







1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第36回目は、生成AI最新論文の概要5つを紹介します。
生成AI論文ピックアップ
透明画像含む複数のレイヤーをテキスト指示で同時に生成するAI「LayerDiffuse」
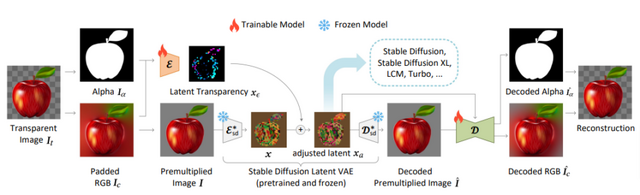
ControlNetを開発した研究者らが、潜在拡散モデルを使用して単一の透明画像や複数の透明レイヤーを生成できる手法「LayerDiffuse」を発表しました。透明度(アルファチャンネル)を含む画像を直接生成でき、複数の透明レイヤーを生成し、それらを組み合わせて複雑な画像を構築することもできます。
また、前景や背景などの特定条件に基づいたレイヤー生成も可能であり、例えば特定の背景に適合する前景オブジェクトの生成やその逆のケースも実現できます。さらに、既存の拡散モデルの品質を保持しながら透明性を追加することも可能です。
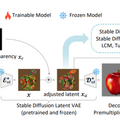
この手法は、「Latent Transparency」という技術を用いて、透明度をモデルの潜在空間にエンコードすることで、元のモデルの潜在分布を大きく変えることなく、透明度を追加し、拡散モデルの高品質を維持します。この方法により、任意の潜在拡散モデル(例えばStable Diffusion)を微調整することで、透明画像生成器に変換できます。
研究チームは100万組の透明画像レイヤーを収集し、このモデルをトレーニングしました。Latent TransparencyはStable Diffusionだけでなく、さまざまなオープンソースの画像生成器に適用可能です。また、ControlNetやLoRAなどの制御モデルとの統合も可能です。
評価実験により、97%でユーザーは既存の対応策(例えば生成後のマット化など)よりも、本手法でネイティブに生成された透明コンテンツを好むことが示されました。また、生成された透明画像の品質がAdobe Stockなどの商用透明アセットと比較しても匹敵することが示されました。






Transparent Image Layer Diffusion using Latent Transparency
Lvmin Zhang, Maneesh Agrawala
Paper | GitHub
1枚の顔写真と音声から、喋って歌う頭部動画を生成するモデル「EMO」、アリババが開発
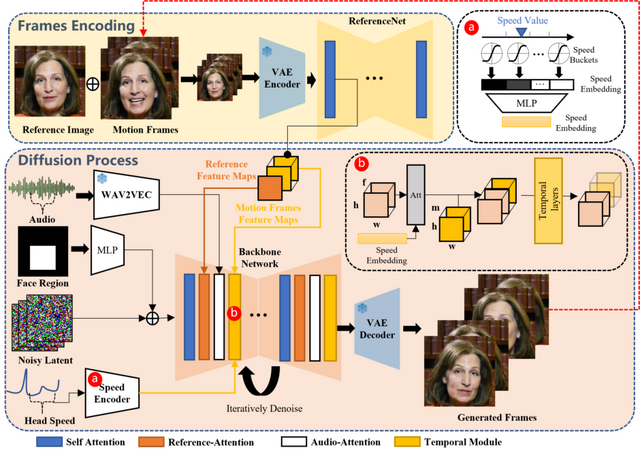
拡散モデルの生成力を活用し、与えられた顔画像1枚と音声クリップから、その音声を話す/歌うキャラクターの頭部ビデオを合成するモデル「EMO」を提案する論文です。音声入力に同期して自然な頭部動作と鮮やかな表情を保つ、高度な一貫性を持っています。
このアプローチではStable Diffusionを使用。中間の3Dモデルや顔のランドマークや複雑な前処理を必要とせずに、自然な頭の動きと声の音調の変化に合わせた生き生きとした表情を維持しながら、連続するビデオフレームをシームレスに生成します。
手法として、参照画像とモーションフレームから特徴を抽出し、これらの特徴を利用して顔の画像を生成する2段階のプロセスを行います。このプロセスには、参照機能とオーディオ機能に注意を払うメカニズムが含まれており、これによりキャラクターのアイデンティティを保持し、キャラクターの動きを調整することができます。また、時間的なモジュールを使用して動きの速度を調整し、生成されたビデオに自然な流れをもたらします。
最終的に、250時間以上の映像と1億5000万以上の画像を含む多様な音声・ビデオデータセットを構築し、このデータセットを使用してモデルを訓練しました。このトレーニング材料は、人間の表情と声のスタイルの広範なスペクトラムを捉えることを保証します。
データセットでの広範な実験と比較を通じて、このアプローチは、FID、SyncNet、F-SIM、FVDなど複数の指標で、現在の最先端技術を上回る結果を達成しました。さらに、包括的なユーザースタディと定性的評価も行い、この方法が非常に自然で表現豊かな話すおよび歌うビデオを生成できることを示しました。

EMO: Emote Portrait Alive – Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
Linrui Tian, Qi Wang, Bang Zhang, Liefeng Bo
Project | Paper | GitHub
大規模言語モデルの計算コストを大幅に軽減する1ビットLLM「BitNet 1.58Bits」をマイクロソフトが開発
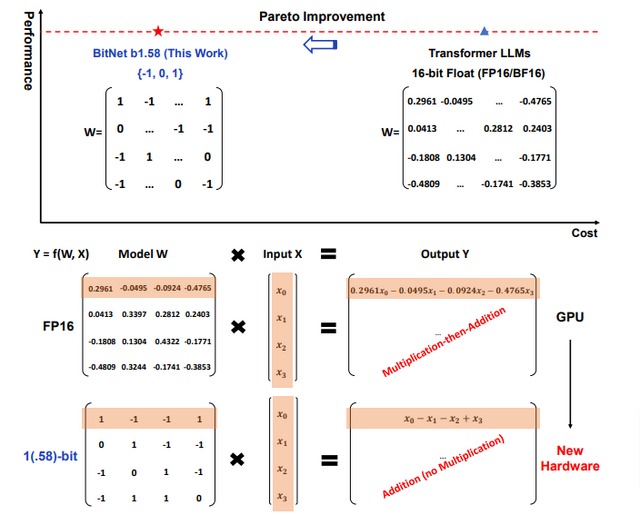
従来の手法では、テキストプロンプトを「0.2403」のような浮動小数点数を用いた行列として数値化し、積和演算を行うことでテキストに変換します。このプロセスは計算コストが高く、高性能な計算資源(例えばGPU)を使用します。
計算コストを削減するための一つのアプローチとして、量子化によりモデルを低ビットで表現する方法があります。これは、数値の桁数を削減することで行列計算のコストを下げるものです。しかし、従来の量子化手法では、計算コストを下げることができるものの、精度が低下することが課題とされてきました。
本研究で提案されている1ビット量子化のアプローチは、各パラメータ(重み)を「-1」「0」「1」の3つの値のみを使用することにより、さらに桁数を減らすシンプルな方法です。この方法で作成したモデル「BitNet b1.58Bits」は、行列乗算を行う層(BitLinear層)に置き換えられており、従来の浮動小数点を使用した加算や乗算を必要とする代わりに、整数加算のみを行います。これにより、計算コストと消費電力を大幅に削減することができます。
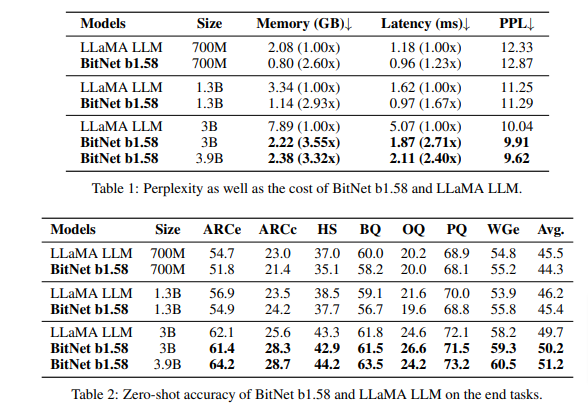
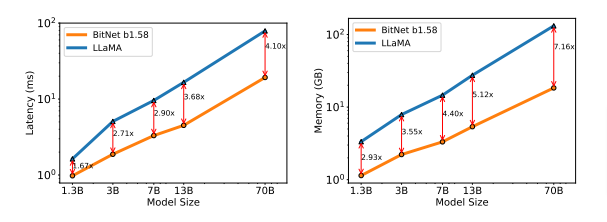
BitNet b1.58を同じモデルサイズとトレーニングトークン数を使用したFP16のモデル(例えばLLaMA)と精度比較した結果、LLaMAと同等かそれをわずかに上回る精度を達成しました。さらに、遅延、メモリ、スループット、およびエネルギー消費という点で、顕著なコスト効率の良さを達成しています。
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, Furu Wei
Paper
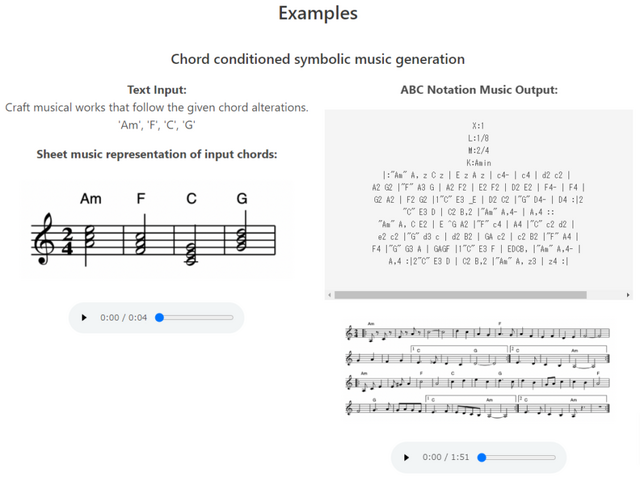
音楽をテキストのように扱い、音楽の理解と生成を行うAI「ChatMusician」
オープンソース大規模言語モデル(LLM)である「ChatMusician」は、音楽をテキストと互換性のあるABC記法(ABC記譜法)で表現し、音楽の理解と生成を行います。このモデルは、テキスト、コード、メロディ、モチーフ、音楽形式などに基づいて、構造的に整った長時間(数秒から数分)の音楽を作曲することができます。
ABC記法とは、音楽を文字と数字で記述できるテキストベースの楽譜表記方法です。アルファベットの文字を使用して音高を表し、数字や記号を使って音価(長さ)、休符、調性、装飾音などを示します。テキストファイルで楽譜を保存し共有できるため、特別なソフトウェアを必要とせずに、楽譜を作成したり、既存の楽譜を編集したりすることができ、電子メールで送ることも可能です。MML(Music Macro Language)としても知られています。
ChatMusicianは、LLaMA2-7B-Baseモデルを基礎として、音楽に関連するデータで追加の事前学習とファインチューニングを行います。これにより、モデルはABC記法に基づく音楽表現において、音楽的な知識と言語的な知識の両方を獲得します。
このモデルは、音楽能力を言語モデルに注入するための特別なデータセット「MusicPile」を使用します。MusicPileは、音楽関連の自然言語データ、YouTubeから収集した200万曲のメタデータ、音楽知識の質問と回答のペアなどを含む多様な情報から構成されています。
研究チームは、ChatMusicianとベースラインとを評価するために音楽理解ベンチマーク「MusicTheoryBench」を作成しました。比較した結果、ChatMusicianは既存のモデル(LLaMA2やGPT-3.5など)を大きく上回り、特に音楽推論ではGPT-4を上回る成績を示しました。音楽生成に関しては、ABC記法を用いた効率的なデータ圧縮と高い音楽性を達成しています。言語能力に関する評価では、ChatMusicianはLLaMA2-7B-Baseモデルよりも高いスコアを獲得し、音楽能力の統合が言語モデルの性能を損なわないことを示しています。


ChatMusician: Understanding and Generating Music Intrinsically with LLM
Ruibin Yuan, Hanfeng Lin, Yi Wang, Zeyue Tian, Shangda Wu, Tianhao Shen, Ge Zhang, Yuhang Wu, Cong Liu, Ziya Zhou, Ziyang Ma, Liumeng Xue, Ziyu Wang, Qin Liu, Tianyu Zheng, Yizhi Li, Yinghao Ma, Yiming Liang, Xiaowei Chi, Ruibo Liu, Zili Wang, Pengfei Li, Jingcheng Wu, Chenghua Lin, Qifeng Liu, Tao Jiang, Wenhao Huang, Wenhu Chen, Emmanouil Benetos, Jie Fu, Gus Xia, Roger Dannenberg, Wei Xue, Shiyin Kang, Yike Guo
Project | Paper
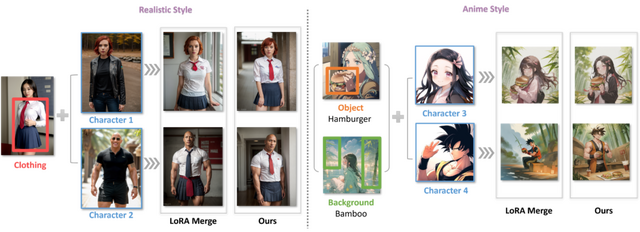
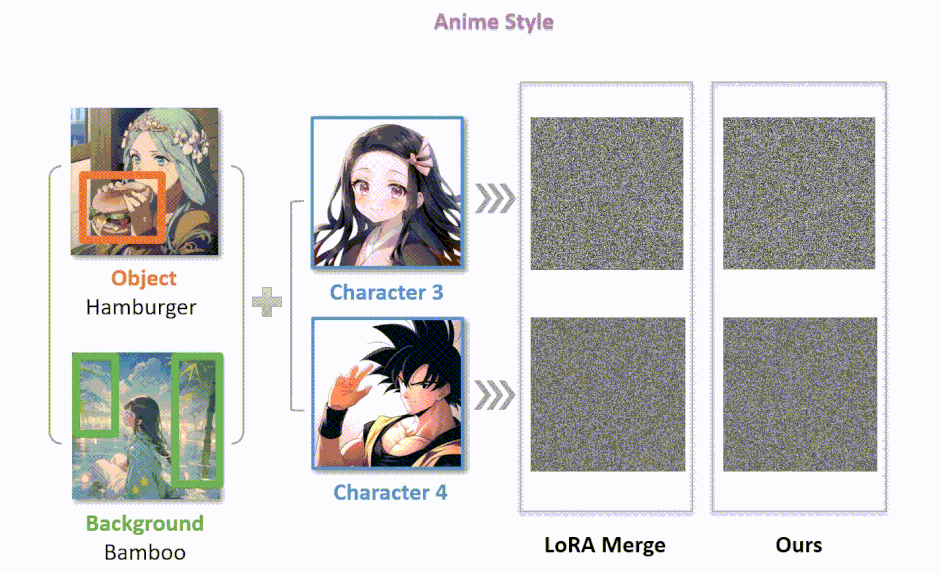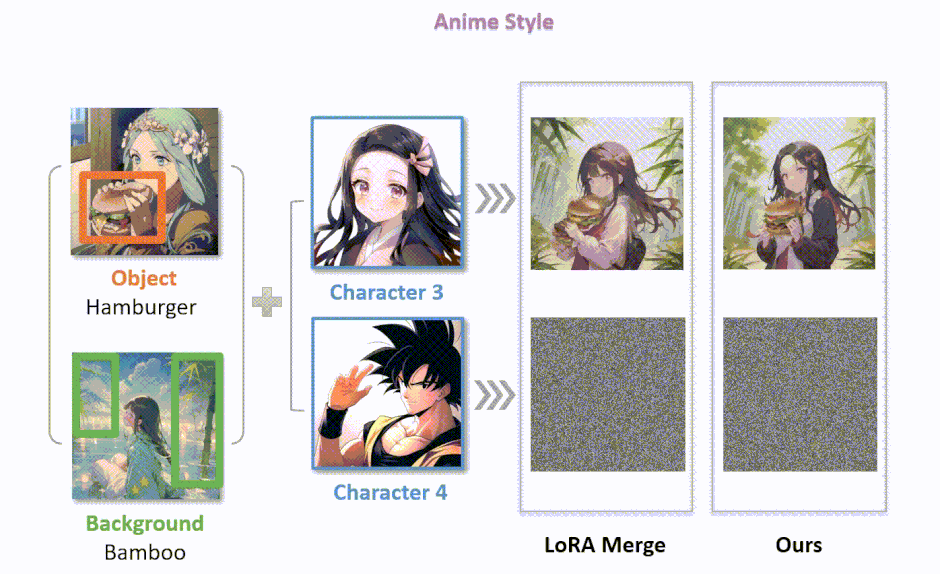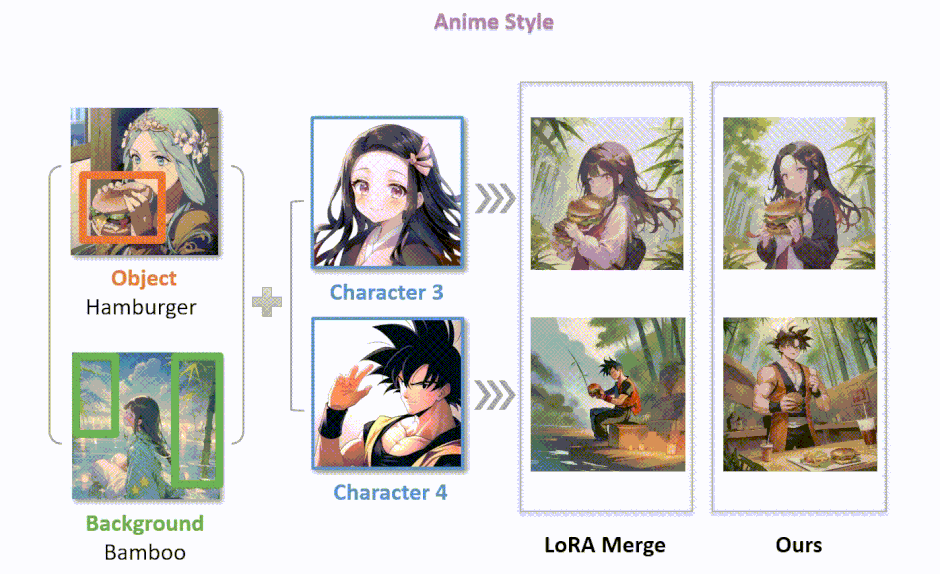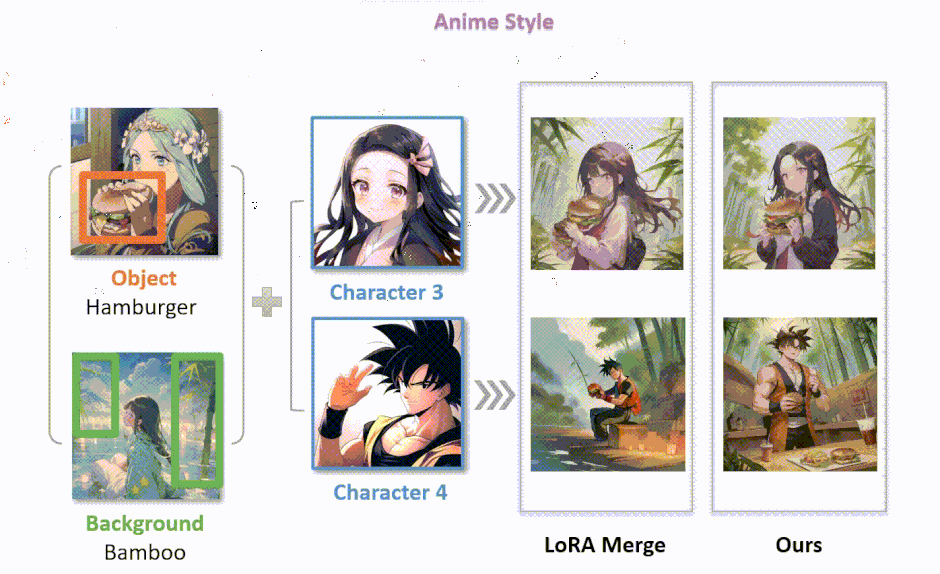
複数のLoRAを適応する画像合成法「Multi-LoRA」
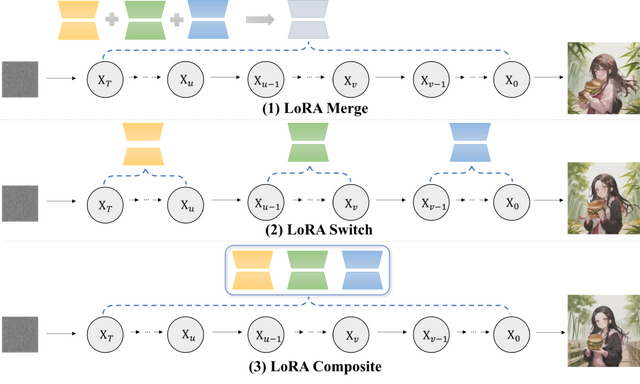
この研究では、LoRA(Low-Rank Adaptation)技術を組み合わせて、より詳細でパーソナライズされた画像を生成する方法について探究しています。具体的には、デノイジング(画像を徐々に明瞭にしていく過程)の各ステップで、1つまたは全てのLoRAを利用する2つの新しい手法を紹介しています。
第1の手法「LoRA Switch」では、画像生成の各ステップで異なるLoRAを交互に使用します。例えば、バーチャル試着シナリオでは、キャラクターLoRAと衣服LoRAを連続するデノイジングステップで交互に切り替えることで、各要素が精密かつ明瞭に描かれるようにします。
第2の手法「LoRA Composite」では、各ステップでの全LoRAからのスコアを組み合わせて、画像生成をバランス良く導きます。これにより、すべての要素がうまく組み込まれた画像を生成できます。
さらに、この研究では「ComposLoRA」という、LoRAを用いた画像生成のためのテストベッドを開発しています。このテストベッドには、現実とアニメの2つの視覚スタイルにまたがる6つのLoRAカテゴリーが含まれており、480の異なる組み合わせセットを用いて、提案された手法の有効性を評価しています。
評価方法として、画像の品質と組み合わせの効果を評価するためにGPT-4Vを使用しています。実験結果は、提案された2つの手法が従来のLoRA統合手法よりも優れていることを示しており、特に複数のLoRAを組み合わせる場合の効果が顕著です。また、人間による評価も行い、自動評価フレームワークの有効性を確認しています。

Multi-LoRA Composition for Image Generation
Ming Zhong, Yelong Shen, Shuohang Wang, Yadong Lu, Yizhu Jiao, Siru Ouyang, Donghan Yu, Jiawei Han, Weizhu Chen
Project | Paper | GitHub













