


「毎日がゲームチェンジャー」と言われる生成AI(Generative AI)。日々革新的な技術が発表されていて、その重要性を見極めながらキャッチアップするのはなかなか困難です。テクノロジー関連の重要な論文を2014年からわかりやすくまとめているWebサイト「Seamless」を運営している山下裕毅さんに、1週間分の生成AIに関する重要論文をピックアップして、解説していただく新連載を、ここにスタートします。
生成AI論文ピックアップ
ドラッグして画像編集するAI「Drag Your GAN」のオープンソースとデモ
本研究は、画像内の変えたい箇所をドラッグするだけで気軽に編集できるシステム「Drag Your GAN」を提案するものです。論文は2023年5月にプレプリントとして公開されていましたが、今回はデモがHugging Faceで公開され、GitHubにてソースコードも公開されました。
Drag Your GANでは、入力画像内の被写体に対してA点(スタート地点)からB点(ゴール地点)までを設定し、さらに画像のどの領域だけを編集可能にするかのマスク(画像内の明るい箇所)を描くことができます。これにより、指定した領域内だけ点移動に従った編集が実行されます。
直感的で手軽にできる操作性が利点です。シンプルな操作でありながら、GAN(Generative Adversarial Networks)による画像生成アルゴリズムで周囲と調和した自然な仕上がりを見せます。
被写体は、人や動物、車、風景などなんでも対象。例えばライオンの顔の向きを変えたい場合、ライオンの鼻にA点(赤点)、移動させたい箇所にB点(青点)を置き、頭部を囲むようにマスクして実行すると首の角度を変えられます。

Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
Xingang Pan, Ayush Tewari, Thomas Leimkühler, Lingjie Liu, Abhimitra Meka, Christian Theobalt
Project Page | Paper | GitHub | Hugging Face
2点を使って画像を編集する、拡散モデルを用いたAI「DragDiffusion」 ByteDance含む研究者らが開発
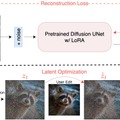
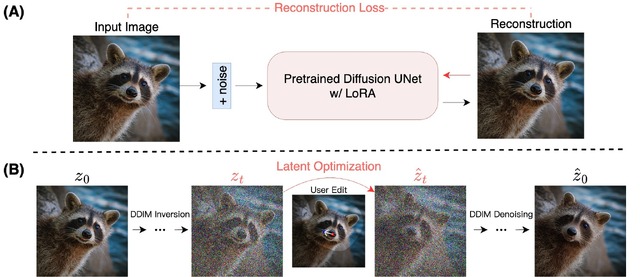
本研究は、上記の「Drag Your GAN」の改良版として、画像編集システム「DragDiffusion」を提案するものです。Drag Your GANは素晴らしい結果を達成していますが、GAN固有のモデル能力により、その適用性は制限されています。この問題を解決するために、今回は拡散モデルを利用しています。
DragDiffusionは、事前に学習された大規模な事前学習済み拡散モデルをインタラクティブなポイントベース編集フレームワークに活用することを可能にし、ドラッグ編集の汎用性を大幅に向上させます。
システムでは、まず編集前にLoRAを使用してUNetのパラメータを微調整し、ユーザーの入力画像を再構成します。これにより、編集プロセスでオブジェクトの同一性と入力画像のスタイルをより良く保持できます。次に、ユーザーの編集指示(A点、B点、マスク)に基づいて、DDIMノイズ除去を行いながら編集プロセスを進めます。
DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing
Yujun Shi, Chuhui Xue, Jiachun Pan, Wenqing Zhang, Vincent Y. F. Tan, Song Bai
Project Page | Paper | GitHub
顔の正面写真1枚から後頭部を含む360度の3D頭部モデルを生成するAI「PanoHead」 ByteDanceなど開発
真正面の顔写真1枚から、見えない後頭部を含めた360度の3D頭部モデルを再構築するフレームワーク「PanoHead」を提案する研究です。これまで複数の入力画像から頭部全体を再構成するアプローチは多くありました。また1枚の顔写真から3Dに変換するアプローチもありましたが、正面近くの視点での合成に限られていました。
今回は、これらの課題を解決し、正面の顔写真1枚から詳細なジオメトリを使用して一貫した高忠実度のフルヘッド3D画像を生成します。提案フレームワークは、GAN(Generative Adversarial Network)を使用して学習されており、前頭部と後頭部の特徴を分離する表現や、不完全なカメラポーズと位置ずれのある画像に適応的に対応する、新しい2段階画像位置合わせスキームなどで構成されています。


PanoHead: Geometry-Aware 3D Full-Head Synthesis in 360°
Sizhe An, Hongyi Xu, Yichun Shi, Guoxian Song, Umit Y. Ogras, Linjie Luo
Project Page | Paper | GitHub
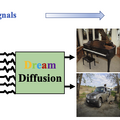
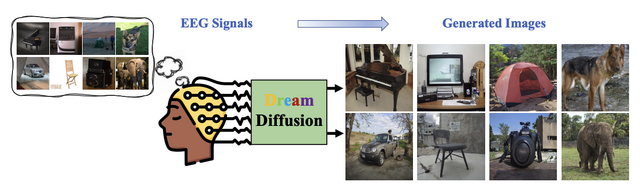
脳波から画像を生成するAI「DreamDiffusion」 テンセント含む中国の研究者らが開発
本研究では、脳波(EEG)から高品質な画像を生成する学習モデル「DreamDiffusion」を提案します。脳活動から見ている画像を拡散モデルで生成する手法はこれまでも研究されていましたが、その多くは磁気共鳴機能画像法(fMRI)を利用しており、手軽さがなく実用的ではありませんでした。
今回の手法は、ポータブルな市販製品も登場している、非侵襲的かつ低コストで脳の電気活動を記録する脳波(EEG)を活用。提案システムではStable Diffusionが用いられ、EEGと画像のペアからなるデータセットによる微調整を行います。またCLIPエンコーダでEEGとテキスト、画像の空間の整列を行います。これにより、ノイズの多い脳波データから品質の高い画像を出力します。
生成された画像の品質は高いものの、使用されたEEGと画像のペアデータは、6人の被験者がImageNetデータセットから40の異なるカテゴリに属する2000枚の画像を見ながら記録された脳波のコレクションです。したがって、40カテゴリに限定されていることに留意する必要があります。
DreamDiffusion: Generating High-Quality Images from Brain EEG Signals
Yunpeng Bai, Xintao Wang, Yanpei Cao, Yixiao Ge, Chun Yuan, Ying Shan
Paper
テキストから人の動きを3Dで生成するAI「MotionGPT」 テンセント含む研究者らが開発
プロンプトベースの指示により、もっともらしい人間の動きを3Dで生成するシステム「MotionGPT」を提案する研究。このシステムでは、人間の動作を外国語として扱い、自然言語モデルを動作関連生成に導入し、単一のモデルで多様な動作タスクを実行します。
具体的には、まず、人の動きを言語の語彙に似た「モーション語彙」として扱い、生のモーションデータをモーショントークンに変換。次に、モーショントークンの基本的な文法や構文、およびそれに対応するテキスト記述との関係を学習するために、事前に訓練された言語モデルを使用します。
これまでの類似研究と比較して、高い忠実度で3Dモーションを生成できることが示されましたが、制約として、このシステムは人間に限定されており、手や頭などの詳細な部分には対応していない点に留意する必要があります。

MotionGPT: Human Motion as a Foreign Language
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang YU, Tao Chen
Project Page | Paper | GitHub
テキストからパノラマ画像を生成するAI「MVDiffusion」 ByteDance含む研究者らが開発
本研究では、テキストからパノラマ画像を生成する「MVDiffusion」を提案します。このシステムは、最大1024×1024ピクセルの高解像度な写真のようなパノラマ画像を生成するだけでなく、メッシュからのデプスマップのシーケンスが与えられると、基礎となるジオメトリを保持し、マルチビューの一貫性を維持しながらシーンメッシュのテクスチャマップを生成できます。
システムは、3つの主要なモジュールで構成。まず、(1)生成画像間の一貫性を強制するために低解像度の画像を生成するモジュールがあります。次に、(2)生成された低解像度画像を取り込み、同じネットワークアーキテクチャと重みを使用して、密な補間を作成する補間モジュール。最後に、(3)高解像度の画像間の一貫性と低解像度画像上の条件付けを強制するための高解像度へのアップスケーリング超解像度モジュールがあります。
これらの3つのモジュールを組み合わせることで、MVDiffusionはパノラマ生成と多視点深度画像生成において最先端の性能を発揮し、従来のアプローチで起こる問題を効果的に軽減することが実験によって示されました。

MVDiffusion: Enabling Holistic Multi-view Image Generation with Correspondence-Aware Diffusion
Shitao Tang, Fuyang Zhang, Jiacheng Chen, Peng Wang, Yasutaka Furukawa
Project Page | Paper | GitHub | Hugging Face