



1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第10回目はAIによるソフトウェア開発支援、音声を理解できる言語モデル、人物画像学習の新たな手法など、5つの論文をまとめました。
生成AI論文ピックアップ
テキスト指示からソフトウェアを自動開発するチャットベースのAIフレームワーク「ChatDEV」
ソフトウェア開発は基本的に「コード」と「ドキュメント」という二つの言語形式で行われるため、大規模言語モデル(LLM)が得意とする分野です。この研究で提案する「ChatDEV」は、ユーザーからのテキスト指示に基づき、ソフトウェア開発をチャットベースで自動的に行います。
ChatDEVはバーチャルなソフトウェア開発会社として機能し、タスクを指定すると設計、コーディング、テスト、ドキュメント作成といった一連のプロセスを自動で管理します。各フェーズでは特定の「エージェント」(例:プログラマー、レビュアー、テスター)を活用し、作業を詳細なサブタスクに分割して実行します。
この方法により、コードに関する潜在的な課題、特に「ハルシネーション」(誤ったコード生成など)を軽減します。
実験結果によれば、ChatDEVは非常に高い効率でソフトウェアを開発できました。具体的には、約7分でソフトウェアを生成し、そのコストはわずか約0.3ドルでした(約44円)。レビュアーとプログラマー間の対話により、20種類のコードの脆弱性が特定および修正され、テスターとプログラマー間の対話によって、10種類以上の潜在的なバグが特定および解消されました。
これらの実験は、ChatDEVの自動ソフトウェア開発プロセスの効率性とコスト効果性を実証しています。各チャットでの役割間の効果的なコミュニケーション、提案、および相互評価を通じて、このフレームワークは効果的な意思決定を可能にします。
執筆現在、X(旧Twitter)で「ChatDEV」を検索すると、すでに沢山のユーザーが簡単なゲームを作って楽しんでいます。

Communicative Agents for Software Development
Chen Qian, Xin Cong, Wei Liu, Cheng Yang, Weize Chen, Yusheng Su, Yufan Dang, Jiahao Li, Juyuan Xu, Dahai Li, Zhiyuan Liu, Maosong Sun
Paper | GitHub
人が話す声とやり取りする大規模言語モデル「LLaSM」
人々が普段話す言葉には、意味だけでなく、イントネーションや抑揚など、多くの情報が含まれています。そのため、人間とAIとの対話においては、テキストよりも音声がより自然で理解しやすいと言えます。とはいえ、現在の大半の大規模言語モデルはテキスト入力のみに対応しています。
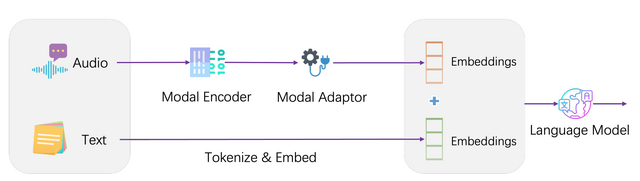
この課題に対処するために新しいAIモデル「LLaSM」が開発されました。LLaSMは音声とテキストの両方の指示に対応することができます。
特に、音声信号をエンコードするために「Whisper」という技術を採用しています。この技術によって、音声データは言語モデルが理解できる形式に変換されます。この音声エンコーディングとテキストエンコーディングを効果的に組み合わせることで、モデルは音声でもテキストでも指示を理解し、実行できます。
音声とテキストの指示に対応するためのデータセットはまだ少ない状態ですが、LLaSMの開発チームは独自の大規模データセット「LLaSM-Audio-Instructions」を構築しました。このデータセットは、英語と中国語の両方の音声サンプルを含み、クロスモーダルな指示に対応するための最大規模のデータセットとされています。
LLaSM: Large Language and Speech Model
Yu Shu, Siwei Dong, Guangyao Chen, Wenhao Huang, Ruihua Zhang, Daochen Shi, Qiqi Xiang, Yemin Shi
Project Page | Paper | GitHub
テキスト指示で高品質な動画編集ができるAI「MagicEdit」 中国ByteDanceの研究者らが開発
MagicEditは、ビデオのスタイリゼーション(例:振り向く女性の動きをそのままに、アニメ風の女の子に変換)、ローカル編集(例:動画内の人物の顔だけを別の顔に変換)、アウトペインティング(例:上半身だけの走る男性の下半身を予測して生成)など、多様な下流の編集タスクをサポートします。
このツールを使用すると、テキスト指示だけで簡単に洗練された動画エフェクトや編集が可能です。特に、コンテンツ、形状、動きをうまく調整する学習方式が採用されており、高品質な動画が作成できます。
ビデオ編集には、大きく「フレーム毎の編集」と「クリップ毎の編集」の2つの方法があります。フレーム毎の編集は、動画を一枚一枚の写真(フレーム)に分けて、それぞれを編集する方法です。この方法は、ディテールやテクスチャをフレーム間で保持するのが難しく、大きな動きがある場合には特に問題となります。
クリップ毎の方法は、個々のフレーム(画像)に対して編集を行うのではなく、動画全体を一つのまとまりと考えて編集を行います。この方式では、ビデオ全体にわたって一貫性があり、断片的なエフェクトや不自然な動きが減少します。ただし、ネットワーク全体を更新する必要があり、テキストから画像へのモデルの知識が失われる可能性があります。
MagicEditは、これらの課題を解決し、両方の方法の長所を取り入れた新しいビデオ編集ツールです。訓練中にコンテンツ、構造、動きを明示的に分離することで、高精細で時間的に一貫したビデオへの変換が可能です。


MagicEdit: High-Fidelity and Temporally Coherent Video Editing
Jun Hao Liew, Hanshu Yan, Jianfeng Zhang, Zhongcong Xu, Jiashi Feng
Project Page | Paper | GitHub
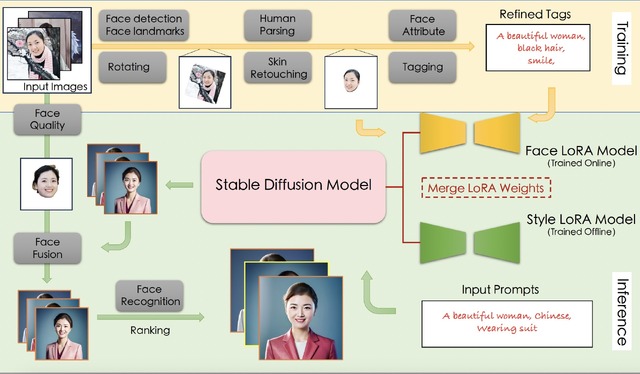
顔の特徴を保持した新しい人物写真を生成するAI「FaceChain」 中国アリババグループの研究者らが開発
FaceChainは、同じ人物の複数枚の写真を入力として、顔の特徴やアイデンティティを維持しながら、新しい人物画像を生成するフレームワークです。
具体的には、FaceChainはStable Diffusionモデルに2つのLoRA(Low-Rank Adaptation)モデルを組み込むことで、個々のスタイルと特徴を同時に統合する能力を持っています。
訓練段階では、顔とスタイルに関連するデータを使用して、face-LoRAとstyle-LoRAモデルを訓練します。これらのモデルは基礎となるStable Diffusionモデルと統合され、テキストに基づいて、個々の顔の特徴とスタイルを持つ画像を生成します。生成された画像は後処理とランキングを経て、最も高品質なものがユーザーに提供されます。
このフレームワークにより、入力された顔の形や特徴を大きく逸脱することなく、顔に関連する多様なモデルを統合し、特定の人物のアイデンティティを保持したポートレートを生成できます。
FaceChainは、ModelScopeというオープンソースコミュニティに基づいており、このコミュニティはさまざまな分野のモデルを一つにまとめ、統一されたインタフェースで提供することを目的としています。

FaceChain: A Playground for Identity-Preserving Portrait Generation
Yang Liu, Cheng Yu, Lei Shang, Ziheng Wu, Xingjun Wang, Yuze Zhao, Lin Zhu, Chen Cheng, Weitao Chen, Chao Xu, Haoyu Xie, Yuan Yao, Wenmeng Zhou, Yingda Chen, Xuansong Xie, Baigui Sun
Paper | GitHub
映像内の動く人や物を分離する手法「VideoCutLER」 Meta含む研究者らが開発
ビデオ解析が必要な場面は多く、例えば防犯カメラ、自動運転車、ビデオ編集などがあります。しかし、ビデオにラベルをつける作業は高コストです。そのため、ラベルなしでビデオの内容を理解できる新しい方法が求められています。
これまでの研究では、「オプティカルフロー」と呼ばれる技術がよく使われていました。この技術は画像の動きを検出するためのものですが、完璧ではありません。例えば、動かないオブジェクトや複雑な動きをするもの、物体が重なっている場合、あるいは照明が変わる場合には、正確に認識できないことがあります。
この問題を解決するために、「VideoCutLER」というインスタンスセグメンテーション(個々の物体を識別・分割する技術)を行うモデルを開発しました。このモデルは、ビデオ内の物体(例えば、犬や猫、人など)を自動で識別し、それぞれを追跡しながら区別できます。
この方法では、ラベルのない単一の画像からシンプルなビデオを自動で生成し、それを用いてビデオ解析のモデルを訓練します。まず、「MaskCut」と呼ばれる技術を用いて、画像から物体の「仮のマスク」を作成します。次に、そのマスクを使ってビデオを生成し、モデルを訓練します。
ラベルが付けられていない画像だけで訓練されたにも関わらず、推論時にはVideoCutLERを未知のビデオに直接適用でき、複数のインスタンスを分割および追跡することが可能です。
このVideoCutLERモデルは、YouTubeVIS2019という厳しいテストでも高い評価を受けています。従来の最高評価よりも大幅にスコアを上げ、ラベル付きとラベルなしの性能差も縮小しました。これにより、手作業でのラベリングが不要な状況でも、高精度なビデオ解析が可能であることが証明されました。