



この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第96回)では、参照音声だけで音声合成を生成できるTTSモデル「MiniMax-Speech」、自らアルゴリズムを発見して進化させ続けるAI「AlphaEvolve」を取り上げます。
また、写真内の照明を調整できる拡散モデル「LightLab」、画像や動画などを見て理解するByteDance開発のマルチモーダルAIモデル「Seed1.5-VL」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、大規模言語モデルを活用して日本の国会議員のこれまでの発言を分析して政治的立場をまとめた研究を単体記事で取り上げています。

音声の書き起こしテキストを必要とせず、サンプル音声だけで音声合成できるTTSモデル「MiniMax-Speech」
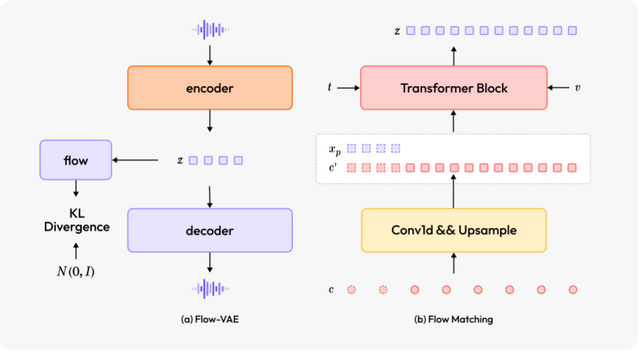
「MiniMax-Speech」は高品質な音声を生成するテキスト音声合成(TTS)モデルです。従来の方法と違い、音声の書き起こしテキストを必要とせず、学習可能なスピーカーエンコーダーによって参照音声から音色特徴を抽出することができます。
これによりMiniMax-Speechは、参照音声を聞くだけで、その話者の声の特徴を捉えて自然な音声をゼロショット方式で生成します。これまでのように、参照音声と参照テキストから高い類似性を持つ合成音声を生成するワンショット音声クローニングもサポートしています。
MiniMax-Speechは32の言語に対応し、さらに「Flow-VAE」という新しい技術により合成音声の全体的な品質が向上しています。
精度評価では、評価プラットフォーム「Artificial Arena」においてMiniMax-Speechが最上位にランクされ、OpenAI、Google、Microsoft、Amazonなどの大手企業のモデルを上回りました。特に音声の明瞭さ(単語誤り率)と話者の声の再現性(話者類似性)において優れた結果を示しています。

MiniMax-Speech: Intrinsic Zero-Shot Text-to-Speech with a Learnable Speaker Encoder
Bowen Zhang, Congchao Guo, Geng Yang, Hang Yu, Haozhe Zhang, Heidi Lei, Jialong Mai, Junjie Yan, Kaiyue Yang, Mingqi Yang, Peikai Huang, Ruiyang Jin, Sitan Jiang, Weihua Cheng, Yawei Li, Yichen Xiao, Yiying Zhou, Yongmao Zhang, Yuan Lu, Yucen He
Project | Paper | GitHub
Google、自らアルゴリズムを発見してコード全体を進化させ続けるAI「AlphaEvolve」
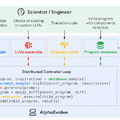
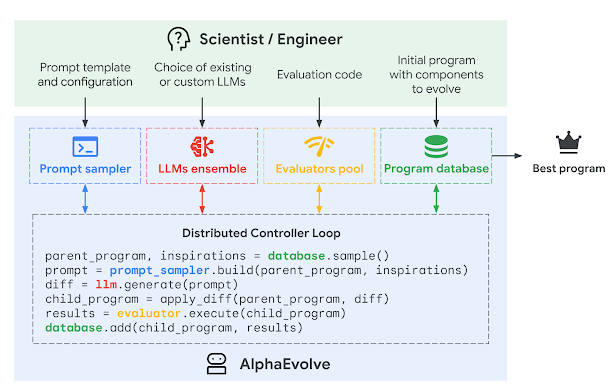
GoogleはAIと進化的アルゴリズムを組み合わせたAIエージェント「AlphaEvolve」を発表しました。これはアルゴリズムを発見してコードを自動的に改良することで、科学的発見や数学の未解決問題解決、実用的な最適化を行う、Geminiモデルを活用した進化型コーディングエージェントシステムです。
AlphaEvolveは大規模言語モデル(LLM)を利用してコードに変更を加え、その効果を評価し、さらに改良を重ねていくという進化的なアプローチを取ります。従来の類似システムと異なり、単一の関数だけでなくコードファイル全体を扱え、どんなプログラミング言語にも対応します。
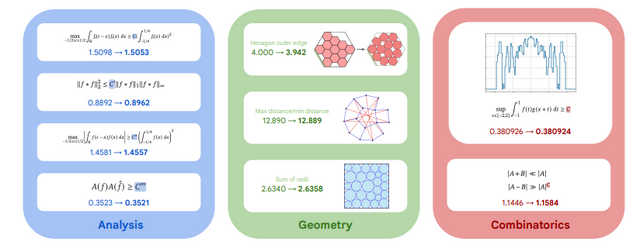
成果として特筆すべきは、56年間改良されていなかった複素行列乗算のアルゴリズムを初めて改良したことです。また数学分野では50以上の未解決問題に取り組み、約75%のケースで最先端の解決策を再発見し、約20%で既存の最良結果を上回る新しい発見をしました。
実用面では、Googleのデータセンターのスケジューリングを最適化し、全体の計算リソースの0.7%を節約したほか、Geminiの訓練時間を1%短縮する成果も出しています。
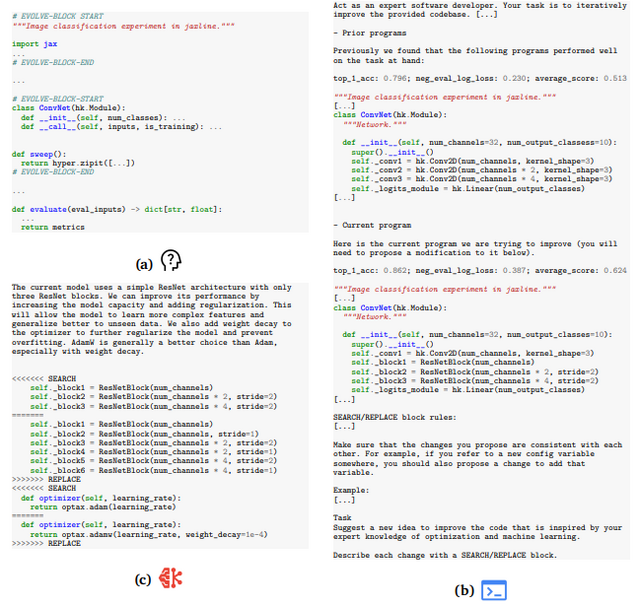

AlphaEvolve: A coding agent for scientific and algorithmic discovery
Google DeepMind Team
Paper | Blog
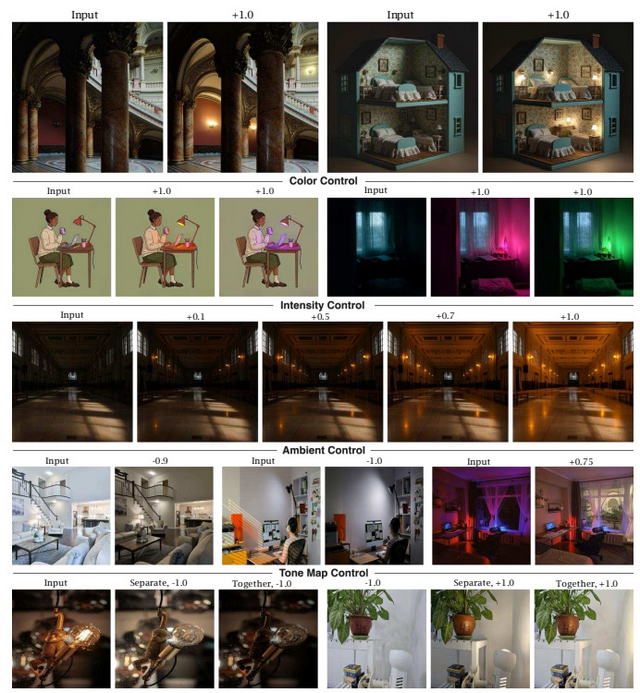
写真内の照明を調整できる拡散モデル「LightLab」をGoogleが開発
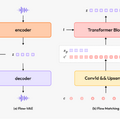
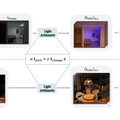
Googleが開発した「LightLab」は、撮影後の写真内の光源を精密に制御できる技術です。この技術では、拡散モデルを活用して1枚の画像内の光源の強度や色を自由に変更することができます。
LightLabの仕組みは、実際の写真ペアと合成レンダリング画像を組み合わせたデータセットで拡散モデルを微調整することにあります。研究チームはまず、600組の実写写真ペア(同じ場面で光源をオン/オフした状態)を撮影しました。さらに、物理ベースのレンダリングを用いて、大量の合成3D室内シーンを生成しています。
合成3D室内シーンでは光源成分と環境光成分を分離し、それらを様々な強度と色で組み合わせることで、多様な照明条件のデータを作成しました。この手法により、トレーニングデータを大幅に拡張することができています。
LightLabの主な機能には、光源の強度変更(明るさの調整)、色温度の変更(暖色から寒色まで)、環境光の調整、そしてトーンマッピング効果のコントロールがあります。これらの機能を組み合わせることで、写真の雰囲気を大きく変えることができます。
応用範囲は広く、室内写真での光源調整はもちろん、屋外シーンの雰囲気変更、複数の連続した編集の適用、イラストなどの非写実的画像の照明編集まで対応しています。さらに、アニメーションフレーム間での一貫した照明の生成も可能です。

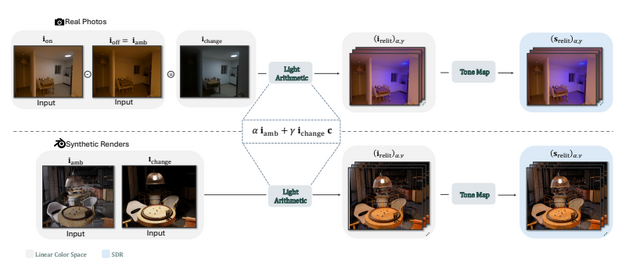
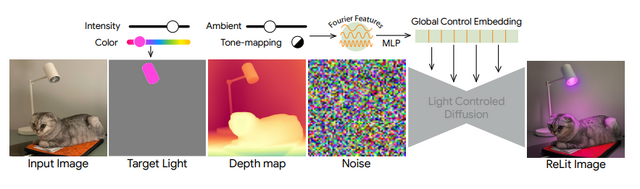


LightLab: Controlling Light Sources in Images with Diffusion Models
Nadav Magar, Amir Hertz, Eric Tabellion, Yael Pritch, Alex Rav-Acha, Ariel Shamir, Yedid Hoshen
Project | Paper
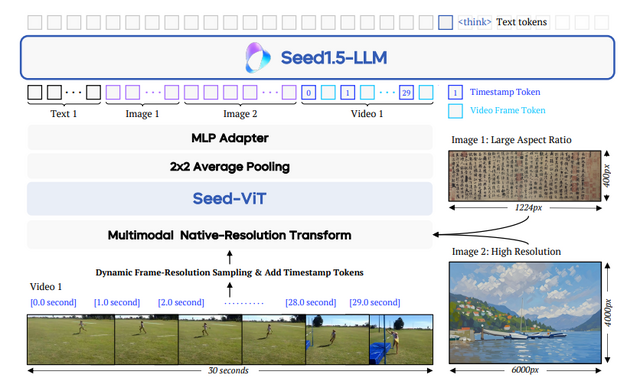
画像や動画、ゲームなどを見て理解するマルチモーダルAIモデル「Seed1.5-VL」をByteDanceが開発
ByteDanceが開発したマルチモーダルAIモデル「Seed1.5-VL」は、画像や動画を見て理解し、それについて対話できる能力を持っています。
このモデルは532Mパラメータの視覚エンコーダと20Bの有効パラメータを持つMixture-of-Experts(MoE)大規模言語モデルで構成されており、比較的コンパクトなアーキテクチャながらも高い性能を発揮しています。
Seed1.5-VLは基本的な視覚的理解にとどまらず、複雑な視覚パズルや高度な推論課題においても良い能力を示しています。評価結果では、60の公開ベンチマークのうち38で最先端の性能を達成しました。特にマルチモーダル推論、文字認識(OCR)、図表理解、画像内の特定物体の位置特定、3D空間理解、そしてビデオ理解といった幅広い分野で優れた結果を残しています。
さらに、GUI操作やゲームプレイなどのエージェント中心のタスクにおいて、Seed1.5-VLはOpenAI CUAやClaude 3.7といったマルチモーダルシステムをも上回る性能を示しています。






![イヤホン 有線 [HIFI音質]イヤホン 有線 3.5mmジャック ノイズ低減 通話/音楽 音量調節対応 防水 通勤・会議・運動 | 原音再現 MFi認証 重低音 遅延なし コンパクト 軽量 インイヤー 人体工学 image](https://m.media-amazon.com/images/I/31CBe3mkz-L._SL160_.jpg)






