



1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第38回目は、生成AI最新論文の概要5つを紹介します。
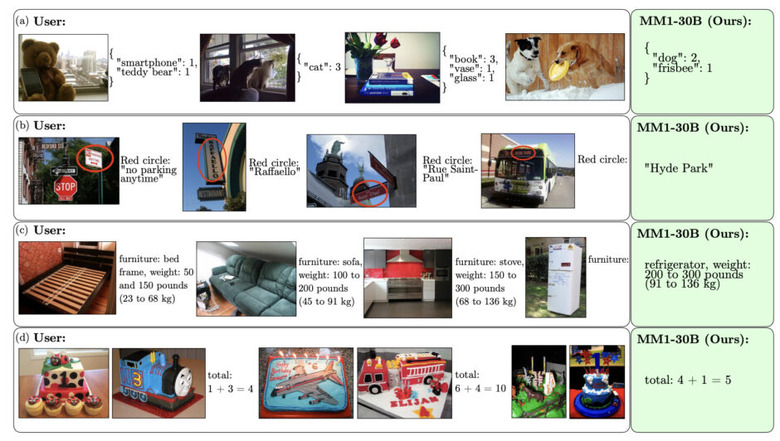
Appleが最大300億パラメータを持つマルチモーダル大規模言語モデル「MM1」を開発
既存のマルチモーダル大規模言語モデル(MLLM)は、透明性の観点からクローズドモデルとオープンモデルの2つに分類できます。どちらのモデルも、マルチモーダル事前学習に関するアルゴリズム設計の選択肢に至るまでのプロセスについては、ほとんど公開していません。つまり、モデルの最終的な構成については情報が提供されていても、そこに至るまでの試行錯誤や意思決定プロセスは明らかにされていないのが現状です。
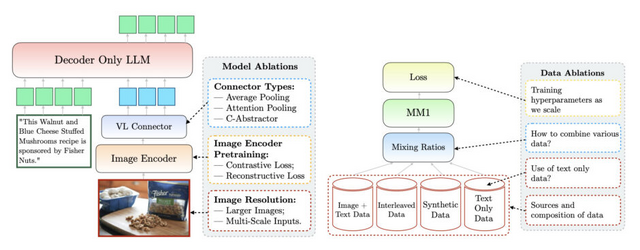
そこでAppleは、高性能なMLLMを探るべく、モデルの構造や学習に使うデータの選び方がモデルの性能にどのように影響するかなどを詳しく分析した論文を公開しました。研究チームはアブレーション実験を行い、分析した結果、モデルアーキテクチャの決定や事前学習データの選択などにおいて、いくつか重要なポイントがわかりました。
例えば、画像とキャプション、画像と文章が混ざったデータ(インターリーブ画像テキストデータ)、文章だけのデータを上手に組み合わせて事前学習を行うことが、少ない例でも高い性能を出すために大切だということがわかりました。
また、モデルの性能には、画像エンコーダの損失と容量、画像の解像度(高い解像度が良い)、画像エンコーダを事前学習するために使用されるデータの種類や量が大きく影響することがわかりました。一方で、画像と言語をつなぐ部分の設計はあまり重要ではないことがわかりました。
これらの知見などを基に、研究チームは3B(30億)、7B(70億)、30B(300億)のパラメータを持つMLLMファミリー「MM1」を構築。アーキテクチャでは、事前学習済みの画像エンコーダと言語モデルを組み合わせています。画像エンコーダにはCLIP等で学習したViT(Vision Transformer)、そしてC-Abstractorを使用しています。
事前学習データでは、キャプション付き画像データ(45%)、インターリーブ画像テキストデータ(45%)、テキストのみデータ(10%)の割合で組み合わせています。知見の一つに、インターリーブ画像テキストデータとテキストのみデータは、few-shotとテキストのみのタスクの性能に重要であるのに対し、キャプションデータはzero-shotの性能向上に寄与することが示されています。
MM1は、「mixture-of-experts」(MoE)も導入しています。指示ファインチューニングでは、GPT-4および GPT-4Vで生成されたデータ(例えばShareGPT-4V)や、VQAv2、GQA、OKVQA、COCO Captions、TextCaps、DVQA、ChartQA、AI2Dなど多数のデータセットを使用しています。
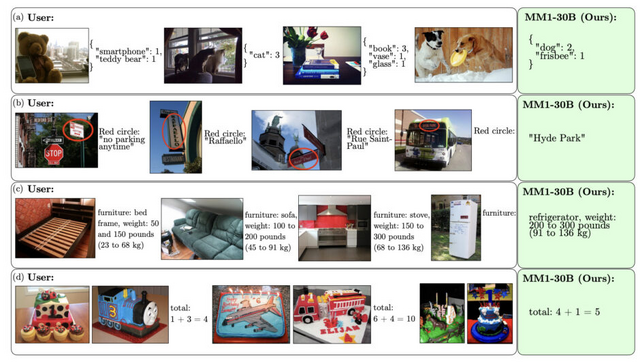
評価実験では、事前学習の指標で30BでSOTAを達成し、3Bや7Bのモデルサイズでも同等のサイズの他のモデルと比較して高い性能を達成しました。また指示ファインチューニング後のモデルでは、12のマルチモーダルベンチマークで競争力のある性能を示しました。


MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Floris Weers, Anton Belyi, Haotian Zhang, Karanjeet Singh, Doug Kang, Hongyu Hè, Max Schwarzer, Tom Gunter, Xiang Kong, Aonan Zhang, Jianyu Wang, Chong Wang, Nan Du, Tao Lei, Sam Wiseman, Mark Lee, Zirui Wang, Ruoming Pang, Peter Grasch, Alexander Toshev, Yinfei Yang
Paper
OpenAIなどのクローズド大規模言語モデルの一部を許可なく取得する攻撃、Googleなどが開発
Google DeepMindなどの研究者が、OpenAIのGPTやGoogleのPaLM-2などのクローズドな大規模言語モデル(LLM)から、モデルの一部を開発元に許可を得ることなく取得する攻撃手法を開発しました。
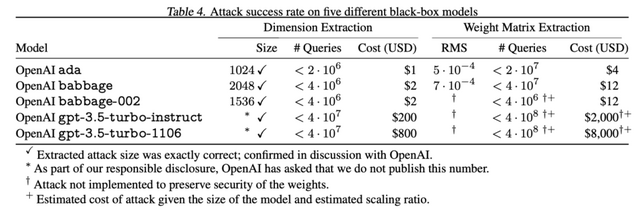
この攻撃手法では、言語モデルの最終層である「Embedding Projection Layer」に着目し、モデルのAPIに戦略的にクエリを送ることで、最終層の重みを復元します。これにより、隠れ層の次元数が分かり、モデルの規模を推定できるようになります。
実験では、わずかな費用でOpenAIのadaモデルとbabbageモデルの最終層全体を復元し、隠れ層のサイズを特定することに成功しました。具体的には、adaモデルが1024次元、babbageモデルが2048次元の隠れ層を持つことが明らかになりました。
gpt-3.5-turboモデルにも同様の攻撃を仕掛け、隠れ層の次元数を特定することができました。しかし、論文内では「責任ある情報公開の一環として、OpenAIはこの数値を公表しないよう求めている」という記載とともに、gpt-3.5-turboの隠れ層のサイズは伏せられています。
研究者らは、論文公開前に、この攻撃手法の詳細を影響を受けるモデル開発元に開示しており、情報共有を受けたGoogleやOpenAIはすでに防御策を実装しています。
Stealing Part of a Production Language Model
Nicholas Carlini, Daniel Paleka, Krishnamurthy Dj Dvijotham, Thomas Steinke, Jonathan Hayase, A. Feder Cooper, Katherine Lee, Matthew Jagielski, Milad Nasr, Arthur Conmy, Eric Wallace, David Rolnick, Florian Tramèr
Paper
GPT-3.5の隠れ層のサイズを約4096と推定。非公開LLMの中身を抽出する手法
南カリフォルニア大学に所属する研究者らは、OpenAIなどが発表している非公開の大規模言語モデルの中身を推定する手法を開発しました。各言語モデルのAPIクエリから、非公開の情報を取得します。
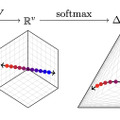
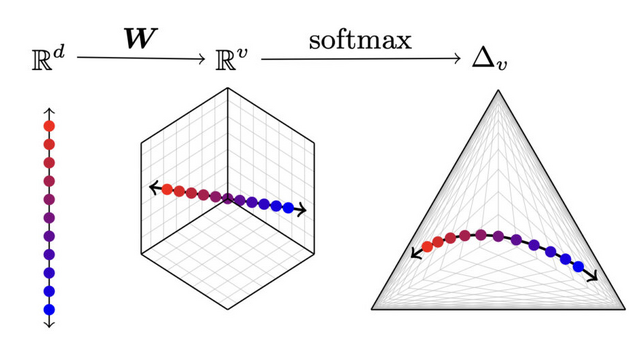
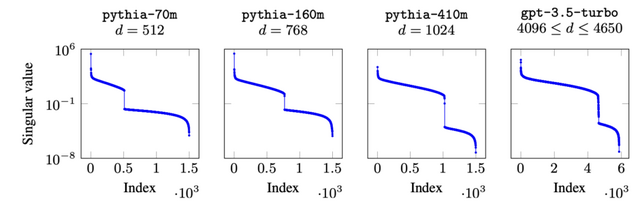
この攻撃はモデルの出力層に着目しており、中でもほとんどの最新の言語モデルが「softmax bottleneck」と呼ばれる問題を抱えているという知見からです。これにより、モデルの出力が全体の出力空間の中でも低次元のベクトル空間に制限されてしまいます。
この性質を利用することで、言語モデルの隠れ層のサイズや出力層のパラメータ推定などが手頃なコストで取得できることを示しました。
実際にこの手法を用いることで、OpenAIのgpt-3.5-turboモデルの埋め込みサイズが約4096(4096から4650の間)であると推定できたそうです。

Logits of API-Protected LLMs Leak Proprietary Information
Matthew Finlayson, Swabha Swayamdipta, Xiang Ren
Paper
WebページのスクリーンショットからHTMLコードを生成するAIモデル「Sightseer」をHugging Faceが開発
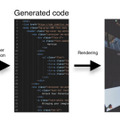
視覚言語モデル(VLM)の進歩により、画像キャプション生成や質問応答、光学文字認識(OCR)など、様々なタスクでの性能が大きく向上しています。しかし、Webサイトやウェブコンポーネントのスクリーンショットから使用可能なHTMLコードへの変換については、ほとんど探求されていません。
その主な理由は、HTMLコードとそれに対応するスクリーンショットのペアからなる、大規模で高品質なデータセットが存在しないことにあると考えられます。
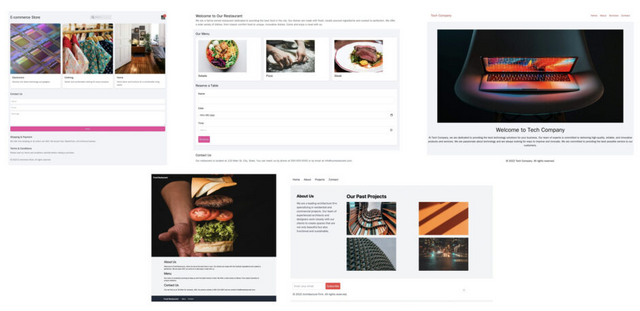
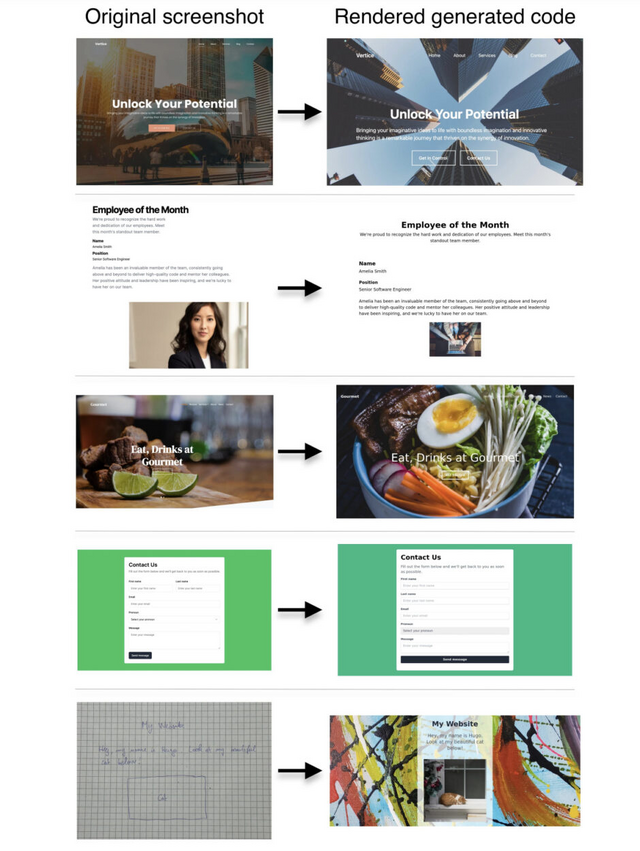
そこで本研究では、200万組のHTMLコードとスクリーンショットのペアで構成されるオープンソースの合成データセット「WebSight」を開発しました。まず、大規模言語モデル(LLM)を使用して多様なウェブサイトのコンセプトを生成し、さらにコーディングに特化したLLMを用いて高品質なHTMLコードを生成することで、データセットを構築しています。
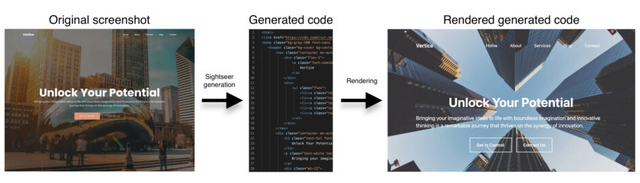
続いて、この大規模データを用いて、80億のパラメータを持つVLMをファインチューニングし、特化モデル「Sightseer」を開発しました。その結果、ウェブページのスクリーンショットから機能的なHTMLコードへの変換において優れた性能を示しました。さらに、手書きのスケッチからHTMLコードへの変換など、学習していないシナリオにも適応できる汎用性も見られました。
Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset
Hugo Laurençon, Léo Tronchon, Victor Sanh
Paper | Hugging Face
実世界に強いマルチモーダル大規模言語モデル「DeepSeek-VL」
DeepSeekは、オープンソースのマルチモーダル大規模言語モデル(MLLM)であるDeepSeek-VLシリーズ(1.3Bと6.7Bの2種類)を提案しています。
事前学習には、Webサイトのスクリーンショットや論文など、実際によく使われるデータを幅広く集めました。一方で、指示チューニング用のデータは、GPT-4VやGeminiという他のAIを使って集めました。
ビジュアルモジュールは、推論コストを効果的に管理するために固定トークン予算内で高解像度の視覚入力を最適に利用するように設計されています。具体的には、384×384の解像度で大まかな意味抽出を行うエンコーダと、1024×1024の解像度で詳細な視覚情報を捉える高解像度エンコーダを組み合わせたハイブリッドビジョンエンコーダを採用しています。これにより、1024×1024の解像度の画像を576トークンに効率的に圧縮できます。
モデルの反復実験では、大規模化する前に小規模で実験を行いますが、1Bモデルではベンチマークで適切な性能を発揮できません。そこで、評価プロトコルを選択肢の予測から尤度の比較に変更し、事前学習段階で少量の指示チューニングデータを混ぜることで、1Bモデルでも適切な性能を達成できるようにしました。
その結果、DeepSeek-VLは同規模の他のMLLMと比較して、実世界のアプリケーションで優れたユーザー体験を実現し、言語中心のタスクでも堅調な性能を維持しながら、幅広いビジョン言語ベンチマークで最先端または競争力のある性能を達成しています。そして、1.3Bと7Bの2つのバージョンを公開しました。


DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, Yaofeng Sun, Chengqi Deng, Hanwei Xu, Zhenda Xie, Chong Ruan
Project | Paper | GitHub


















