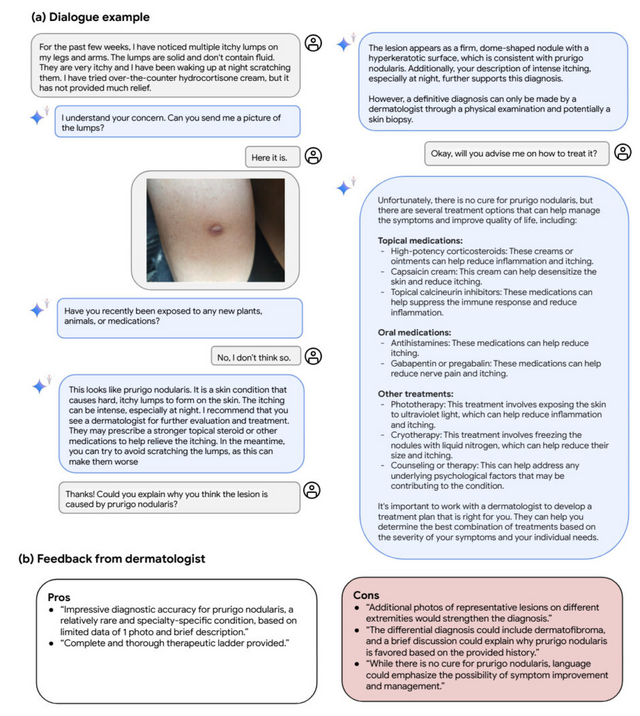
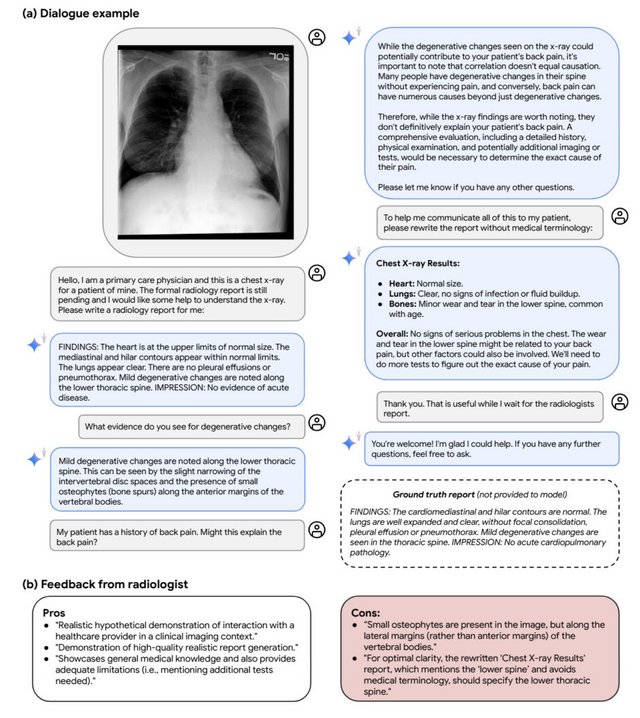
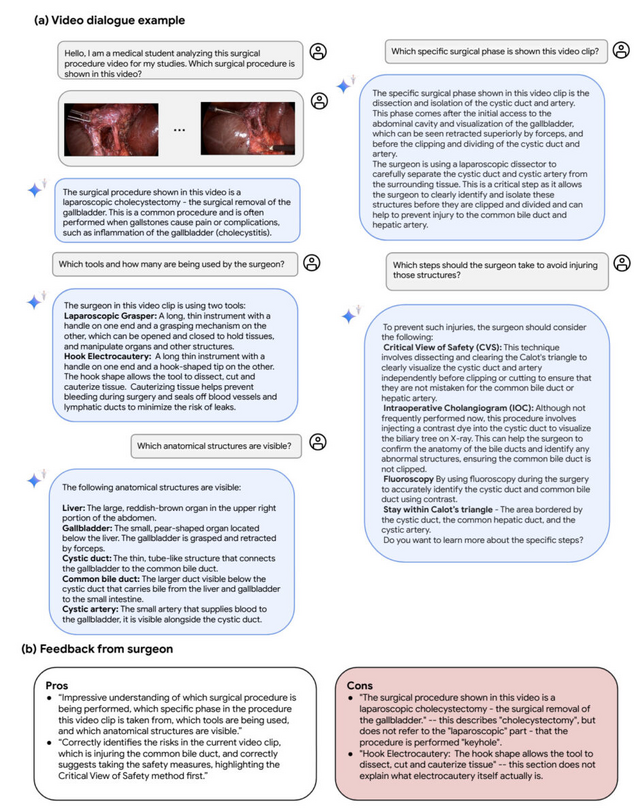
Capabilities of Gemini Models in Medicine
Khaled Saab, Tao Tu, Wei-Hung Weng, Ryutaro Tanno, David Stutz, Ellery Wulczyn, Fan Zhang, Tim Strother, Chunjong Park, Elahe Vedadi, Juanma Zambrano Chaves, Szu-Yeu Hu, Mike Schaekermann, Aishwarya Kamath, Yong Cheng, David G.T. Barrett, Cathy Cheung, Basil Mustafa, Anil Palepu, Daniel McDuff, Le Hou, Tomer Golany, Luyang Liu, Jean-baptiste Alayrac, Neil Houlsby, Nenad Tomasev, Jan Freyberg, Charles Lau, Jonas Kemp, Jeremy Lai, Shekoofeh Azizi, Kimberly Kanada, SiWai Man, Kavita Kulkarni, Ruoxi Sun, Siamak Shakeri, Luheng He, Ben Caine, Albert Webson, Natasha Latysheva, Melvin Johnson, Philip Mansfield, Jian Lu, Ehud Rivlin, Jesper Anderson, Bradley Green, Renee Wong, Jonathan Krause, Jonathon Shlens, Ewa Dominowska, S. M. Ali Eslami, Katherine Chou, Claire Cui, Oriol Vinyals, Koray Kavukcuoglu, James Manyika, Jeff Dean, Demis Hassabis, Yossi Matias, Dale Webster, Joelle Barral, Greg Corrado, Christopher Semturs, S. Sara Mahdavi, Juraj Gottweis, Alan Karthikesalingam, Vivek Natarajan
Paper
大規模言語モデルが答えに相当するベンチマークを事前に学習し、高い評価を出していた? AIカンニング問題を指摘した研究
大規模言語モデル(LLM)は数学的推論のベンチマークで高い性能を示していますが、訓練データに評価用ベンチマークの問題と類似したデータが混入している可能性が指摘されています。このデータ汚染により、LLMの真の推論能力ではなく、単に訓練時に見た問題を丸暗記(カンニング)しているだけなのではないかという懸念があります。
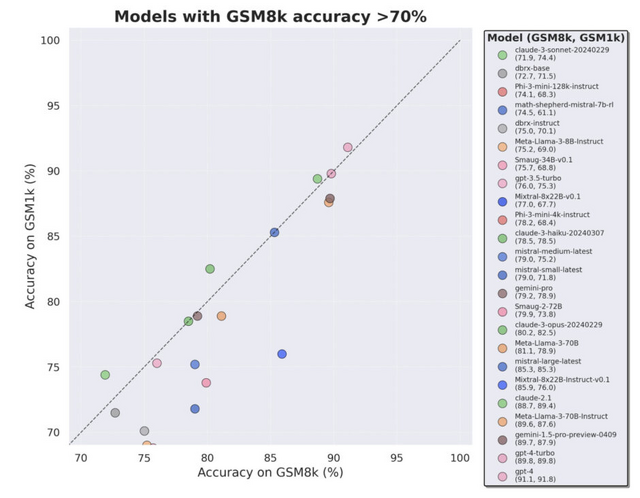
そこでこの研究では、小学校レベルの算数問題のベンチマークである「GSM8k」(Grade School Math 1000)と同等の難易度と特徴を持つ新しいデータセット「GSM1k」を作成しました。GSM1kは、人間のアノテーターのみによって作られ、いかなるLLMも使用されていないため、データ汚染の心配がありません。
そして、高性能のオープンソースおよびクローズドソースのLLMをGSM1kで評価したところ、いくつかのモデルではGSM8kと比べて最大13%も精度が低下することがわかりました。特にPhiやMistralなどのモデルファミリーでは、ほぼ全てのモデルサイズでGSM8kへの過剰適合が見られました。一方、Gemini、GPT、Claudeなどの最先端モデルは過剰適合の兆候をほとんど示しませんでした。むしろClaude-3-opusとClaude-3-sonnetでは、GSM1kの方がGSM8kよりも性能が2%程度高くなっています。
さらに、モデルがGSM8kの例を生成する確率と、GSM8kとGSM1kの性能差には正の相関があることもわかりました。つまり、多くのモデルがGSM8kの問題を部分的に記憶している可能性が示唆されたのです。
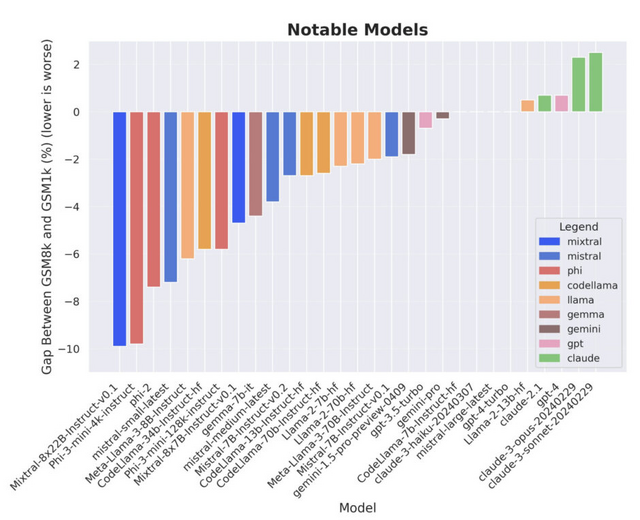
A Careful Examination of Large Language Model Performance on Grade School Arithmetic
Hugh Zhang, Jeff Da, Dean Lee, Vaughn Robinson, Catherine Wu, Will Song, Tiffany Zhao, Pranav Raja, Dylan Slack, Qin Lyu, Sean Hendryx, Russell Kaplan, Michele Lunati, Summer Yue
Paper
一貫性の高い長編ビデオをテキストから生成するAIモデル「StoryDiffusion」
近年、拡散モデルを用いた高品質な画像生成が急速に発展しています。しかし、一連の生成画像の中で、特に被写体や複雑な詳細を含む画像で、一貫したコンテンツを維持することは大きな課題となっています。
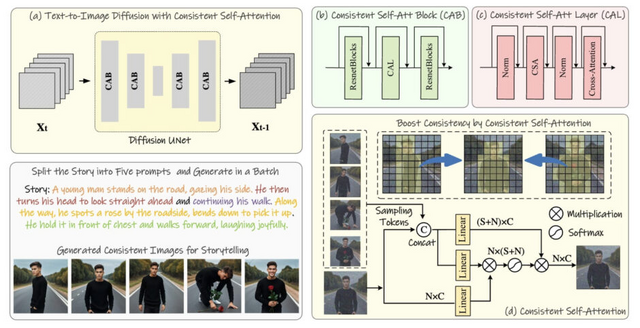
本研究では、「Consistent Self-Attention」と呼ばれる新しい自己注意機構の方法を提案しています。これにより、生成された画像間の一貫性が大幅に向上し、ゼロショットの方法で一般的な事前学習済みの拡散ベースのText-to-Imageモデルを拡張できます。
また、この手法を長編ビデオ生成に拡張するために、「Semantic Motion Predictor」と名付けられた新しい意味空間時間モーション予測モジュールを導入しています。このモジュールは、提供された2つの画像間のモーション条件を意味空間で推定するようにトレーニングされています。
これにより、生成された一連の画像がスムーズな遷移と一貫した被写体を持つビデオに変換されます。特に長編ビデオ生成の文脈では、潜在空間のみに基づくモジュールよりも大幅に安定しています。
一貫性のある画像生成では、定性的・定量的評価およびユーザースタディにおいて、StoryDiffusionが既存手法(IP-Adapter、PhotoMaker)を上回る性能を示しました。特に、生成された画像間での人物の一貫性と、テキストとの対応の自然さが優れていました。
ビデオ生成でも、StoryDiffusionは他の最新手法(SEINE、SparseCtrl)と比較して、よりスムーズで自然な動きのビデオを生成できました。定量評価とユーザースタディの両方で、StoryDiffusionの生成するビデオの質の高さが確認されました。


StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, Qibin Hou
Project | Paper | GitHub | Demo