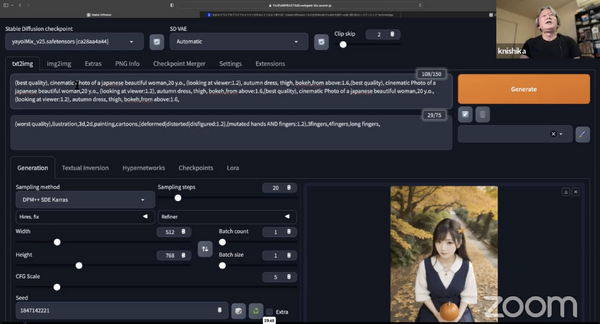




第9回にFooocus-MREを使ってControlNetをご紹介したが、一般的なAUTOMATIC1111での説明はまだだったので、改めて今回と次回で行いたい。

ControlNetって何?
「そもそもControlNetって何?」という話をしていなかったのでまずそこから。ザックリ言えば「指定した画像で生成する画像の絵柄を固定する方法」だ。固定には構図だったり、絵の中に含まれる要素(Prompt)だったり、顔(の雰囲気)だったり、いろいろなものが含まれる。
現在、AUTOMATIC1111 v1.6のControlNetの項目を見ると、Canny、Depth、NormalMap、OpenPose、MLSD、Lineart、SoftEdge、Scribble/Sketch、Segmentation、Shuffle、Tile/Blur、Inpaint、InstructP2P、Reference、Recolor、Revision、T2I-Adapter、IP-Adapter…これだけの項目が並んでおり、初心者だと何が何だかさっぱり分からない。
本連載では、個人的にSDXLがメインになってる関係上、SDXLでも使える主要なところを2回に分けて取り上げる。
ControlNetのインストール
その前にControlNetを使うにはsd-webui-controlnet extensionをインストールする必要がある。方法は簡単!
Extensions > Install from URL > URL for extension's git repository
https://github.com/Mikubill/sd-webui-controlnet.git[Install]
[Apply and restart UI]
これで再起動して使えるようになる。左側にControlNetの項目が増えているはずだ。また結構Updateしているので、[Check for updates]で何かの時に確認すると良い。
そしてControlNet用のModelをダウンロードして所定のフォルダへ入れる。今回はCanny、Depth、OpenPose、この3つを扱うので、ファイル名にこの名前があるものを事前にダウンロードしておく(次回はReference、Revision、IP-Adapterの予定)。
https://huggingface.co/lllyasviel/sd_control_collection/tree/main
[AUTOMATIC1111インストールフォルダ]/models/ControlNet
※ [AUTOMATIC1111インストールフォルダ]/extensions/sd-webui-controlnet/models でも良い
これで準備完了だ。
Canny
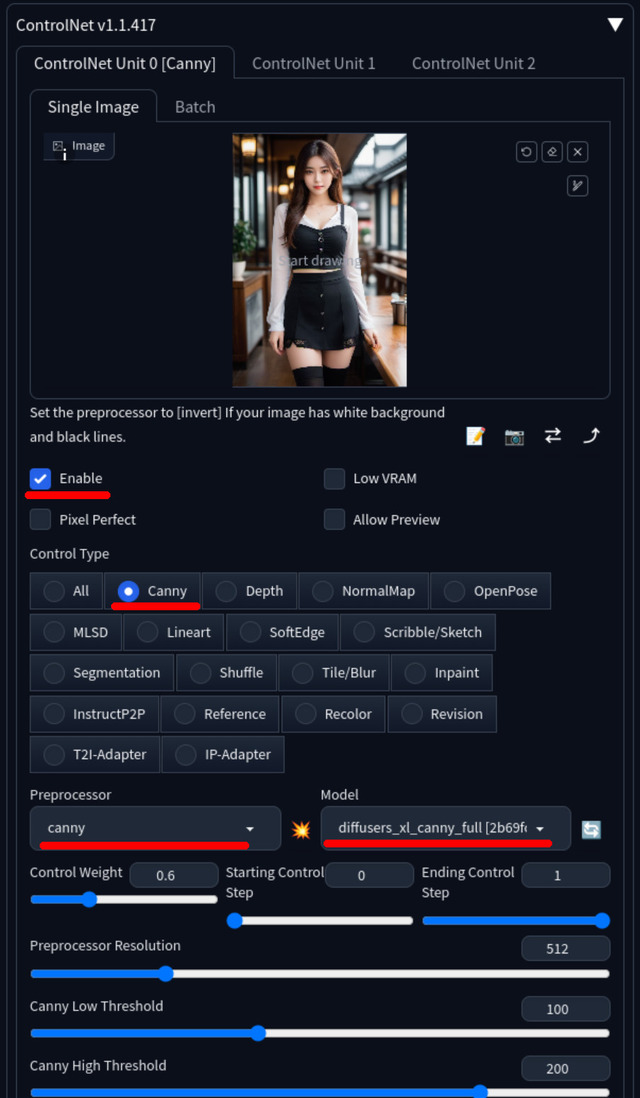
Cannyは線で生成する画像を固定する方法だ。ControlNetの設定方法は、
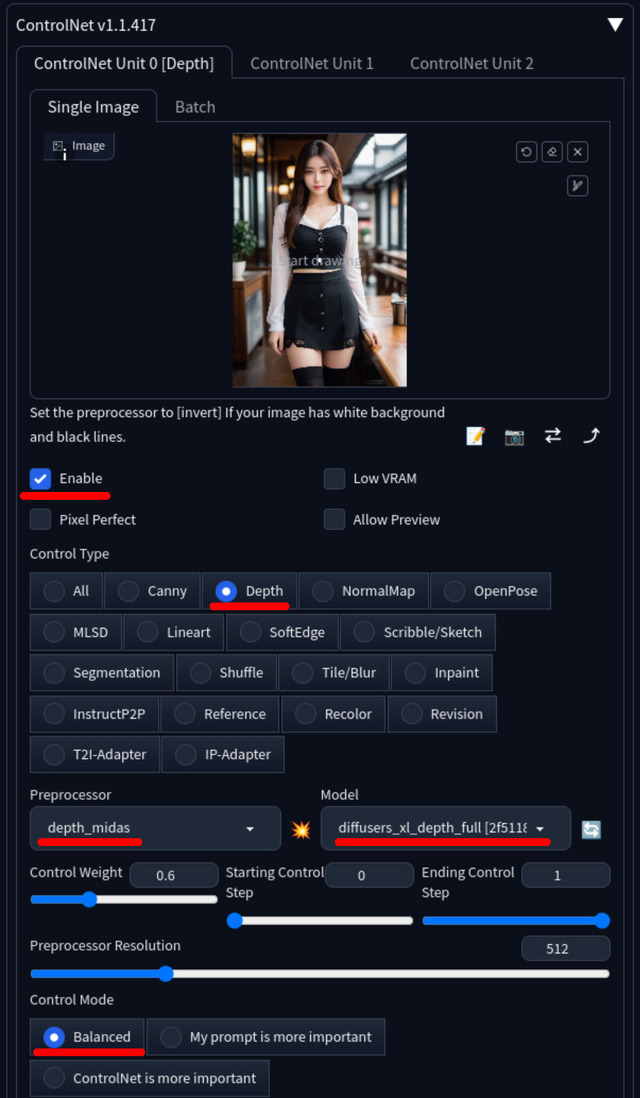
Canny を選ぶ
Preprocessor: Canny
Model: diffusers_xl_canny_full
※ この時 ファイル名に _sd15_ があるものはSD 1.5用なので選ばないSingle image へ元となる画像をセット
Enable にチェック
普通にPrompt / Negative Promptなどを何時も通り設定する
[Generate]ボタンを押す
これでPromptを反映しつつ元となる画像の構図で生成される。
 |  |
 |  |
元画像
ControlNet / Cannyの設定
Preprocessorが生成した画像
生成した画像(Promptで場所をCafeからOfficeへ)
Cannyにはいろいろな設定項目があるが、とりあえず触るとすれば、Control Weight、Balanced | My prompt is more important | ControlNet is more important…この2つだろうか。
前者はPromptの:1.0同様、効き具合=重みの調整。後者は、生成する画像をPromptとControlNetでバランス | Prompt優先 | ControlNet優先の指定ができる。
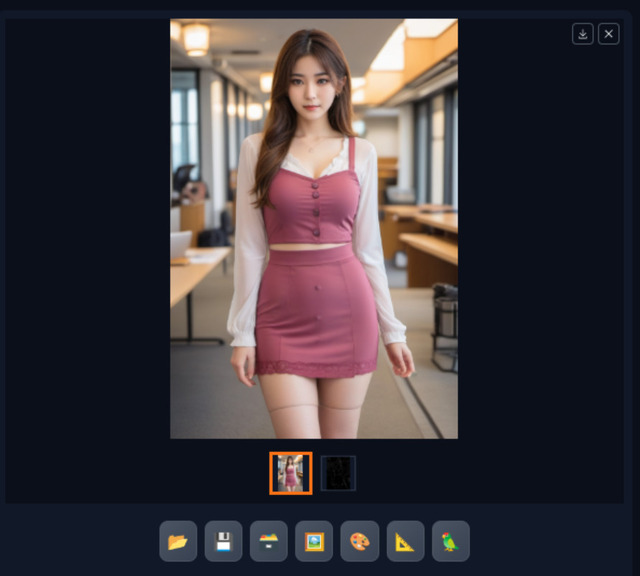 | 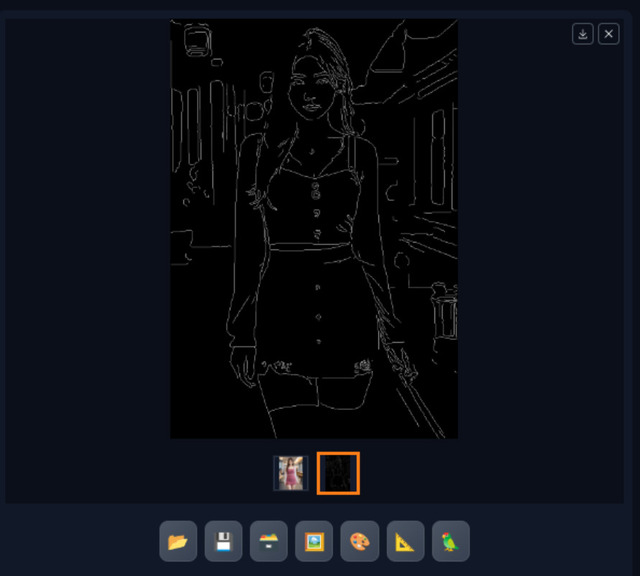 |
さて、生成した画像(1)を見ると、いつもより一つ増えている(2)(Cannyだと線だけの画像)。これは、元画像をPreprocessorが処理した画像となり、これをControlNet / Cannyが使って画像を生成している。
従って2回目以降はPreprocessor処理分だけ時間が無駄なので、この画像をダウンロードし、Single imageへセット、Preprocessor: none とすれば、1パス減らすことが出来る。またどこかへ保存しておけば、後で使いまわすことも可能だ。
Cannyの特性としてはPreprocessor処理後の画像からも分かるように、顔の輪郭や背景のラインなどがしっかり入っているため、生成した画像は顔も含めかなり近い状態になる。従って系統の違う別の顔にしたい時は不向きかも知れない。
線だけなので不要な線を消したり、逆に書き加えたりして、それを元画像に使うことも可能だ。
Depth
Depthは元画像の深度情報を使って画像を生成する。設定方法などはCannyのパターンと同じなので省略する。
 |  |
 |  |
元画像
ControlNet / Depthの設定
Preprocessorが生成した画像
生成した画像(Promptで場所をCafeからOfficeへ)
Depthは深度情報を使うためCannyほど細かい輪郭などは入っていない。構図は同じで、顔も含め違った感じにしたい時はDepthを使う方が無難だ。
OpenPose
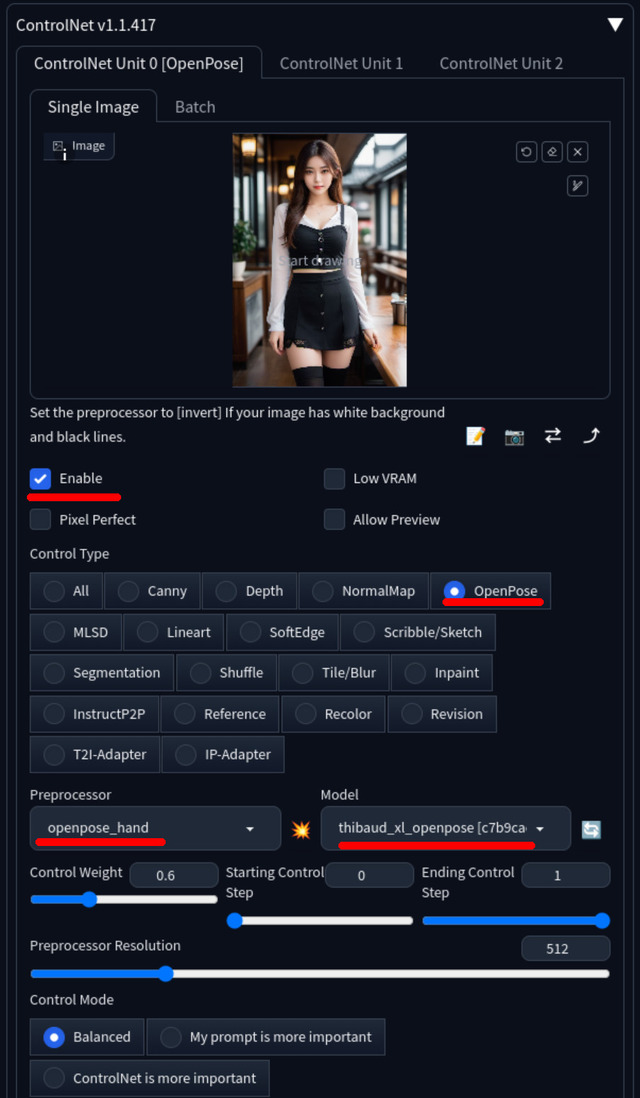
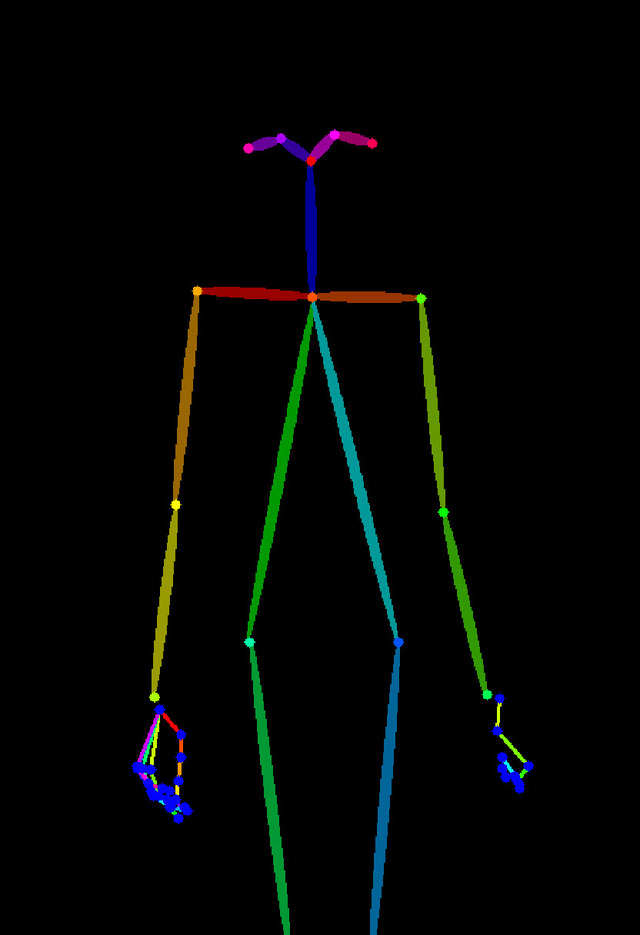
OpenPoseはPreprocessor処理後の画像が骨のようになっており、これまでのCannyやDepthと大きく違っている。この骨情報を元に画像を生成することになる。
Preprocessorは、openpose、openpose_face、openpose_faceonly、openpose_full、openpose_handを選択可能。順に体だけ、顔+体、顔だけ、顔+体+手、体+手。出したい絵柄によって選択する。
 |  |
 |  |
元画像
ControlNet / OpenPoseの設定
Preprocessorが生成した画像。openpose_handなので体と手だけで顔の部分は含まれない
生成した画像(Promptで場所をCafeからOfficeへ)
特徴としては背景情報が無く人以外は全く違う構図になること。太め細めなど体型も自由。faceが含まれると顔は似てしまうが、openposeとopenpose_handは含まれないので全くの別人が可能。加えてopenpose_handは苦手な指の情報が含まれ、ある程度指問題を解決できる。
ただしポーズは、直立はまだいいが、座りなどはCannyやDepthほど同じにはならず大雑把となる。
+αはDeep Shrink Hires.fixを使ってSDXLでいきなり1,280x1,920!
生成AI画像でLoRAなどの学習用定番ソフトウェアと言えば本連載でもご紹介したsd-scriptsがデファクトスタンダードだ。その作者であるkohya氏が最近面白いものを発表した。その名はDeep Shrink Hires.fix。
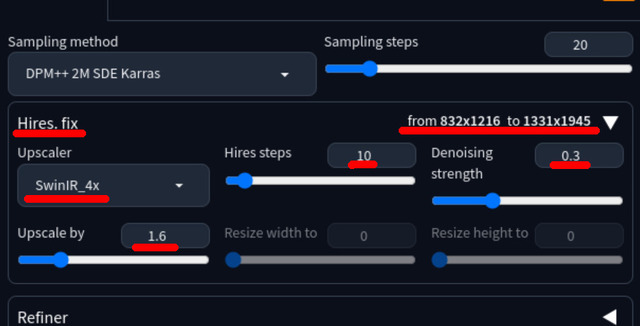
何をするものか簡単に解説すると、SDXLを使って例えば1,280x1,920の画像を作りたい時、いきなりこの解像度を指定すると、体が長かったり顔が複数あったりオカルト的な絵になるので、一旦推奨値の832x1,216で作り、それをUpscale 1.6xする(1,331x1,945と少し大きいが)。これで無事、希望のフルHD相当の画像を得ることが出来る。
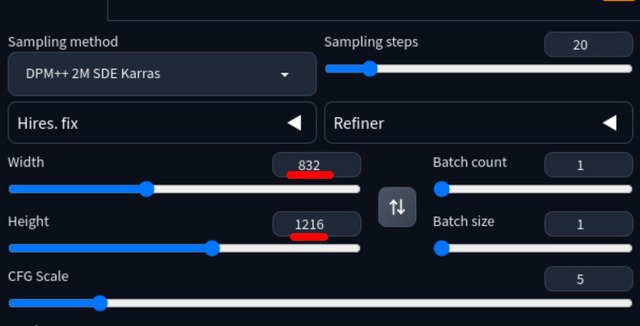 |  |
まず832x1,216で作る
それを1.6x Upscale
ただUpscaleなので単純な拡大よりは画質はいいのだが、あくまでも高度な水増し。この時指定するUpscalerやDenoising strength値によってもかかる時間や結果が変わり、下手すると顔まで変わってしまうので結構気を使ったりする。
これをいきなり1,280x1,920で生成出来るのがDeep Shrink Hires.fixとなる。氏の説明によると
アイデアは極めて単純で、「構図を決めるのはノイズに近いtimesteps」「構図を決めるのはU-Netの深い部分」らしいことが分かっていますので、その部分のlatentsを縮小してあげるだけです。
ということ。ロジックのコードを公開したところ、直にComfyUI / custom_nodes版が、そして数日後にAUTOMATIC1111 Extension版が有志によって公開された。いくつかパラメータがあるのだが、とりあえずデフォルトのままでいい(筆者も使いこなせていない)。
 | 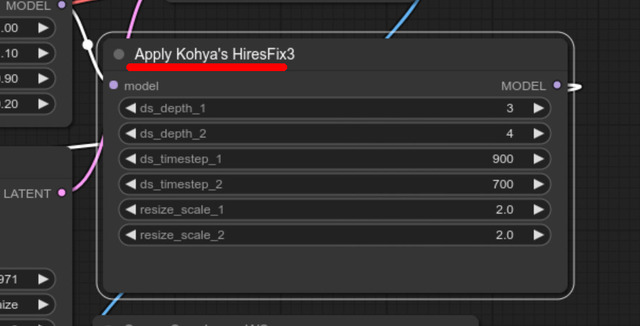 |
AUTOMATIC1111 Extension / sd-webui-kohya-hiresfix
ComfyUI / custom_nodes(一部)
 |  |
無し(1)だとオカルト的な絵になるが、あり(2)だと普通の絵になるのが分かる。またCPUで処理するUpscalerに対し、ほぼGPUで処理するため速い。加えて水増しではなくリアルにその解像度に見合ったデータ量となるため、肌や絵柄などの質感が向上する。といいことずくしだ。
ただ欠点もあるにはあって、
いきなり1,280x1,920で作るため、何枚か出していいのだけセレクト、Upscaleする的な流れにならない=832x1,216で作るより結果時間がかかるケースも
万能では無く、率は低いものの妙な絵が出ることがある(パラメータ調整で直る時も直らない時も)
と言う感じだ。しかしメリットがデメリットを上回っていることもあり、筆者は最近これをONにしたまま生成している。AUTOMATIC1111 Extension版は簡単にインストールできるので是非試して欲しい。
今回の締めのグラビア
今回は上記したlaksjdjf/kohya_hiresfix.py(ComfyUI / custom_nodes版)を使ってのグラビアとなる。また何時もとテイストを変えるため扉の写真も含め衣装などのPromptは Coffee2hai氏のこれをお借りし少し修正して使っている。
正にSDXLの本領発揮!そのままファッション誌?に載せても分からないのでは!?といった絵となった。

加えてまだ説明していない生成高速化技術のLCM(Latent Consistency Model) LoRAを併用すると、SDXL 1,280x1,920の画像をたった2.99秒で生成出来る。RTX 4090でこの速度なので、RTX 3060辺り(4~5倍時間がかかる)だと15秒前後だろうか。
これだけ速ければ欲しい画像も直ぐ作れるよね!と思うだろうが、人間とは欲深いもので、もっといいのが出るのでは!?と更にガチャって数百枚を浪費する(笑)。まぁ遅くてストレスよりは前向きなのでずっといいのだが…。
次回はControlNetの2回目、Reference、Revision、IP-Adapterを取り上げる予定だ。
生成AIグラビアをグラビアカメラマンが作るとどうなる?連載記事一覧