

1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第28回目は、ボイスクローンした後、他の言語へのTTS、そして感情を含む細かい表現が可能な技術「OpenVoice」など、生成AI最新論文の概要5つをお届けします。
生成AI論文ピックアップ
短い音声から別の内容を他言語で話させる音声AI「OpenVoice」。感情、アクセント、リズム、イントネーションも操作可能>
対話から音声に応じて生き生きと動くリアルアバターを生成するモデル「From Audio to Photoreal Embodiment」、Metaなどが開発
短い音声から別の内容を他言語で話させる音声AI「OpenVoice」。感情、アクセント、リズム、イントネーションも操作可能
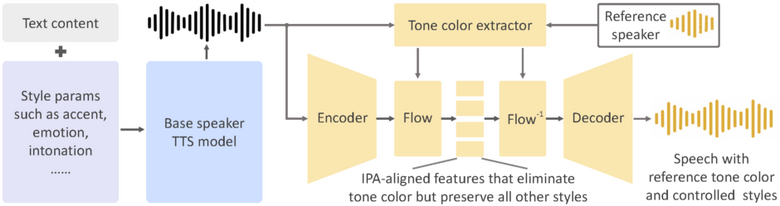
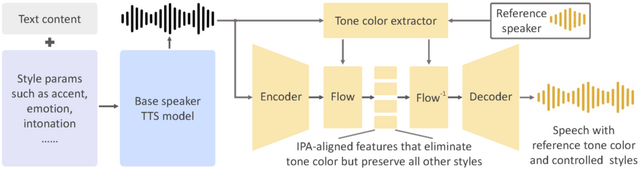
「OpenVoice」は、短い音声クリップから参照話者の声を模倣し、さまざまな言語で異なる内容の音声を生成する声質クローニング技術です。この技術は、感情、アクセント、リズム、イントネーションなど、声のスタイルを細かく制御できる点が特徴です。
これにより、参照話者の声色だけでなく、それらの声のスタイルも自由に操ることが可能になります。従来の手法と異なり、OpenVoiceは声質クローニング後の声のスタイルを柔軟に操作できます。
OpenVoiceは、多言語話者の大規模データセット(MSMLデータセット)を必要とせず、未知の言語においても声質クローニングを実現します。これは、従来の手法がすべての言語に対して大規模なトレーニングデータを要求していたのとは対照的です。
技術的には、OpenVoiceは「Base Speaker TTS Model」と「Tone Color Converter」を組み合わせて使用します。Base Speaker TTS Modelは、声のスタイル(感情、アクセント、リズム、イントネーションなど)と言語を制御する役割を持っています。これにより、声の特性を細かくカスタマイズできます。Tone Color Converterは、参照話者の声色を模倣し、それを基本話者モデルの音声に適用する役割を果たします。声色を変換する過程で、元の音声のスタイル要素を保持します。
訓練プロセスでは、英語、中国語、日本語の話者を含む多言語データセットが使用されています。特にTone Color Converterは、2万人以上の個人から収集された30万以上のオーディオサンプルを用いてトレーニングされています。

OpenVoice: Versatile Instant Voice Cloning
Zengyi Qin, Wenliang Zhao, Xumin Yu, Xin Sun
Project | Paper | GitHub | Demo
WebサイトをGPT-4Vで理解してタスクを処理するウェブエージェント「SeeAct」
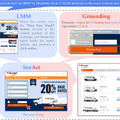
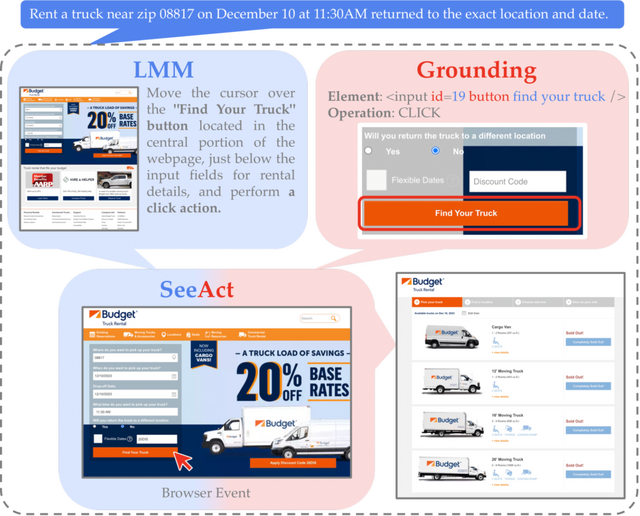
本研究では、GPT-4V(ision) を基盤とするウェブエージェント「SeeAct」を提案します。SeeActは、ウェブサイト上での視覚的理解と行動を統合し、ウェブサイト上でのタスクを自然言語の指示に従って完了することができます。
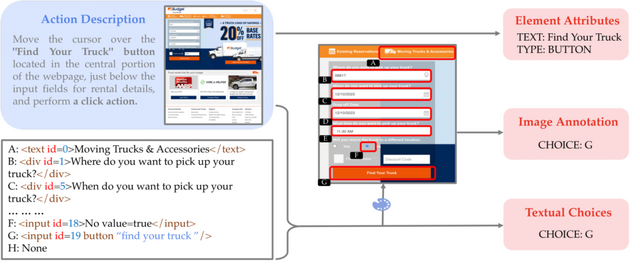
SeeActは、ウェブサイト上でのタスクを実行するために二段階のプロセスを行います。最初の「Action Generation」では、GPT-4Vがウェブページを分析し、タスクを達成するためのアクションプランをテキスト形式で生成します。続いて「Action Grounding」では、このテキストプランをウェブサイト上の具体的なHTML要素と操作に適用し、実際のアクションを実行します。
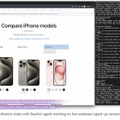
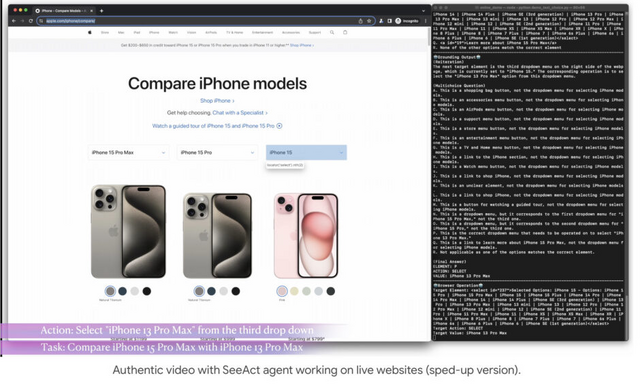
例えば、Appleのホームページで「iPhone 15 Pro MaxとiPhone 13 Pro Maxを比較する」というタスクが与えられた場合、エージェントはまずアクション生成で「iPhoneカテゴリにナビゲートする」などの行動のテキスト記述を生成します。その後、これらのテキスト記述をウェブページ上の具体的なアクション(例えば、ボタンのクリックやテキストフィールドへの入力)に変換するプロセスを行います。
研究者らは、最近のMIND2WEBベンチマークでSeeActの評価を行いました。オフライン評価に加えて、ウェブサイト上でのウェブエージェントのパフォーマンスを測定する新しいオンライン評価ツールを開発しました。このオンライン評価では、GPT-4Vはウェブサイトのタスクの50%を成功裏に完了しました。
GPT-4V(ision) is a Generalist Web Agent, if Grounded
Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, Yu Su
Project | Paper | GitHub
対話から音声に応じて生き生きと動くリアルアバターを生成するモデル「From Audio to Photoreal Embodiment」、Metaなどが開発
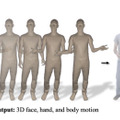
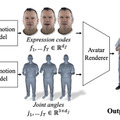
この研究は、2人の対話に基づいて、詳細なジェスチャーを行う写実的なフルボディーアバターを生成するフレームワークについて提案しています。フレームワークは、話し手の音声に応じて、個々の顔、体、手の詳細なジェスチャーを出力するよう設計されています。
このプロセスでは、まず会話のオーディオが入力として使用されます。このオーディオデータから、顔、体、手の動きを表す3Dモーションが生成されます。次に、この生成された動きは訓練されたアバターレンダラーに送られ、最終的に写実的なビデオが作成されます。
このプロセスの重要な側面は、ベクトル量子化(VQ)と拡散モデルを組み合わせて使用することです。これにより、音声と同期して、さまざまなジェスチャーや表情の動きが生成されます。例えば、指を指す動きやあざ笑い、にやりとする表情など、生き生きとした動きが可能になります。
評価実験の結果、提案されたモデルは、以前の研究や他の手法(特に拡散法やVQ法のみを使用する方法)と比較して、より多様で適切なジェスチャーを生成することが示されました。
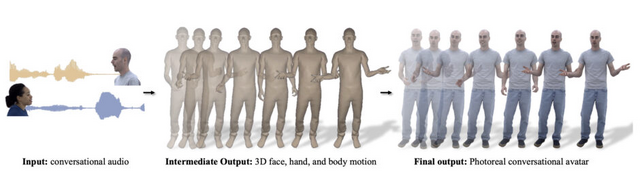
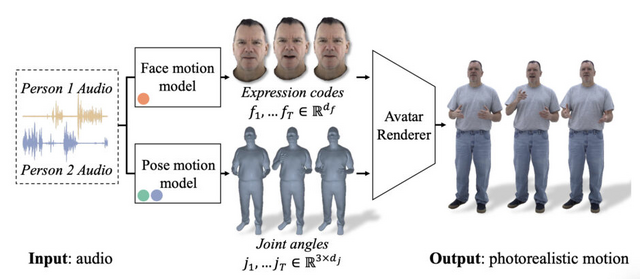
From Audio to Photoreal Embodiment: Synthesizing Humans in Conversations
Evonne Ng, Javier Romero, Timur Bagautdinov, Shaojie Bai, Trevor Darrell, Angjoo Kanazawa, Alexander Richard
Project | Paper | GitHub | Demo
小規模なのに高性能な言語モデル「TinyLlama」、小型モデルでも多くのデータで訓練すれば良い結果に
通常、大規模言語モデルは多くのデータを使ってトレーニングされ、優れた結果を示していますが、この研究は小規模モデルでも多くのデータでトレーニングすることで良い成果が得られることを示しています。
この研究では、「TinyLlama」というモデルが開発されました。これは、約3兆トークンを使用してトレーニングされた1.1B(11億)パラメータのモデルです。小型モデルをこれほどの大規模なデータでトレーニングするのは初めての試みです。
既存の大規模言語モデルのパラメータ数と比較すると、GPT-3で1750億、LLaMa2で700億と、11億が桁違いに少ないのが分かります。それにも関わらず、TinyLlamaは、既存のオープンソース言語モデルと比較して競争力のある性能を示し、様々な下流タスクでOPT-1.3BやPythia1.4Bを上回っています。これにより、小規模言語モデルでも多くのデータ量でトレーニングすると高い性能が得られることが示唆されました。
小型モデルであるTinyLlamaは、モバイルデバイスなどのエンドユーザーアプリケーションや、言語モデルに関連する幅広いプラットフォームとしての活用が期待されています。

TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, Wei Lu
Paper | GitHub | Demo
画像やテキストから高品質な3Dアバターを生成するモデル「En3D」はアニメーション化や編集も容易。アリババなどが開発
通常、3D生成モデルは様々なアイデンティティ、衣服、ポーズを持つ着衣人間を生成するために3Dデータセットで訓練されますが、これらデータセットの入手が難しく、一般化能力に制限があります。最近の研究では、2D画像コレクションから3D生成モデルを学習する方法が示されていますが、品質や解像度に限界があることが指摘されています。
En3Dは、これらの問題を解決するために開発された新しい手法です。En3Dは、実際の3Dデータや2D画像に依存せず、テキスト指示や画像からリアルな見た目、正確な形状、そして多様な内容を持つ3Dアバターを生成することができます。この方法では、合成された2Dデータから3Dモデルを学習し、それを用いて人間の姿勢や外見を正確に再現します。
En3Dは「3D Generative Modeling」、「Geometric Sculpting」、および「Explicit Texturing」という3つの主要部分から構成されています。これらのモジュールはそれぞれ、様々な視点から合成された人間の画像を使用してリアルな3Dアバターを作成し、作成したアバターの形状を細かく作り上げ、人間の肌や服のテクスチャを精密に作る機能を持っています。
実験の結果、En3Dは従来の方法よりもはるかに高い品質の3D人間を作り出すことができ、それらはアニメーション化や編集も簡単に行えます。これにより、よりリアルで多様な3D人間アバターを様々なデジタルコンテンツで使用することが可能になります。


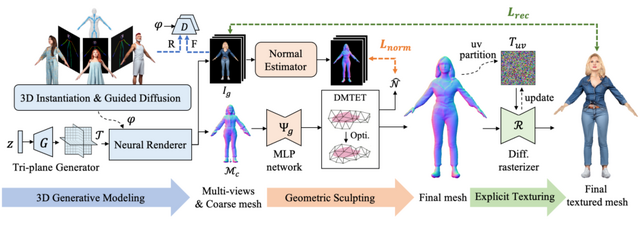
En3D: An Enhanced Generative Model for Sculpting 3D Humans from 2D Synthetic Data
Yifang Men, Biwen Lei, Yuan Yao, Miaomiao Cui, Zhouhui Lian, Xuansong Xie
Project | Paper | GitHub