






この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第144回)は、元の写真にピクセル単位で忠実な3Dモデルを生成するAIモデル「Pixal3D」や、Nano Banana 2.0に匹敵という80億パラメータの画像生成AI「HiDream-O1-Image」を取り上げます。
また、スマホ上で動く軽量マルチモーダルLLM「MiniCPM-V 4.6」や、完全ローカル・CPUで動く日本語対応の軽量TTSモデル「Supertonic 3」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、アニメやイラストの生成に特化した20億パラメータを持つローカル画像生成AIモデル「Anima」を別の単体記事で取り上げています。

元の写真にピクセル単位で忠実な3Dモデルを生成するAIモデル「Pixal3D」
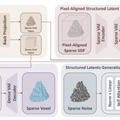
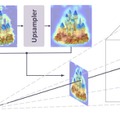
1枚の写真から3Dモデルを生成するAI技術は進歩していますが、元の画像にピクセル単位で正確に一致する忠実度を保つことはまだまだ課題です。
従来の技術は、一度AIが扱いやすい標準的な3D空間を用意し、そこに画像情報をざっくりと当てはめていく方式だったため、どうしても元の平面画像と立体の対応が曖昧になり、細かいディテールが失われがちでした。
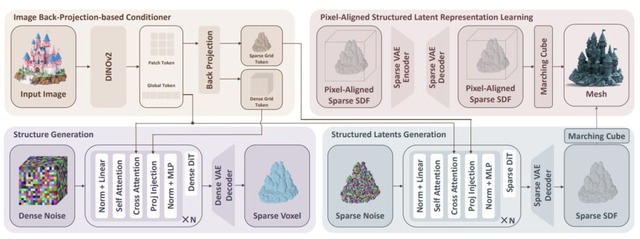
この問題を解決するために、研究チームは「Pixal3D」という新しい生成手法を開発しました。この技術は、入力された画像のカメラ視点にぴったり合わせた状態で、直接3Dモデルを生成します。
具体的には、画像から抽出した特徴量をカメラから伸びる線に沿って3D空間へ投影し、画像のどのピクセルが3D空間のどの位置に対応するかをあらかじめ確定させた上でAIに渡します。これによりAIが対応関係を探す手間がなくなり、忠実に再現できるようになりました。



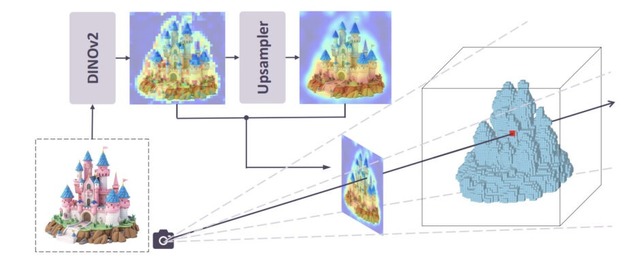
Pixal3D: Pixel-Aligned 3D Generation from Images
Dong-Yang Li, Wang Zhao, Yuxin Chen, Wenbo Hu, Meng-Hao Guo, Fang-Lue Zhang, Ying Shan, Shi-Min Hu
Project | Paper | GitHub
スマートフォン上で動く軽量マルチモーダルLLM「MiniCPM-V 4.6」、画像・動画理解に対応
MiniCPM-V 4.6は、スマートフォンなどのエッジデバイス上で画像や動画を理解するために設計された、軽量マルチモーダル大規模言語モデル(MLLM)です。SigLIP2-400MとQwen3.5-0.8Bをベースに構築されています。
総パラメータ数は13億とコンパクトでありながら、Gemma4-E2B-itのようなより規模の大きなモデルを上回る性能を発揮し、様々なベンチマークテストで高い水準の視覚・言語理解能力を示しています。
このモデルは、LLaVA-UHD v4で採用された圧縮技術を導入したことで、視覚情報のエンコーディングにかかる計算コストを50%以上削減することに成功しました。
さらに、4倍と16倍の視覚トークン圧縮率を混在させる機能により、タスクの要件に合わせて精度と処理速度のバランスを調整できます。その結果、Qwen3.5-0.8Bと比較しても、約1.5倍のトークン処理能力を実現しています。
MiniCPM-V 4.6は、iOS、Android、HarmonyOSといったモバイルOSをサポートしています。
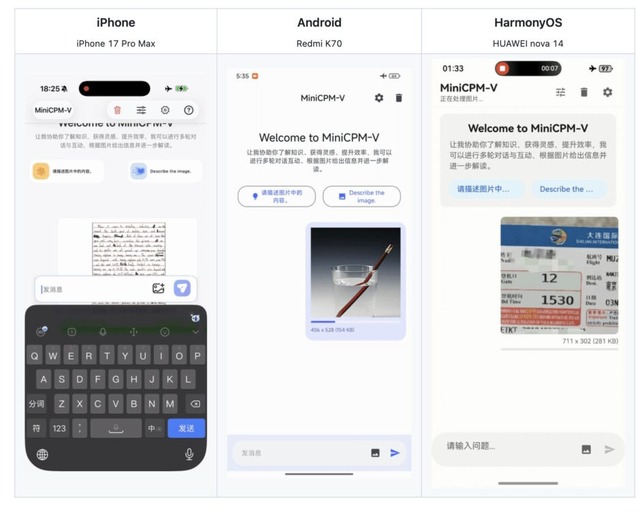
MiniCPM-V 4.6
GitHub | Hugging Face
Nano Banana 2.0に匹敵という80億パラメータの新しい画像生成AI「HiDream-O1-Image」
HiDream.aiが発表した「HiDream-O1-Image」は、テキストと画像の処理を一体化させた画像生成AIです。文字、画像のピクセル、タスクの指示、これら全部を同じトークンに変換して、一つのTransformerで処理します。
従来のように、言葉を理解する部分と画像を作る部分が分かれていないため、途中で情報が劣化せず、ユーザーの細かな意図をダイレクトに画像へ反映できます。
さらに、複雑な指示をAI自身が論理的に解釈して整理する機能も搭載しています。これにより、画像内に指定した文字を正確に書き込んだり、特定の人物や商品の見た目を維持したまま別の背景で描いたり、自然な画像編集やコマ割りの生成などを、一つのシステムで高精度にこなすことができます。
モデルの効率も高く、80億パラメータ版では、同社の評価によれば270億パラメータのQwen-ImageやGoogleのNano Banana 2.0に匹敵、または上回る性能を出しています。同時に、大規模バージョンの2,000億パラメータ以上も開発されています。



HiDream-O1-Image: A Natively Unified Image Generative Foundation Model with Pixel-level Unified Transformer
HiDream.ai
Paper | GitHub | Hugging Face
完全ローカル・CPUで動く日本語対応の軽量TTSモデル「Supertonic 3」
Supertoneが、ローカル環境で動作する軽量な音声合成(TTS)モデルの最新版「Supertonic 3」を公開しました。このモデルはAPI通信やクラウドに接続することなくデバイス上で直接音声を生成できます。
今回のアップデートにより、対応言語が前バージョンの5言語から日本語を含む31言語へと大幅に拡大されました。また、読み上げ時の不自然な繰り返しやスキップといったエラーが減少し、テキスト読み上げの安定性が向上しています。
さらに、「笑い」や「ため息」などの表現タグが新たにサポートされ、より人間らしく豊かな音声合成が可能になりました。
モデルのパラメータ数は約9,900万と、他の大規模なオープンソースTTSモデルと比較してコンパクトに設計されています。そのため、GPUを必要とせずCPU上でも動作し、ブラウザやエッジデバイスでも動きます。
今回のアップデートにより、対応言語が前バージョンの5言語から日本語を含む31言語へと大幅に拡大されました。また、読み上げ時の不自然な繰り返しやスキップといったエラーが減少し、テキスト読み上げの安定性が向上しています。
さらに、「笑い」や「ため息」などの感情表現タグが新たにサポートされ、より人間らしく豊かな音声合成が可能になりました。
モデルのパラメータ数は約9,900万と、他の大規模なオープンソースTTSモデルと比較してコンパクトに設計されています。そのため、高価なGPUを必要とせずCPU上でも動作し、ブラウザやスマートフォン、Raspberry Piのようなエッジデバイスでも動く手軽さです。

Supertonic 3
Supertone
GitHub | Hugging Face









![イヤホン 有線 [HIFI音質]イヤホン 有線 3.5mmジャック ノイズ低減 通話/音楽 音量調節対応 防水 通勤・会議・運動 | 原音再現 MFi認証 重低音 遅延なし コンパクト 軽量 インイヤー 人体工学 image](https://m.media-amazon.com/images/I/31CBe3mkz-L._SL160_.jpg)






