








生成AIを用いた動画の生成は2023年に大いに盛り上がり、2024年はさらに発展が期待される分野です。年明けに早速、そんな動画生成に関する研究「DragNUWA」が公開されました。
DragNUWAは「ドラッグで動きの指示を与えて動画を生成できる」動画生成AI。Microsoft Research AsiaのChenfei Wu氏・Nan Duan氏らによる研究です。
ProjectNUWA/DragNUWA (リポジトリ)
DragNUWAの出力例
以下はローカルに用意したDragNUWAの環境で生成した例です。まずは元となる画像を用意します。

DragNUWA_demo.pyを実行してこの画像を選択し、次のように矢印を記入します。

4羽それぞれに異なる動きを指定しました。従来のSVD(Stable Video Diffusion)では、まずそのままでは出力されない動きです。結果は次のようになりました。

動きも画質もよくありませんが、引いた矢印に沿った動きが生成されていることが確認できます。これは今までの動画生成AIには難しかった制御です。
DragNUWAを使うには
現在DragNUWAは以下の3つの環境で試せることを確認しています。
Google Colabでデモを動かす(Google Colab で DragNUWA を試す|npaka)
ローカルでデモを動かす
いずれも公式デモを動かすものですが、これがかなり粗削りです。少し操作を間違えるだけでエラーが出るのでいくつか注意すべきポイントがあります。
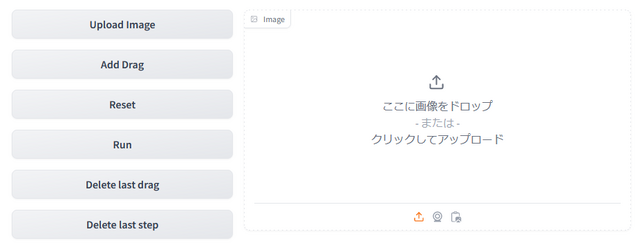
画像はボタンからロード
「ここに画像をドロップ」と堂々と書いてありますが、それでは正常に処理が行われません。必ず「Upload Image」ボタンからロードしましょう。
動きの指示はクリックで
画像のロード後、ドラッグすれば矢印を描けそうに見えますが、これもエラーを起こします。
正しくは矢印ひとつを描くごとに、まず「Add Drag」を押し、矢印の始点から順にクリックでポイントを指定します。間違えた場合は「Delete last drag」で矢印ごと、「Delete last step」でポイント単位の取り消しが可能ですが、任意の箇所の削除などはできません。
動かしたい箇所にはなるべく矢印を
矢印を描いていない箇所は動きがあまり出ないため、現実的な動画にしたい場合、あちこちに矢印を置いた方が良い結果になるようです。
出力は低画質
VRAMや負荷との兼ね合いなのか、デモの出力は576×320ピクセルと小さなGIFアニメーションです。解像度を上げたり出力をMP4にするなどしたければ、Colabやローカルでデモの改造が必要です。
その他サンプル
他にもいろいろ動かしてみました。全てWindows環境で、GPUはRTX 4060 Ti 16GBを使用しています。少なくとも16GBのVRAMがあれば動作は可能です。






インタフェースの問題と緩急の欠如によって、全体的に直線的で単調な動きになっています。
それでもこのまま適した用途はいろいろと考えられますし、使えるシーンは非常に多そうです。
動きの制御が難しい従来の動画生成AIモデルを使い、アタリを引くまで生成を繰り返す時間を大幅に減らせるだけでも大きな前進です。
動画生成の課題と動きの指示
SVDやRunway Gen-2、Pika、moonvalleyなど昨年までに様々な動画生成モデルやサービスが登場しました。これらはどれも「テキスト指示」「画像」「画像内の動かしたい箇所指定」という3つの方法で動画を生成します。
いずれの方法も一長一短があります。
テキスト指示:動きの指定も多少可能だが求める画が出る確率が低い
画像からの生成:求める画に近くても動きが指示できない
画像の一部を指定する方法:よりコントローラブルですが局所的で、動きの具体的な指示もできない
こうした動画生成の課題への回答のひとつが、DragNUWAのような直接的な動きの指示です。簡単な矢印によって向きと強さが指定できると、これまでより遥かに高い確率で求める動きが得られます。
もちろん作例に見るように、制御できるということは、逆に適切に制御しなければ不自然にもなり得ます。しかし画像生成がControleNetという制御技術で大きく発展したように、動画で現実的かつローカルで動く制御手法が登場したことは重要です。
こうした制御の登場は他の可能性も開きます。たとえばGPT-4Vなど画像を認識するLLM(大規模言語モデル)に元画像を与え、「写っているものに適切な動きを想定し、矢印の座標をjsonで返して」といった指示を行うことで、より自然で複雑な動きの生成も可能になるかもしれません。
またこれが刺激となって次々と新たな動画生成の制御手法が公開されるのも楽しみです。
ライセンスについて
DragNUWAは一から開発された動画生成モデルではなく、昨年公開されたStablity AIのSVDをベースにしています。DragNUWAのコードのライセンスはMITライセンスという自由度の高いものが明示されていますが、推論に必要な学習済みのモデルデータはライセンスが明記されていません。
ベースにしたSVDは標準では商用利用が禁止された固有のライセンスで、Stablity AIの有料メンバーシップに加入している場合のみ商用利用が可能です。
もしDragNUWAのモデルデータがこのライセンスの影響を受けている場合、そのままでは商用利用できません。現時点では研究利用に留めた方が良いでしょう。



















