

2026年6月8日、WWDC26の基調講演後、AppleのMachine Learning Researchに「Introducing the Third Generation of Apple's Foundation Models」という記事がひっそりと公開されました。
WWDC26の基調講演はティム・クックCEOの最後の花道といった感じで、AI関係でもすごい発表があるかもと期待されていた割にはしょぼんな内容で、Apple Intelligence発表からの2年、いったい何をやっていたのかという不満な声が上がっていました。あ、筆者が上げてました。
Platforms State of the Unionという、WWDCでの開発者向けメッセージビデオを見ればもっと詳細な内容が出てくるかと思ったら、そこでも特筆すべきところは見当たらず。
個別のセッションを見ていたところ、Apple IntelligenceのLLMであるFoundation Modelは大きく変更されていることがわかったので、そこを掘り下げてみようと思ったのです。
現在のFoundation Modelのオンデバイスモデルは機能的、性能的な制限はあるものの、一応は自作エージェンティックAIでも動作します。その軽量さから、筆者はMacBook Neoに組み込むLLMの選択肢として実装してみました。

次の世代に当たる第3世代Apple Foundation Models(AFM)は、Googleと共同でカスタムビルドした5つのモデル群です。
Apple IntelligenceでGoogleと協業することは事前に告知されていたので、ここで「Google」の名前が出てくること自体は、もう驚きではありません。
その協業がどこまで踏み込んでいたかというのが気になっていたポイントだったのですが、学習はGoogleのTPU、最上位モデルはGoogle CloudのNVIDIA GPUの上で動く——という仕組みが判明。
まあそれは現実的に考えたらそうだよね、というところなのですが、個人的に興味をそそられたのが、AFMのオンデバイスモデルの上位版が、「20Bをフラッシュに置く」という新アーキテクチャを採用している点。本稿はこの2点を軸に読み解いていきます。
まず5モデルのラインアップを整理します
混乱しやすいのでFoundation Modelがどのような構成なのかをまとめておきます。今回はオンデバイス2つ、サーバ3つの計5モデル構成です。
オンデバイス側:
AFM 3 Core — 3Bのdenseモデル。前世代の正常進化版で、普段使いの土台部分です。
AFM 3 Core Advanced — 今回の主役。20Bのスパースモデルで、ネイティブマルチモーダル。表現力豊かな音声や高精度ディクテーションを担います。最上位のApple Siliconデバイスでだけ動きます。
サーバ側(すべてPrivate Cloud Compute上で動作):
AFM 3 Cloud — サーバの主戦力。速度と効率重視。
ADM 3 Cloud (Image) — 画像生成・編集用。名前が「AFM」ではなく「ADM」なのに注意。Image PlaygroundやGenmoji、高度な写真編集を動かします。
AFM 3 Cloud Pro — 最上位。エージェント的なツール利用や複雑な推論用です。
問題は、この後の中身です。
主役はAFM 3 Core Advanced、20Bを「DRAMに全部載せない」発想
ローカルLLMをいじっていると、結局すべてはメモリとの戦いになります。Appleもそこに正面から挑んできました。
従来のLLMは、denseだろうがMoEだろうが、全重みをDRAM(アクティブメモリ)に常駐させる必要があります。だから消費者向けハードでは規模に限界がありました。20Bなんて8GB、16GBのデバイスではオンデバイス動作できるわけありません。
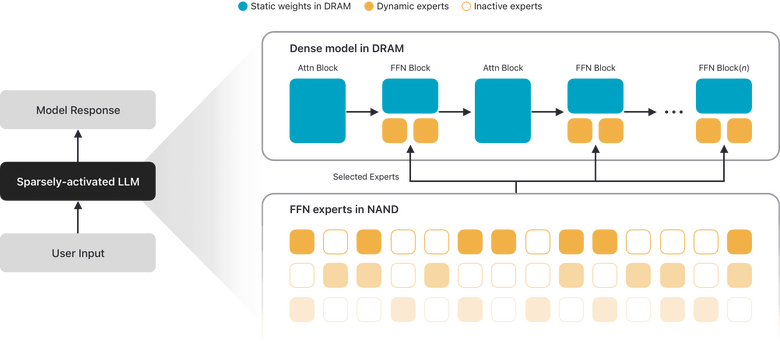
AFM 3 Core Advancedはこの壁を、モデル全体をフラッシュ(NAND)に格納するという発想で突破してきました。土台になっているのはApple自身の研究「Instruction-Following Pruning(IFP)」です。
ただしNAND→DRAMの帯域は遅いので、一般的なMoEのようにトークンごとに重みを入れ替えるのは無理。そこでAFM 3 Core Advancedはプロンプト単位でルーティングを決めます。
軽量なdenseブロックが処理の最初に使うエキスパート群をまとめて選び、生成中に定期的に選び直す。さらにデータ移動を最小化するため、常時アクティブな「shared experts」を高い比率で持ち、入力依存の「routed experts」だけを必要なときDRAMに引き込みます。

要するに、20Bという巨体をフラッシュに寝かせておいて、リクエストごとに1~4Bだけ起こしてDRAMに置くという設計です。しかも難易度に応じてアクティブパラメータ数を変えられる「推論時の弾力性(elasticity)」まで持っています。簡単なリクエストには少なく、重いものには多く。端末内で完結するパイプラインを組んだことがある身からすると、この「使う分だけ起こす」発想はかなり夢があります。
DwarfStarとの不思議な符合
ここで2025年から2026年にかけてのローカルLLMの潮流を振り返っておきたいと思います。いま起きているのは、ひとことで言えば「大きなモデルを、いかに速いメモリに全部載せずに動かすか」という競争です。
筆者もこの流れに乗って、自分のマシンで試し続けてきました。

きっかけは、巨大なのにアクティブパラメータが小さいMoEモデルの台頭でした。2026年4月に出たDeepSeek V4 Flashは、総パラメータ284Bでありながら、1トークンあたり約13Bしか動かしません。2bitクラスの過激な量子化でも品質が驚くほど崩れない。この「総量は巨大だがアクティブな部分は小さい」という性質が、消費者ハードでのフロンティア級推論を一気に現実にしました。
そして、ここでAppleのアーキテクチャと並べたくなるのがDwarfStar(ds4)です。Redisの作者として知られるantirez(Salvatore Sanfilippo)が2026年5月に公開した、DeepSeek V4 Flash専用のC+Metal製推論エンジン。
「汎用GGUFランナーではない、意図的に狭く作る」と宣言し、1モデル・Apple silicon特化で書き切ったプロジェクトです。M3 Max・128GBのMacBook Proで約26 t/s、消費電力ピークは約50Wと、ノートPCの通常負荷と変わらない。半年前ならデータセンターGPUが必要だった仕事を、ラップトップMacがこなすわけです。
筆者も128GBのUnified Memoryを搭載したM4 Max MacBook Proに組み込んでみました。
注目したいのは、DwarfStarが持つ「SSD streaming capacity mode」です。モデルがメモリに収まらないとき、非ルーテッドの重みは常駐させたまま、ルーテッドなMoEエキスパートだけをメモリキャッシュに持ち、キャッシュミス時にGGUF(=SSD)から読み込むという挙動をします。
これは、AFM 3 Core Advancedの「shared expertsは常駐、routed expertsは必要時だけDRAMへ」と、ほぼ同じ思想ですよね。
フラッシュ/SSDを一級市民として扱い、巨大なルーテッド重みだけを必要に応じて高速ストレージから引っ張る。Appleの「LLM in a flash」系研究の延長線と、オープンソース側の実装が、別々の出発点から同じ結論にたどり着いている。これはかなり象徴的な符合だと思います。
違いももちろんあります。Appleは電話というメモリの厳しい環境向けに、専用のスパースアーキテクチャ+IFP+Quantization Aware Trainingで「20Bを1~4B活性・プロンプト単位ルーティング」に仕立てた。一方DwarfStarは、高メモリのMacやDGX Spark向けに、過激な量子化とSSD streaming、さらには分散推論(2bit Flashを64GBマシン2台で、といった構成)で押し切る。狙うハード階層は逆ですが、戦っている敵——メモリ帯域と容量の壁——は同じです。彼の反応がどういうものになるのか、楽しみです。
学習はTPU、Cloud ProはGoogle CloudのNVIDIA GPUの上で動きます
協業すること自体は予告どおりでも、その踏み込み方には驚かされます。今回のモデル群は最新世代のクラウドTPUアクセラレータでプリトレーニングをスケールさせたと明記されています。Appleのモデルが、Googleのシリコンで学習されている。
さらにAFM 3 Cloud Proは、AppleがGoogle・NVIDIAと組んで、Private Cloud ComputeをGoogle Cloud上のNVIDIA GPUまで拡張して動かしているといいます。しかもPCCのプライバシー保証(ユーザーデータは誰にも——Appleにすら——保存・共有されない)はそのまま維持する、と。詳細はAppleのSecurity Research側に出ています。もともとは独自仕様のApple Siliconサーバで動くものだったはず。
「Googleと共同」の中身については、WWDC後のメディア取材でAppleのクレイグ・フェデリギSVPらが補足しています。
報道によれば、AppleはGoogleから大規模なGemini系モデルをライセンスし、それを蒸留に使った。ただしオンデバイスのCore/Core Advancedは完全にApple製で、Cloud系もApple自身が事前学習・事後学習・RLをやり直しており、ユーザーがGoogleのコードやGeminiエージェント、Google検索に直接アクセスすることはない、という説明です。「Geminiを使っただけ」批判に先回りした感じです。Appleが「自前で完結」という従来の建前を、柔軟に運用し始めたのは事実です。
残りのAFM 3 Core / Core Advanced / Cloud、それにADM 3 CloudはちゃんとApple Silicon向けに最適化されているので、線引きとしては「最重量級のCloud ProだけNVIDIA」ということになります。最後はQuantization Aware Trainingで圧縮して精度を保つ、ともしています。
評価値はどう見るか(自己申告であることは念頭に)
ベンチマークはすべてApple自身の人手評価なので、数字は割り引いて読むのが前提です。それでも世代間の伸びは素直に大きい。
AFM 3 Core(テキスト): 好まれた割合が45.6%、2025年baselineは23.3%。
AFM 3 Core(画像理解): どちらか選ばれたケースで前世代より61%超で好まれた。
AFM 3 Cloud(テキスト): 64.7%対8.7%という大差。満足度で約36%、指示追従で21%の相対改善。
AFM 3 Cloud(画像理解): 37.8%対9.6%。
AFM 3 Cloud Pro: Cloud比でテキスト約10%、画像理解14%の上乗せ。Mathでは14%改善。
サーバモデルの64.7%対8.7%はさすがに開きすぎな気もしますが、画像理解を全モデルで押し出してきているあたり、今回のテーマがマルチモーダルなのは伝わります。
Developer Betaが公開されているので試すことは可能ですが、記事にすることは残念ながらできません。そこはできる方は自分のマシンのターミナルでお試しください。
足切りが厳しすぎ、画像生成はローカルを捨てた
ここまで持ち上げておいてなんですが、手放しでは喜べません。今回のCloseBox的な「残念ポイント」は2つあります。
ひとつは、AFM 3 Core Advancedの足切りラインがかなり厳しいこと。恩恵を受けられるのは、
iPhone: iPhone AirとiPhone 17 Proのみ(A18 Pro SoCで12GBメモリ搭載)
M4搭載iPad以上
Mac: M3以上、かつメモリ12GB以上(実質的に16GBモデル以上)
という、ごく狭い範囲です。
第2世代の改良モデルである3BのCoreは広く行き渡るでしょうが、20Bマルチモーダルの本領を味わえる人は少ない。フラッシュ常駐という設計はエレガントなぶん、結局それを支える速いNAND帯域と十分なDRAM、要するに「最新の速いストレージとメモリ」が前提になり、そのままハードの足切りに直結しているわけです。エレガントさの代償はユーザーが買い替えで払う構図、とも言えます。
もうひとつ。画像生成はローカルを完全に諦めました。ADM 3 Cloudはその名のとおりサーバ専用で、Image PlaygroundもGenmojiも、写真のSpatial Reframingも、全部PCC送りになります。前世代まで一部オンデバイスで動いていた軽い画像生成も含めて、画像はまるごとクラウドに一本化された格好です。PCCでプライバシーは守る建前とはいえ、オフラインでは完結しないし、「端末内でその場に絵が立ち上がる」あの感触は失われます。オンデバイス推しとしては、ここはかなり寂しい後退だと思います。
せっかくフォトリアリスティックな画像生成ができるといってもクラウドで行うというのだったらNano Banana、ChatGPT Image、Grok Imagineとかを使った方がいい画像が出るはずですし。
ターミナルから叩く——macOS 27のfmコマンドとPython SDK
このあたりを実際に手で確かめる道も、今回ちゃんと用意されています。WWDC26のセッション「fm CLIとPython SDKによるAI活用型スクリプトの作成」(セッション334)で詳しく語られているのですが、macOS 27にはオンデバイスのFoundation Modelをターミナルから叩くfmコマンド(fm CLI)が標準でプリインストールされました。これまではSwiftでアプリを書くか有志のラッパーを入れるしかなかったので、素のシェルからモデルに話しかけられるのは大きな変化です。
筆者はGitHubに公開されているチャットソフトを参考に、Claude CodeにFoundation Modelブラウザチャットアプリを作らせていましたから、とても便利になります。
使い方はシンプルです。fm chatで対話セッションを開き、オンデバイスとPrivate Cloud Computeのモデルを切り替えたり、セッションを保存して後で再開したり。スクリプト向けにはfm respond "プロンプト"で一発返答を標準出力に流せます。

Python派にはpip install apple_fm_sdkで入るFoundation Models SDK for Pythonも用意されました(Python 3.10以上・Xcode・Apple silicon前提)。Swiftフレームワークと同じく、テキスト・画像入力、ストリーミング、ツール呼び出し、ガイド付き生成(@fm.generable/fm.guide)に対応します。
セッションでは、オンデバイスモデルで生成した出力をサーバの「ジャッジモデル」に採点させ(余分な項目・欠落・ハルシネーションを評価)、Jupyter+Pandas+matplotlibで可視化してプロンプトを改善する評価パイプラインまで見せていました。ローカルでLLMの評価ループを回す身としては、これは普通に実務で使えます。
とはいえ、その先で実際に各モデルを動かすには、そのモデルに対応したマシンが必要。前章のとおり、AFM 3 Core Advancedの本領を出すにはiPhone AirかiPhone 17 Pro、あるいはM3以上・16GB以上のMacが前提。Python SDKもApple Silicon前提です。コマンドが標準で入っていても、対応機がなければ「動きません」と丁寧に断られて終わりです。
つまり、対応マシンを持っていない人は、これから買い揃えることになります。そしてここが地味に効いてくる現実なのですが——その「これから揃えることになるマシン」が、我が愛機MacBook Neoでないことだけは、確実です。
筆者はM4 Max MacBook Pro、M4 Mac mini、iPhone Airの3つがAFM 3 Core Advancedを体験できるデバイスということになります。
アプリデベロッパーにとっては、Coreだけでいくか、Core Advancedだけをターゲットにするか、難しい選択を迫られることになりそうです。
なお、PixelをはじめとするAndroidスマートフォンでは、Gemini NanoをオンデバイスLLMとして搭載していますが、そのパラメータ数は3.25Bと、Foundation ModelのCoreモデルと同クラス。20BクラスのGemini Nanoは存在してないし、それはNanoとは呼ばないでしょう。
つまり、スマートフォン用のオンデバイスAIとしては、メモリ12GBであってもiPhone Airに搭載されたCore Advancedが最強である可能性は高いと言えます。
(出典: Apple Machine Learning Research「Introducing the Third Generation of Apple's Foundation Models」2026年6月8日、WWDC26セッション334「fm CLIとPython SDKによるAI活用型スクリプトの作成」、WWDC 2026後のAppleInsider・Max Weinbach氏らによる報道、およびantirez/DwarfStar関連の公開情報をもとに、Claude Codeで執筆し、筆者が修正・加筆しました)