




1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第14回目は、3Dモデル生成のための高速化手法、画像を含むネット記事を量産できる生成AIなど、5つの論文をまとめました。
生成AI論文ピックアップ
OpenAI「CLIP」を真似て超えた、文章と画像を理解するオープンな手法「MetaCLIP」 Meta含む研究者らが開発
ネット記事を量産する生成AI「InternLM-XComposer」 一文入力だけで画像とテキストが混じった記事を自動生成
画像1枚から高速で3Dモデルを生成「DreamGaussian」 バイドゥ含む研究者らが開発
3Dコンテンツを生成する最新技術の多くは、Score Distillation Sampling(SDS)を使用していますが、生成速度が遅いという課題があります。
この研究では、品質を維持しながら、これまでよりも速く最適化して3Dコンテンツを生成するフレームワーク「DreamGaussian」を提案します。DreamGaussianを利用することで、画像やテキストを入力すると、わずか数分で高品質の3Dメッシュを作り出すことができます。
このフレームワークは「3D Gaussian Splatting」という技術を採用し、効率的かつ高精度な3D生成を実現します。この手法は、3Dオブジェクトやシーンを「3D Gaussians」という点の集合として表現するアプローチです。
各3D Gaussianは、透明度や色、中心位置、拡大率などの属性を持っています。これらの情報を使って、3Dの点を2Dの画像上に投影し、それを画像として描画します。3D Gaussiansの最適化の際には、SDSを活用しています。
さらに、3D形状のメッシュとその表面のテクスチャを同時に調整するための新しいアルゴリズムを導入しています。このテクスチャは、UV空間での調整フェーズを経て、微分可能なレンダリング手法によって微調整され、最終的な出力として利用されます。
このフレームワークの採用により、従来の手法に比べて10倍速く、高品質な3D画像を生成することが実現しました。具体的には、画像を3Dモデルに変換する過程が、約2分で完成するという定量結果が得られました。

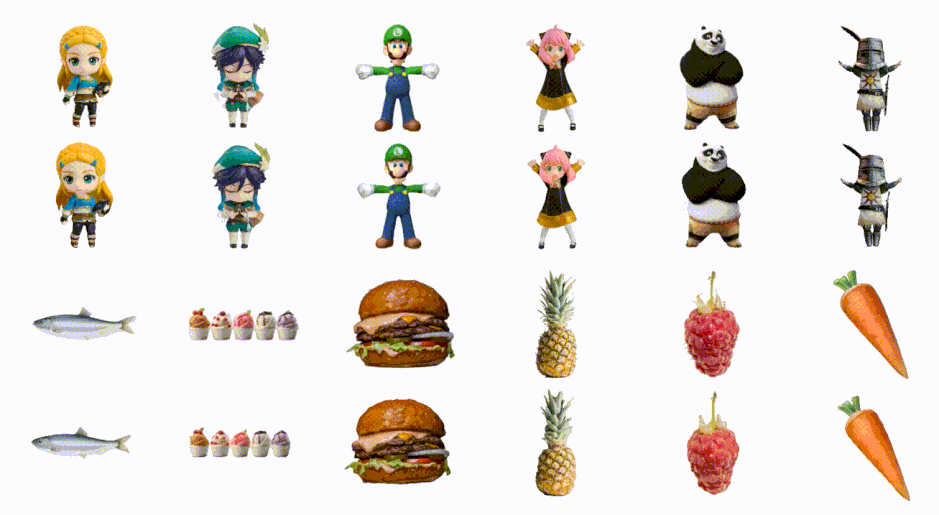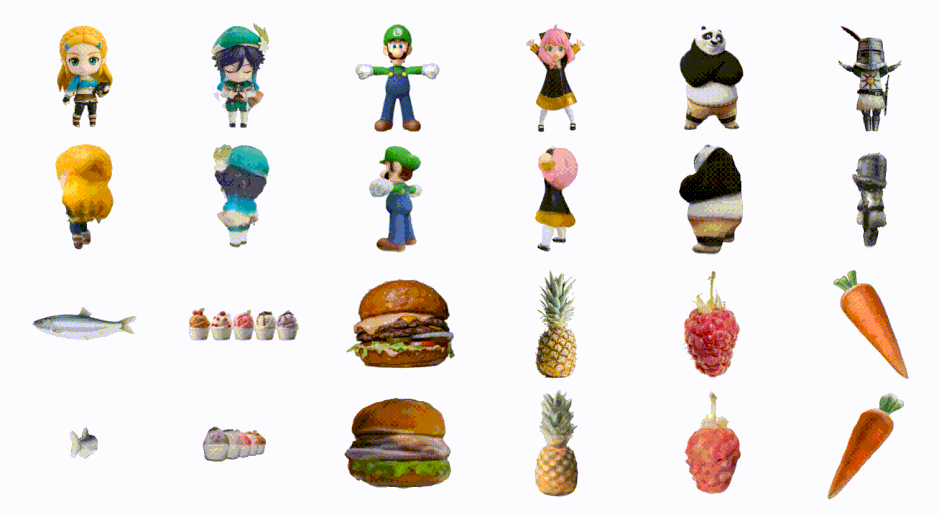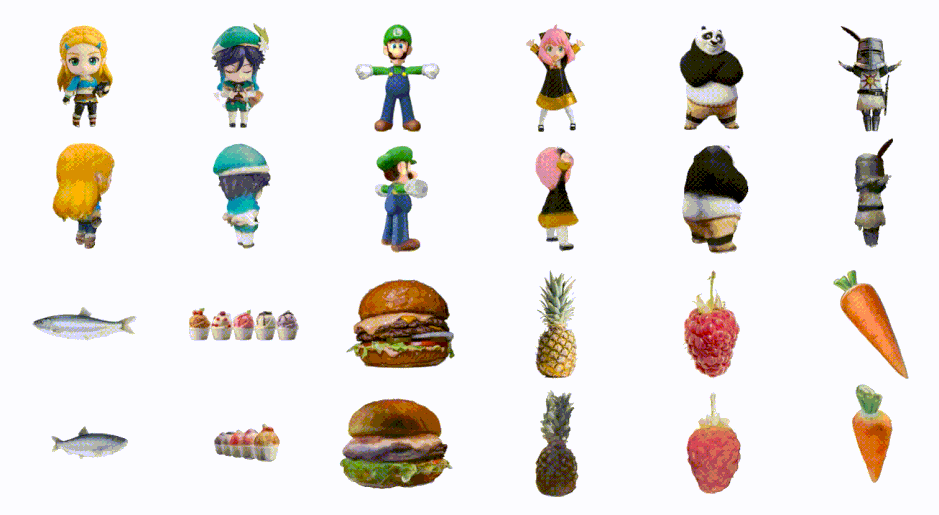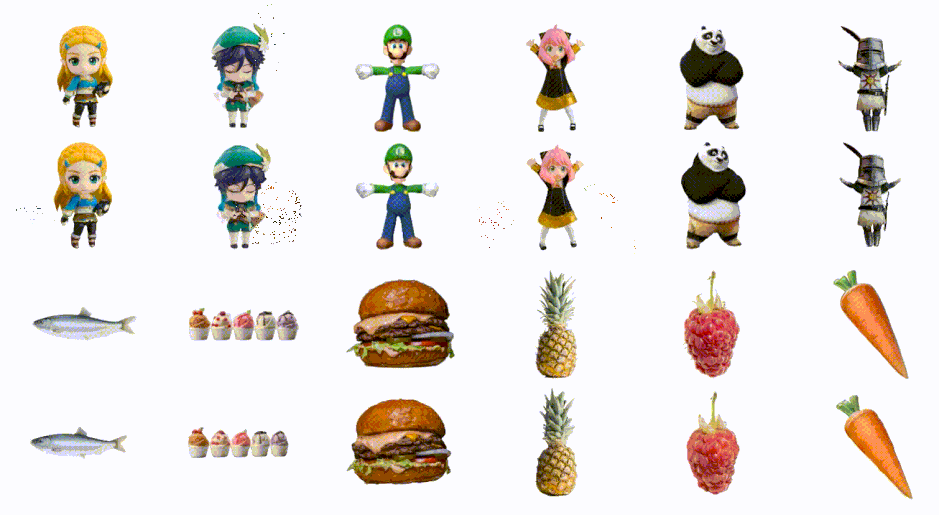

DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, Gang Zeng
Project Page | Paper | GitHub
OpenAI「CLIP」を真似て超えた、文章と画像を理解するオープンな手法「MetaCLIP」 Meta含む研究者らが開発
テキストと画像を扱う領域では、2021年にOpenAIによって公開された「CLIP」(Contrastive Language-Image Pre-training)が主要な方法として多くの分野で使用されています。これは、画像と文章を関連づけて学習する手法です。
CLIPの優れた性能の背後には、インターネットから収集された画像とテキストの4億ペアからなるデータセットがあると考えられています。しかし、CLIPのデータ収集方法の詳細は公開されていません。それを解明し、再現しようとする新しいアプローチ「MetaCLIP」(Metadata-Curated Language-Image Pre-training)が開発されました。
MetaCLIPは、ディープラーニングモデルの学習データを透明に作成・整理する手法であり、画像と文章の関連性をより明確にし、データへのアクセスを容易にすることを目指しています。データ収集では、大量の生データと特定のキーワードや概念(メタデータ)を用いて、関連する画像と文章のペアを選び出し、データの偏りを最小限に抑えています。
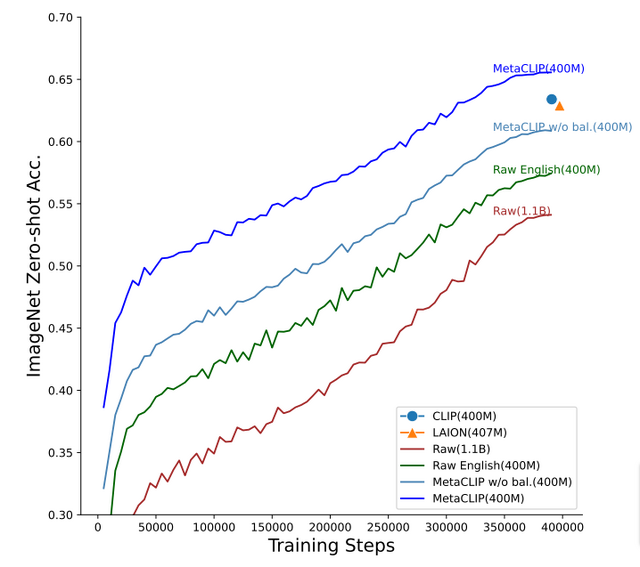
実際のテストにおいて、MetaCLIPを用いたデータでのモデルは、CLIPを用いたものよりも優れた性能を示しました。特に、ゼロショットのImageNet分類では、MetaCLIPは70.8%の正確さを達成し、CLIPの68.3%を上回りました。データ量を増やした場合でも、72.4%の正確さを持ち、さまざまなモデルのサイズで一貫した結果を示しています。ViT-Hモデルでは80.5%の正確さが確認されました。
CLIPのデータ収集方法は公には知られていませんが、MetaCLIPはその方法を公開することで、データの収集・整理がどのように行われているのかを明確にします。
Demystifying CLIP Data
Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer, Christoph Feichtenhofer
Paper | GitHub
ネット記事を量産する生成AI「InternLM-XComposer」 一文入力だけで画像とテキストが混じった記事を自動生成
ChatGPTなどのモデルに見られるように、視覚機能を大規模言語モデル(LLM)の追加入力として取り入れ、視覚-言語タスクを拡張するアプローチが注目されています。さらに、出力としてテキストだけでなく、画像や動画も生成するマルチモーダルなモデルの登場も見られます。
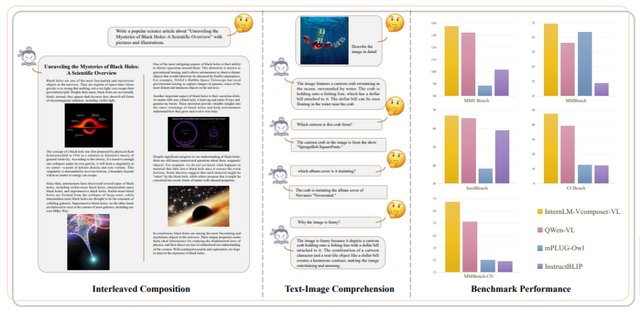
本研究では、テキストと画像の両方を理解し構成する能力を持つ視覚言語大規模モデル「InternLM-XComposer」を提案します。このモデルは、与えられたプロンプトに基づいて、テキストと画像を適切に組み合わせた形式で出力します。
InternLM-XComposerの主な特徴は、コンテキストに関連する画像を挿入しながら長文のコンテンツを生成することです。ユーザーの指示に従って、まずテキストを生成し、次にテキスト中での最適な画像の位置を自動的に識別し、適切な画像説明を生成します。
使用する画像は、画像生成モデルに頼るのではなく、大規模なウェブクロールデータベースから高品質で文脈に合った画像を取得します。また、ユーザーが画像リポジトリをカスタマイズすることも可能です。
InternLM-XComposerは、視覚言語大規模モデルのためのいくつかの主要ベンチマークにおいて、一貫して最先端の結果を達成しました。これには、英語での評価に使用されるMME Benchmark、MMBench、Seed-Bench、そして中国語の評価用のMMBench-CNやCCBenchなどのベンチマークが含まれています。

InternLM-XComposer: A Vision-Language Large Model for Advanced Text-image Comprehension and Composition
Pan Zhang, Xiaoyi Dong, Bin Wang, Yuhang Cao, Chao Xu, Linke Ouyang, Zhiyuan Zhao, Shuangrui Ding, Songyang Zhang, Haodong Duan, Hang Yan, Xinyue Zhang, Wei Li, Jingwen Li, Kai Chen, Conghui He, Xingcheng Zhang, Yu Qiao, Dahua Lin, Jiaqi Wang
Paper | GitHub
テキストから動画を効率よく高品質に生成する新モデル「Show-1」 シンガポールの研究者らが開発
テキストからビデオへの大規模な事前学習済み拡散モデルの開発において、顕著な進展が達成されています。これには、クローズドソースのもの(例:Make-A-Video、Imagen Video、Video LDM、Gen-2)やオープンソースのもの(例:VideoCrafter、ModelScopeT2V)が含まれます。これらのモデルは、ピクセルベースと潜在ベースの2つのタイプに分類できます。
ピクセルベースのモデルは、テキストとの整列が高精度ですが、計算コストが高いという特徴があります。一方、潜在ベースのモデルは、計算コストが低い半面、テキストとの整列が難しいという欠点があります。このように、両者にはそれぞれ利点と欠点が存在します。
これらの方法の利点を活かし、欠点を補うための新しいハイブリッドモデル「Show-1」を紹介します。Show-1は、まずピクセルベースの手法を用いて低解像度のビデオを生成することで、テキストとビデオの整列を確保します。その後、この低解像度のビデオを基にして、潜在ベースの手法を使用し、高解像度のビデオへと変換します。このステップでは、ビデオのクオリティ向上に重点を置いています。
結果として、Show-1は潜在ベースの方法に比べて、正確なテキスト-ビデオ整列を持つ高品質なビデオを生成でき、ピクセルベースの方法に比べてはるかに効率的であることが実証されました。

Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation
David Junhao Zhang, Jay Zhangjie Wu, Jia-Wei Liu, Rui Zhao, Lingmin Ran, Yuchao Gu, Difei Gao, Mike Zheng Shou
Project Page | Paper | GitHub
オープンな中国製生成AI「QWEN」登場 対話、コード、数学、画像の特化モデルもあり アリババの研究者らが開発
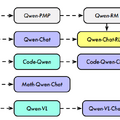
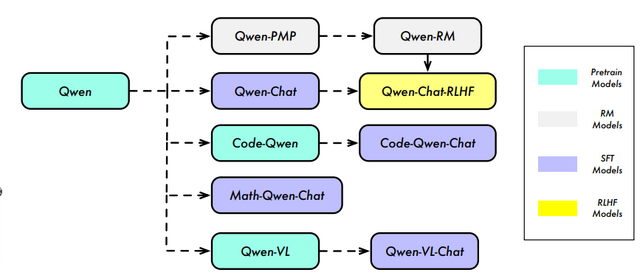
最新の大規模言語モデル「QWEN」が発表されました。この名前は中国語の「Qianwen」から取られています。QWENは、異なるパラメータ数を持つ複数のモデルから構成されるシリーズで、その中にはコーディングや数学に特化したモデルも含まれています。詳細は以下の通りです。
QWENのベースモデルは、多岐にわたるテキストやコード、合計で最大3兆トークンを使用してトレーニングされています。これらのモデルは、多くのタスクにおいて一貫して高い性能を発揮しています。
QWEN-CHATモデルは、チャットやエージェントなどに関連するデータセットで微調整されています。人間のフィードバックを基にした強化学習「RLHF」を使用して訓練されたQWEN-CHATモデルは非常に競争力がありますが、ベンチマークではGPT-4には及びません。
さらに、コードの生成やデバッグに関連する会話を扱うための特化モデル、CODE-QWENを紹介します。CODE-QWENは、コードの理解と生成において高い能力を持っています。
MATH-QWEN-CHATは、数学的問題を解決するためのモデルです。このモデルは、同サイズの他のオープンソースモデルを大幅に上回る性能を持っています。さらに、視覚と言語の指示を組み合わせて理解する能力を有するQWEN-VLおよびQWEN-VL-CHATもオープンソースとして公開されています。
Qwen Technical Report
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, Tianhang Zhu
Paper