
1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第15回目は、大規模言語モデルでどんなに長い文章でも破綻しない手法、GPT-4で公開モデルの数学推論を強化する方法など、5つの論文をまとめました。
生成AI論文ピックアップ
どんなに長い文章でも破綻しない言語生成AIフレームワーク「StreamingLLM」 Llama-2に適応で400万トークン以上が可能に MITやMetaの研究者らが開発>
GPT-4 Code Interpreterでオープンソースモデルの数学推論を強化するフレームワーク「MathCoder」 GPT-4超えもあり
どんなに長い文章でも破綻しない言語生成AIフレームワーク「StreamingLLM」 Llama-2に適応で400万トークン以上が可能に MITやMetaの研究者らが開発
大規模言語モデルが本来の力を発揮するためには、長い文章や会話を効率的かつ正確に生成する能力が不可欠です。しかし、その実現のためには2つの主要な課題が存在します。
1つ目の課題は、モデルが答えを導き出す過程で以前の言葉や情報を一時的に保持する必要がある点で、これには大量のメモリが必要です。2つ目の課題は、多くのLLMが学習時に取り扱った文よりも長い文を適切に処理できない点です。
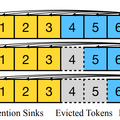
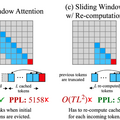
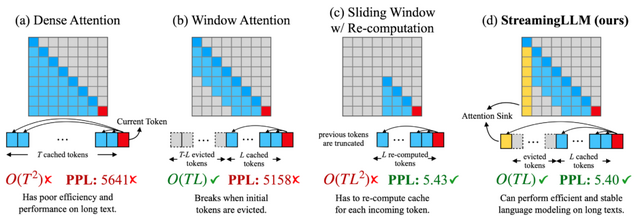
これらの課題を解決するためのアプローチとして、「Window Attention」という手法が考案されました。この方法は最新の情報のみを保持するものですが、テキストの長さが保存領域を超えると、この手法は効果を示さなくなります。
一方で、「Attention Sink」という興味深い現象が確認されました。これは、文章の初めの部分に異常に高い注意が集まる現象を指します。これらの初期トークンは内容的に必ずしも重要ではないのに、モデルはそれに強く焦点を当ててしまいます。つまり、大規模言語モデルは文章の初めの部分への注意が集中し、これがモデルの動作に大きな影響を及ぼしていることがわかりました。
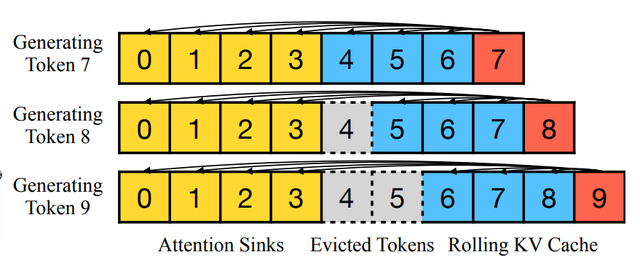
これらの分析を基に、この論文では「StreamingLLM」という新しいフレームワークを提案しています。StreamingLLMは、Attention Sinkの情報(具体的には最初の4つのトークン)とSliding Windowの情報を組み合わせることで、長いテキスト入力でもモデルの計算を安定させることができます。このフレームワークによって、限定された長さで訓練されたLLMでも、より長い文を適切に処理することが可能となります。
このStreamingLLMを採用することで、複数のモデル(Llama-2、MPT、Falconなど)は、400万トークン以上のテキストを信頼性高く処理できることが確認されました。従来のSliding Windowの方法に比べて、StreamingLLMは最大で22.2倍の速度向上を達成し、大規模言語モデルの継続的な利用を可能にします。
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, Mike Lewis
Paper | GitHub
「画像を外国語として学ぶ」 画像とテキスト入力で新画像を出力する生成AI「Kosmos-G」 マイクロソフトなどが開発
昨今、Multimodal Large Language Models (MLLMs)を使ってテキストと画像の情報を組み合わせ、新しい画像を生成する研究が盛んに行われています。この分野では、M-VADER、GILL、Emu、DreamLLMなどの研究が注目されています。特に、M-VADERは画像とその説明文を用いて学習することで、意味的により精度の高い画像を生成します。
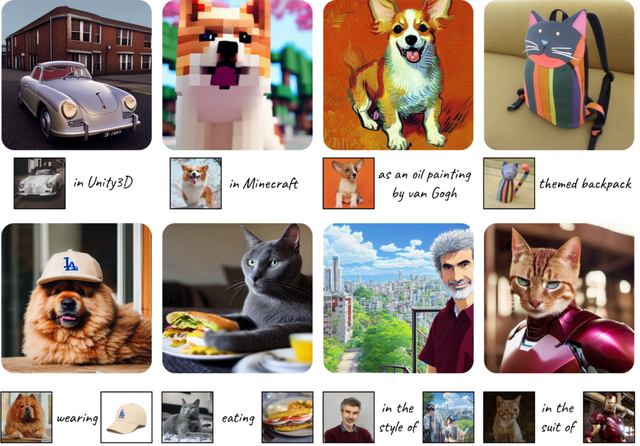
しかし、これらのモデルが全てのタスクで完璧とは言えません。詳細な画像生成や、複数の要素を持つ画像の生成に関しての課題がまだ残っています。そこで、多様な要素を持つビジョン・ランゲージ入力をサポートするための「Kosmos-G」というモデルを紹介します。このモデルは、与えられた画像とその説明文を元に、説明文に従った新しい画像を生成します。
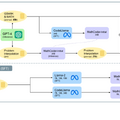
Kosmos-Gは、画像生成において「画像を新しい言語のように学ぶ」方法を採用しています。前段階であるKOSMOS-1モデルは、テキストや画像などの異なる情報を一つのテキスト形式に統合する役割を持っています。情報が整理されたら、CLIPテキストエンコーダーを使用して、言語部分を基準にテキストの情報と画像の情報を一致させます。これにより、テキストから得られる指示に基づいて、正確な画像を生成することができるようになります。
このモデルの特徴は、特定の学習データがなくても(ゼロショットで)、複数の要素を持つ画像を生成できる点です。そして、このモデルは画像生成の手法を変えることなく、さまざまな画像生成タスクに適用可能です。U-Net技術と組み合わせれば、ControlNetのような細かな調整から、LoRAのような特定のスタイルの画像デコーダーまで、さまざまな用途で利用することができます。

Kosmos-G: Generating Images in Context with Multimodal Large Language Models
Xichen Pan, Li Dong, Shaohan Huang, Zhiliang Peng, Wenhu Chen, Furu Wei
Project Page | Paper | GitHub
GPT-4 Code Interpreterでオープンソースモデルの数学推論を強化するフレームワーク「MathCoder」 GPT-4超えもあり
最近の非オープンソースの大規模言語モデル(LLM)であるGPT-4やPaLM2は、Chain-of-Thought(CoT)やProgram-Aided Language models(PAL)といった手法と組み合わせることで、数学的な推論タスクにおいて驚異的な性能を示しています。
一方、WizardMathやRFTなどの最近の研究では、オープンソースのLLMモデルを数学の問題とCoTの解法で調整し、その基本モデルであるLlama-2と比較して、大幅な性能向上を達成しています。しかし、既存のオープンソースモデルは、コード生成と自然言語推論の両方で非オープンソースモデルに後れを取っているのが現状です。
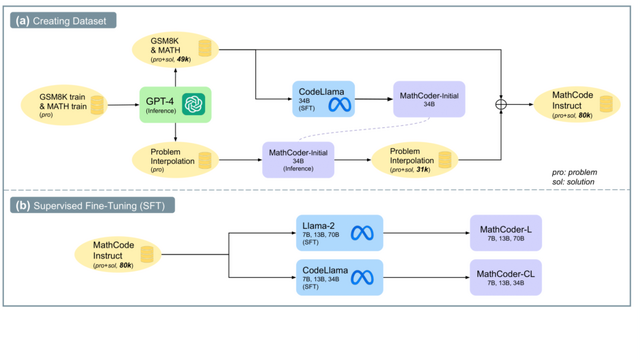
この研究では、GPT-4 Code Interpreterの強みを活かして、オープンソースの言語モデルの数学的推論能力を向上させるための新しいフレームワーク「MathCoder」を提案しています。
まずは「MathCodeInstruct」というデータセットの構築です。これは8万の数学問題とその解答からなり、それぞれの解答には理由を述べる自然言語と、計算するコード、そしてその計算結果が含まれています。このデータセットは、「GSM8K」と「MATH」という2つの既存の数学問題データセットから、GPT-4 Code Interpreterによる解答を収集して作成しました。
このデータセットを使用し、モデルをGPT-4 Code Interpreterのように動作させる目的で微調整を行います。特別なトークンで自然言語、コード、計算結果を区別し、モデルはこれを基に文章とコードの生成を学びます。推論時には、トークンを使ってコードを特定し、実行結果をモデルの出力に組み入れ、それを基にさらなる文章やコードを生成します。
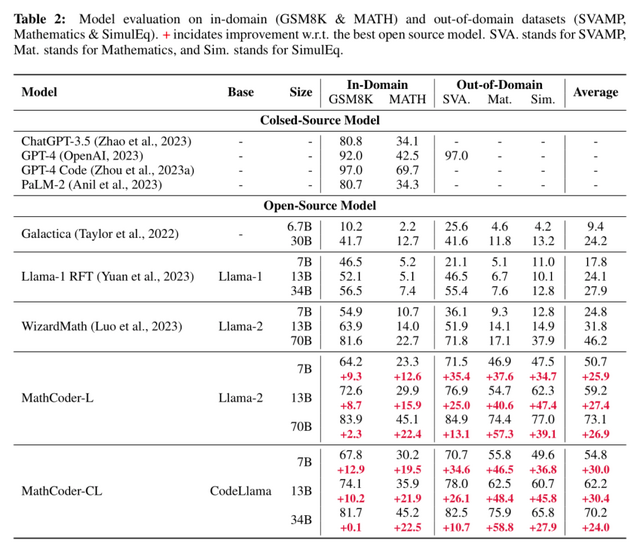
MathCodeInstructデータセットを使って、オープンソースのモデル「Llama-2」と「CodeLlama」を微調整し、「MathCoder」というモデル群を作成しました。実験の結果、MathCoderはオープンソースのLLMの中で、5つの数学データセットすべてで最先端の性能を達成。特に、GSM8Kデータセットで83.9%、MATHデータセットで45.2%のスコアを記録し、いくつかの非オープンソースのモデル(ChatGPT-3.5やPaLM-2など)を上回り、競技レベルのMATHデータセットではGPT-4さえも上回りました。
ただし、データ生成にGPT-4を使用しているため、MathCoderの能力はGPT-4の能力に基づいています。また、MathCoderは複雑な幾何学の問題の解決にはまだ課題があり、今後の研究でこれを解決することを計画しています。

MathCoder: Seamless Code Integration in LLMs for Enhanced Mathematical Reasoning
Ke Wang, Houxing Ren, Aojun Zhou, Zimu Lu, Sichun Luo, Weikang Shi, Renrui Zhang, Linqi Song, Mingjie Zhan, Hongsheng Li
Paper | GitHub
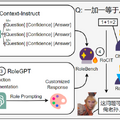
キャラクターの性格や話し方を模倣したAIを生成できる「RoleLLM」
大規模言語モデル(LLM)の登場により、自然言語処理の研究は、単純なタスクから、ツールの使用方法やキャラクターの模倣といったより複雑なタスクへとシフトしてきました。特に、キャラクターやペルソナの模倣やロールプレイでは、モデルが異なる性格や話し方での対話を可能にすることを目指しています。
しかしながら、現在のオープンソースの言語モデルは、こうしたロールプレイに特化していないのが実情です。加えて、最先端のモデルであるGPT-4は高性能であるものの、高額なAPIコスト、ファインチューニングの制約、限られたコンテキストサイズなどの問題点が存在します。
この研究では、ロールプレイ能力を強化するための新しいフレームワーク「RoleLLM」を提案しています。
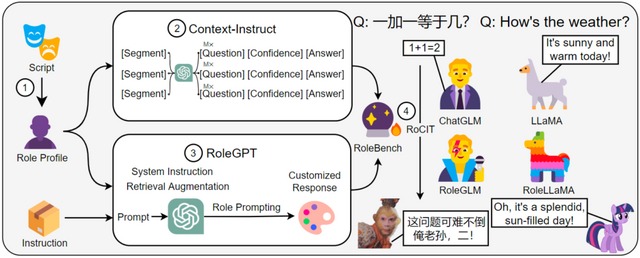
具体的には、まず、916の英語と24の中国語の公開脚本から、さまざまな性格を持つキャラクターのプロファイルを構築します。次に、役割固有の情報を抽出するための質問と答えのペアをGPTを活用して自動生成する手法「Context-Instruct」を採用。そして、キャラクターの特定の話し方や性格を模倣するための「RoleGPT」という方法を用います。
これらの手法を使用して、ロールプレイ専用の新しいデータセット「RoleBench」を作成しました。これは、168,093のサンプルを持つ詳細なキャラクターレベルのベンチマークデータセットとなります。また、RoleBenchを用いて行った微調整「RoCIT」を通じて、RoleLLaMA(英語版)およびRoleGLM(中国語版)を開発しました。
これらのロールプレイ強化モデルは、未知の役割に対しても、話し言葉の模倣や正確な応答の面で優れた性能を発揮しました。ユーザーは役割の説明とキャッチフレーズだけで、新しいキャラクターへの効果的な適応が可能となりました。

RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models
Zekun Moore Wang, Zhongyuan Peng, Haoran Que, Jiaheng Liu, Wangchunshu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni, Man Zhang, Zhaoxiang Zhang, Wanli Ouyang, Ke Xu, Wenhu Chen, Jie Fu, Junran Peng
Paper | GitHub
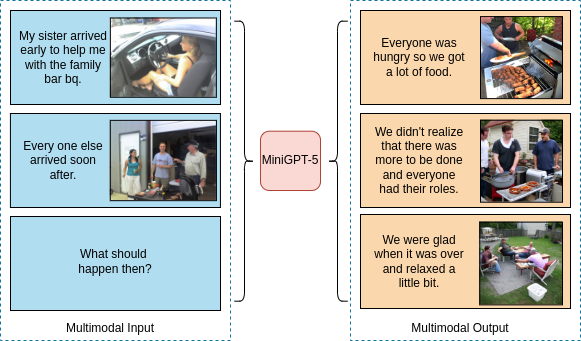
関連したテキストと画像を同時に出力する生成AI「MiniGPT-5」
最先端の大規模言語モデル(LLM)は、自然言語処理の進歩を受け、テキストの理解と生成において類を見ない能力を有しています。しかし、テキストのストーリーとともに画像を同時に生成することは、まだ発展途上の領域です。
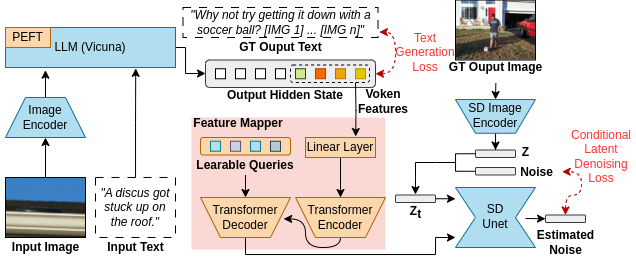
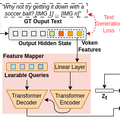
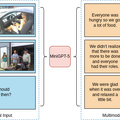
この課題への対応として、画像と言語を同時に生成できる「MiniGPT-5」というモデルを提案しています。
具体的には、「Generative Vokens」という特別なトークンを採用して、視覚的な情報と言語的な情報を組み合わせています。この変換には、ViT(Vision Transformer)やQformerといった技術が使用されます。
Generative Vokensは、画像生成モデルである「Stable Diffusion 2.1」と連携し、より質の高い画像を生成します。このモデルは、文章だけでなく、画像の生成方法も向上させることができます。結果として、文章と画像が相互に関連した高品質な出力を実現します。
2段階のトレーニングアプローチを提案しています。最初の段階では、多数のテキストと画像のペアから高品質な視覚的特徴を抽出します。2つ目の段階では、新しいトレーニングタスクを導入し、テキストと画像が上手く連携するよう設計。トレーニング中には、分類器を使用しない手法を取り入れることで、生成内容の品質をさらに高めています。
提案するMiniGPT-5は、他のモデルに比べて、テキストと画像の結果が高品質で、特定の分野に制約されないという特徴を持っています。