








テクノエッジでは人気連載 「生成AIグラビアをグラビアカメラマンが作るとどうなる?」から生まれたオンラインセミナー、グラビアカメラマンが教える、生成AIグラビア実践ワークショップを開催しています。3回目となる次回は12月21日、ご興味のあるかたはぜひお申し込みください。クラウドGPUサービスをご提供しますので、自前のハイエンドPCがなくても気軽に参加できます(編集部)

第13回目のControlNet Canny / Depth / OpenPoseを軽くおさらい
連載第13回目ではControlNetのCanny、Depth、OpenPoseをご紹介した。続きに入る前に軽くおさらいすると、ControlNetは指定した画像を使って、構図や絵柄、ポーズ、そして書かれている内容(Prompt相当)などを抽出し、生成する画像を固定する方法だ。
生成AIグラビアをグラビアカメラマンが作るとどうなる?連載記事一覧

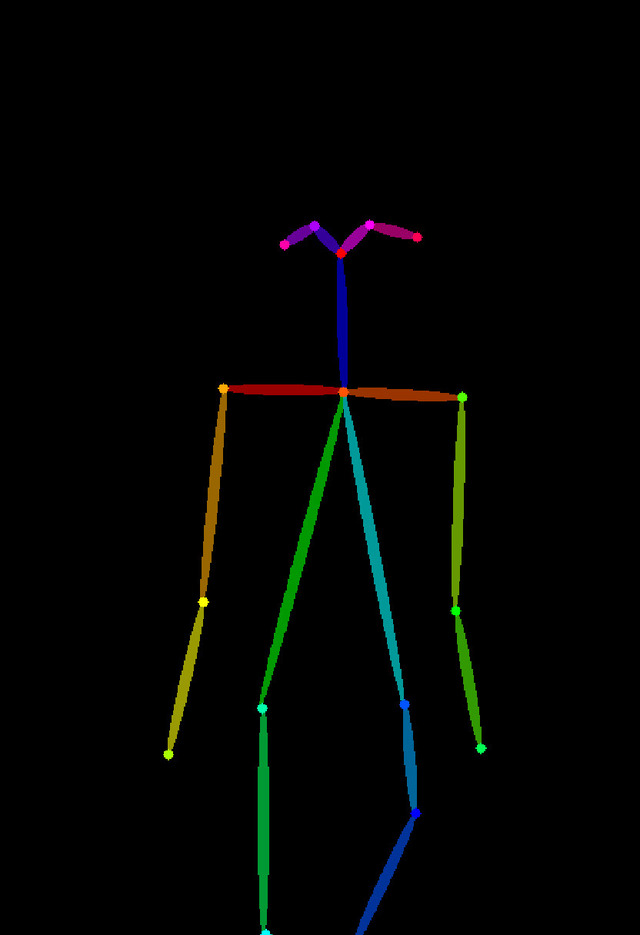
以下の画像から分かるように、Cannyは線で、Depthは深度で、OpenPoseは骨の形状で生成する画像をコントロール出来る。
 |  |
 |  |
元画像
Canny
Depth
OpenPose
使い分けとしては、Cannyは線なので、顔の輪郭も含め、結構細かい部分まで影響する、Depthは深度なのでCannyよりは軽い感じか。いずれにしてもこの2つは背景も含め元画像にかなり似たものとなる。
対してOpenPoseはご覧のように骨だけなので、背景は全く影響を受けず、例えばより細身や太めなど体型の指定は自由。加えて骨の種類が変えられ、openpose、openpose_face、openpose_faceonly、openpose_full、openpose_handの指定が可能。順に体だけ、顔+体、顔だけ、顔+体+手、体+手…出したい絵柄を考えて選択することが出来る。
ただし立ってる時はまだいいのだが、座りなどより複雑なポーズになると、この骨自体では表現し辛く、出てくる画像も割と大雑把な感じとなるだろうか。
各ControlNet用のModelのダウンロードはここから行う。ファイル名に_sd15_や_xl_、_Canny_などが含まれているので該当するのはどれか?見れば分かるはずだ。ファイルのコピー場所は、 [AUTOMATIC1111フォルダ]/models/ControlNet 。
以上が第13回目のざっくりしたおさらいとなる。
その2はControlNet Reference / Revision / IP-Adapter
今回扱うのはReference、Revision、IP-Adapter。これら3つの特徴は、Canny、Depth、OpenPoseのように物理的に構図などを固定するのではなく、画像に書かれているものが何か? を認識して、生成する画像を固定する。
Reference
Referenceは、文字通りリファレンス。つまり指定した画像をリファレンスとして、似ている画像を生成する。タイプは3つあり、
reference_only
顔を構成するパーツや雰囲気を似せるreference_adain
顔に加え構図も似せるreference_adain+attn
上記2つの合わせ技
 |  |
 |  |
元画像
reference_only
reference_adain
reference_adain+attn
とこんな感じだ。元画像は日本人だと少し変わっても分からないのであえて西洋系にした。目鼻立ちがはっきりしているので、似ているかどうかも分かりやすい。Promptは共通で「photo of a woman,20 years old」。
生成された画像全てリファレンス画像に似た感じの女性が出てきた。3タイプの違いもなるほどと言ったところ。
タイプの使い分けは、reference_adain+attnが全部入なので一番似る。ただ構図まで似ては面白くない時は、これ以外を選ぶことになる。顔だけならreference_onlyが無難だろうか。
Revision (SDXLのみ対応)
RevisionはSDXL専用でSD 1.5では使えない。機能的には画像にある内容を内部処理的にPromptへ置き換えている感じだろうか。オプションは以下の2つ。
revision_clipvision
プロンプトを参照しながらrevisionrevision_ignore_prompt
画像情報のみを使ってrevision。Promptは無視する
これまで説明した機能と根本的に違うのは画像として何も固定していないこと。描かれている内容をPromptとして抽出しているだけなので、Modelによっては効かない、呪文の効果が薄いものも含まれ、使用するModelやSamplerの設定によっても生成される画像は大きく変わることになる。
 |  |
 |  |
元画像
revision_ignore_prompt
revision / Prompt無し(revision_ignore_promptと同じになる)
revision / Prompt「woman」 / Control Weight 2
ただ以前Fooocus-MREで試した時もそうなのだが、イマイチ使いどころが良くわからない。
まずrevision_ignore_prompt。これは分かりやすく、Promptは無視。画像にある情報だけで画像を生成する。結果を見てもなるほど的な感じだ。次にrevisionでPrompt無しの場合は、revision_ignore_promptと同じ結果となる。
ここまではいいのだが、謎なのがrevisionでPromptを入力したケース。ほとんどPromptに引っ張られ、ControlNet側のrevisionが効かないのだ。Control Weight 2にすると少しPromptとのミックス的な結果となるが、Promptでwomanだけなく、いろいろ記述するとControl Weight 2としてもPrompt側の影響が強くなる。
改めて検証しても以前?と思った部分は変わらずでどうなっているのか謎のままだ。
IP-Adapter
IP-Adapterも動きとしてはRevisionと(多分)同じ。ただSD 1.5でも使用可能でPromptの抽出はimg2img / Interrogate CLIPにより近い。
例えばrevisionで使った元画像をimg2img / Interrogate CLIPすると
a woman in a gray dress posing for a picture in the woods with trees in the background and fog in the air, Du Qiong, neo-romanticism, a marble sculpture, phuoc quan
と出てくる。これをtxt2imgへコピペし、生成したのが一枚目(左)の画像。うまく内容を拾ってるのが分かる。
 |  |
Interrogate CLIPをPromptに入れ作った画像
IP-Adapter適応後 / Promptに「japanese woman」
二枚目(右)はIP-Adapterを使い。Promptに「japanese woman」を入れたもの。確かに背景や衣装の雰囲気はそのまま引き継ぎ、顔は日本人っぽくなっている。同じ画像をPromptにするrevisionと比較しても非常に分かりやすい結果となった。
画像の内容をPromptへ変換する時、文字で情報が欲しい時はimg2img / Interrogate CLIPで作ってtxt2imgへコピペ、そして修正。元画像と合わせてそのままPromptで内容を加え生成する時はIP-Adapter…と、使い分ける感じだろうか。
なお、これら3つを使う時、
Reference
Model不要Revision
Modelは無いものの、初期使用時裏で3.5GBほどのデータをダウンロードするIP-Adapter
https://huggingface.co/lllyasviel/sd_control_collection/tree/main
この様に、手動でダウンロードする必要があるのはIP-Adapterのみとなる。
+αはOutfit Anyone
AUTOMATIC1111などを触ったことがある人なら、例えばカフェでのコーヒーカップや手に持ったスマホが巨大だったり極小だったり適当な形だったり、これはないだろ!(笑)的な経験があるかと思う。以前この連載でサーフボードを抱える画像を生成した時も笑えるような物がいっぱい出てきた。
衣服も白Tシャツやジーンズはともかく、同じ柄で同じ配置なものはまず出ない。そもそもStable Diffusionがそう言う仕掛けなのだから仕方ない。
従って美女やロケーションはいくらでも出せるが、肝心の商品は学習したところで適当にしか出ないため、結局広告にはそのままでは使えず、AIがやるか人がやるかは別として、Inpaint的な処理を加える必要がある。
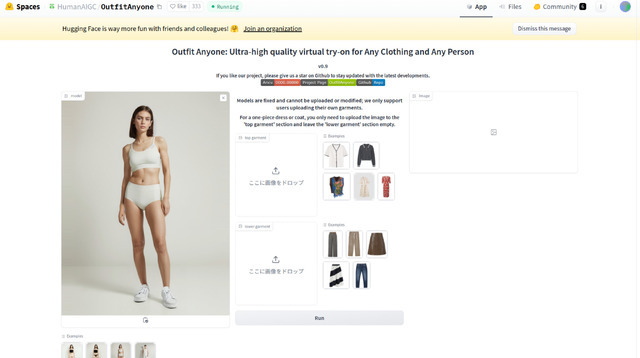
…だったのだが、衣服ならこれで行けるかも的技術が登場した。その名を「Outfit Anyone」。まだローカルで実行できるModelやコードは無く、Hugging Faceのデモだけになるものの、実際に動かすことが可能。操作したのが以下の画面キャプチャだ。
 |  |
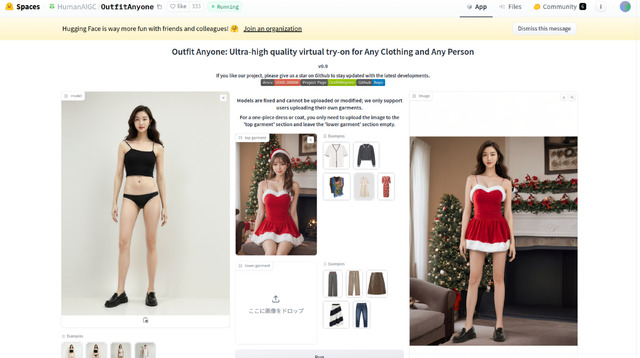 |  |
Hugging Faceのデモ
モデルとプリセットの上下を指定して着替えたところ
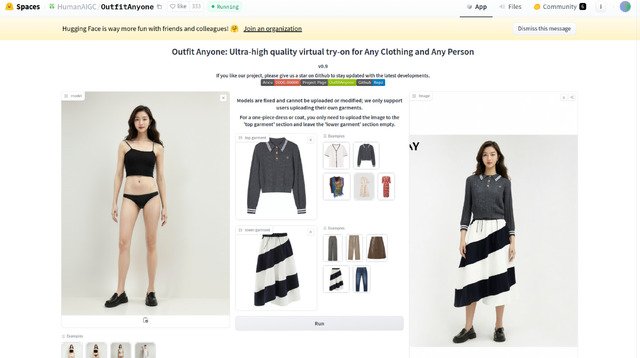
手持ちの画像をアップロードして変身
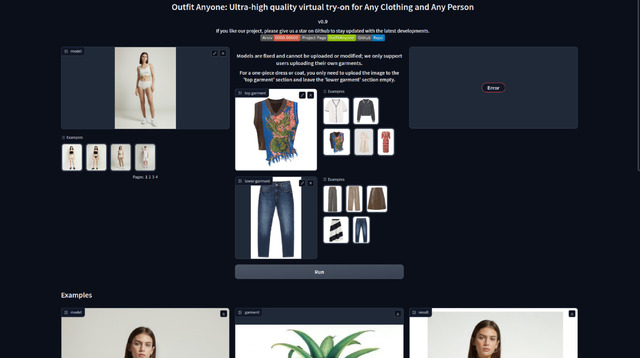
デモ用のコードはあるものの、実際はAPIを呼んでおり、そのKeyが不明なので動かない
左側にモデルが4人並んでおり選択可能。手持ちの画像をアップロードは技術的には出来るが、イタズラ防止の為、出来ないようになっている。右側に衣服上下が並んでいるので、好きな組み合わせを選び、実行すると、着替えた後の画像が生成される。
また衣服に関しては、任意の画像をアップロード可能で、試しに今回のサンタコスをアップロードし実行すると、ご覧のような結果となった。人と背景込みの画像の場合、人の部分は衣服だけ引き継がれ、背景はそのまま出てくる。左右の不足部分はOutpaintで書いているようだ。
Hugging Faceデモのコードを見つけたのでローカルで動かしたところ、画面は出て、モデルや衣服なども選択できるが、実行するとエラーになる。どうやら実際の変換はAPIで行っており、そのKeyが不明なので作動させることは出来なかった。残念。実際にローカルで動くようになったら改めてご紹介したい。
これまでいくら美女が出ても肝心の商品の再現性が低く、モデルやカメラマンの仕事は当面無くならないっと思っていたが、衣服だけでなく物もこの手のが開発されると、結構前倒になるかも知れない…。
今回締めのグラビア
今回締めのグラビアは、特に何の捻りも無い(笑)クリスマスグラビア!前回のグラビア同様、独自のWorkflow(FreeU、Kohya's HiresFix、FaceDetailer搭載)を使用したものだ(扉の写真も同様)。
ModelはTurbo系のdeliciousXL_xlTurbo。自作の顔LoRAは当てているものの、重み0.1なので隠し味程度。何時も同じ顔(=好みの顔)と言う噂もあり、ちょっと系統を変えてみた(笑)如何だろうか?

今年7月から始まった本連載、今回でもう15回目。多分今年はこれがラスト。第16回目は来年になる予定だ。内容は未定。少し早いがメリークリスマス and よいお年を!
生成AIグラビアをグラビアカメラマンが作るとどうなる?連載記事一覧テクノエッジでは人気連載 「生成AIグラビアをグラビアカメラマンが作るとどうなる?」から生まれたオンラインセミナー、グラビアカメラマンが教える、生成AIグラビア実践ワークショップを開催しています。3回目となる次回は12月21日、ご興味のあるかたはぜひお申し込みください。クラウドGPUサービスをご提供しますので、自前のハイエンドPCがなくても気軽に参加できます(編集部)














