



この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第136回)は、AIらが複雑な作業を全自動処理してくれる商用利用も可能なオープンソースAIエージェント「DeerFlow 2.0」や、普段の対話でAIエージェントを自分好みに育成できる「OpenClaw-RL」を取り上げます。
また、1枚のイラストからLive2Dに使える分割素材を自動生成する「See-through」や、長時間動画から3D復元するGoogle開発のAI「LoGeR」をご紹介します。
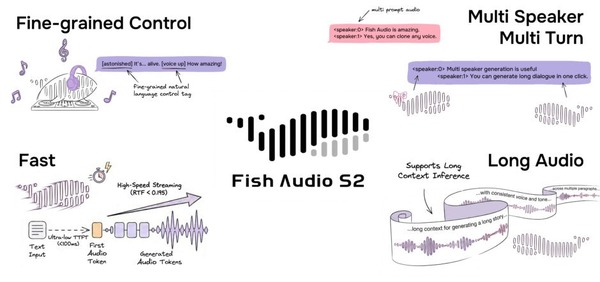
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、人間の声と区別がつきにくいレベルに迫るリアルな音声を複数話者一括生成できるオープンソソースのText-to-Speech(TTS)「Fish Audio S2」を別の単体記事で取り上げています。
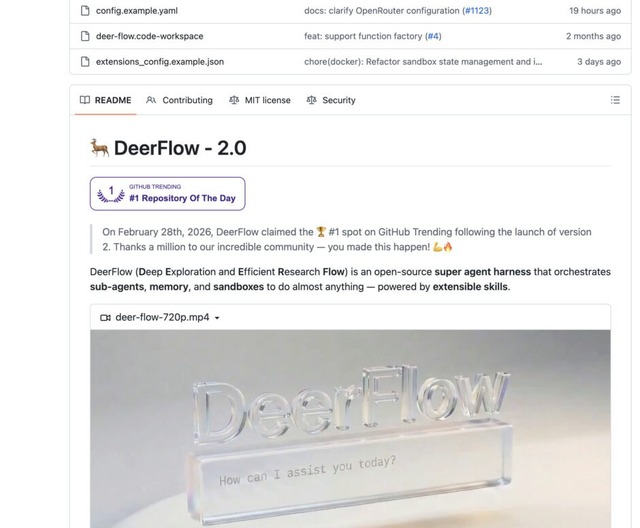
複数AIが複雑な作業を全自動処理。商用利用も可能なオープンソース・AIエージェント「DeerFlow 2.0」をByteDanceが発表
ByteDanceが公開しているオープンソースプロジェクト「DeerFlow」のバージョン2.0がリリースされ、GitHubトレンドで1位を獲得するなど注目を集めています。初代モデルはDeep Researchに特化したフレームワークでしたが、今回のアップデートでコードをゼロから書き直し、あらゆる複雑なタスクをこなすことができます。
特徴としては、自律的に動くサブエージェント、過去のやり取りを保持する長期記憶、そして安全なサンドボックス環境を統合している点です。単なるチャットボットのように回答を生成するだけでなく、エージェント自身が隔離されたDocker環境を持ちます。
これにより、エージェントが自らコードを実行したりファイルを編集したりしながら、数分から数時間かかるような複雑な作業を処理できるようになりました。大きなタスクは複数のサブエージェントに分割され、並行して効率的に進められます。
DeerFlow2.0には、AIに様々な仕事をさせるためのスキルとツールが備わっています。最初から用意されている機能に加えて、自分好みの新しい機能や外部ツールを、モジュール追加で拡張できます。
DeerFlow2.0はMITライセンス下で利用可能です。
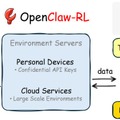
普段の対話でAIエージェントを自分好みに育成できる「OpenClaw-RL」
AIアシスタントにもっとこう答えてほしいと訂正しても、現在のAIはその会話データを学習源として活用せず、次に活かすことができません。この状況を解決するのが、日常のやり取りからAIをリアルタイムで学習させるシステム「OpenClaw-RL」です。
このシステムは、得られたやり取りから行動の良し悪しを判定して報酬として数値化するだけでなく、ユーザーの具体的な指摘やエラーログからどう修正すべきだったかというテキストのヒントを抽出し、AIに直接指導します。推論、評価、学習の各プロセスが裏側で独立して動くため、システムを止めることなく、使いながらシームレスにAIをアップデートし続けることが可能です。
実験でも、ユーザーが要望を伝えながら数十回やり取りするだけで好みの口調や対応にパーソナライズされたり、複雑なソフトウェア開発やGUI操作のタスク性能が向上したりと、現場で使われながら成長し続けるAIの有効性が実証されています。
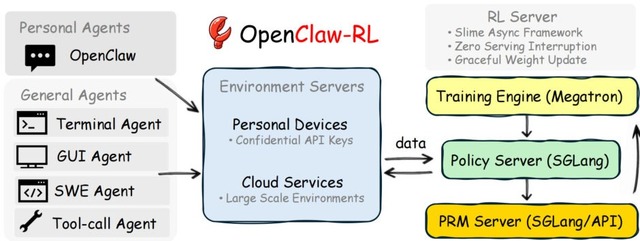
OpenClaw-RL: Train Any Agent Simply by Talking
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, Ling Yang
Paper | GitHub
1枚のイラストからLive2Dに使える分割素材を自動生成する「See-through」、パーツ分解・レイヤー分け・隠れ補完・重なり推定を全自動化
VTuberやビジュアルノベルの普及で、1枚のイラストを動かしたいというニーズは高まっています。その代表的な手法である「Live2D」は、イラストを数十~百以上のパーツに手作業で分け、隠れた部分を描き足し、前後関係を指定するという専門的な工程が必要です。
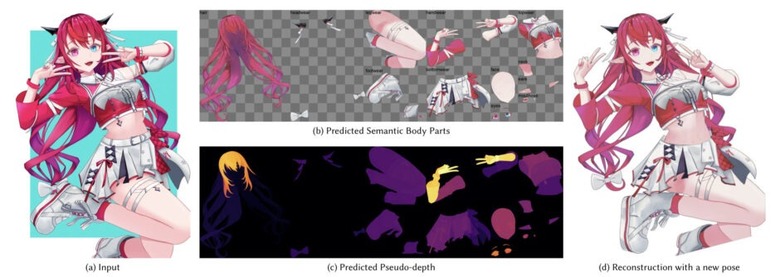
この課題に対し、今回の論文で発表された技術「See-through」は、1枚のアニメイラストから動かせる状態のレイヤー分解を自動で行うフレームワークです。
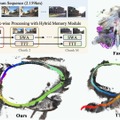
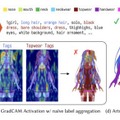
具体的には、入力画像を髪・目・腕など19種類のパーツに自動分離してRGBAレイヤーとして出力し、前髪の裏の額や服の下の体といった隠れた部分をAIが補完し、さらにパーツの重なり順を疑似深度マップとして推定します。髪が顔を前後から挟むような複雑な前後関係にも対応できるのが特徴です。
技術的には画像生成モデルSDXLベースの拡散モデルを採用し、約9,100体(訓練用約7,400)のLive2Dモデルから学習しています。
プロのアニメーターに出力PSDを渡した検証では、30~60分で高品質なモーションが作成でき、従来の手作業と比べて大幅な工数削減が確認されました。
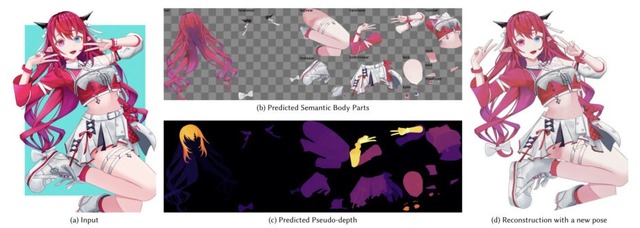
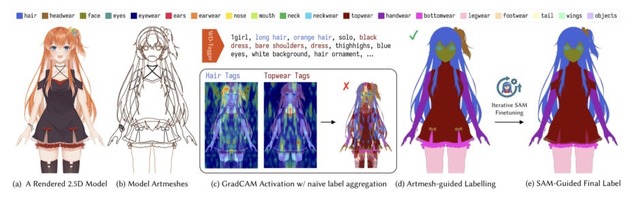




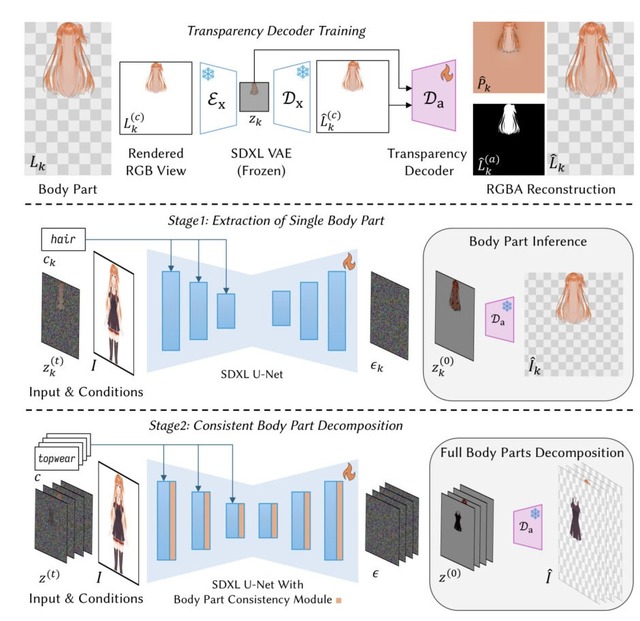
See-through: Single-image Layer Decomposition for Anime Characters
Jian Lin, Chengze Li, Haoyun Qin, Kwun Wang Chan, Yanghua Jin, Hanyuan Liu, Stephen Chun Wang Choy, Xueting Liu
Paper
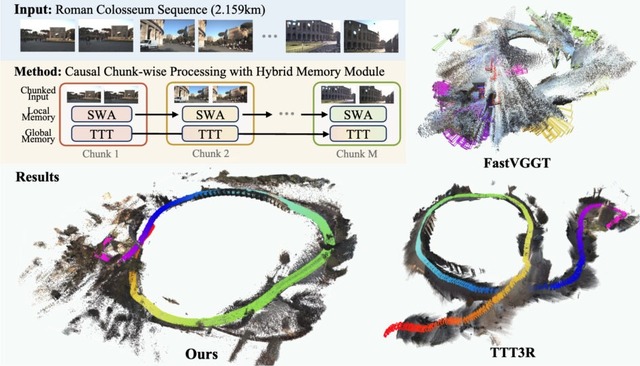
11.5kmの移動データも破綻なし。長時間動画から3D復元するAI「LoGeR」をGoogleなどが開発
Google DeepMindなどに所属する研究者らは、長時間の動画から高精度な3D空間を再構築するAIモデル「LoGeR」を発表しました。
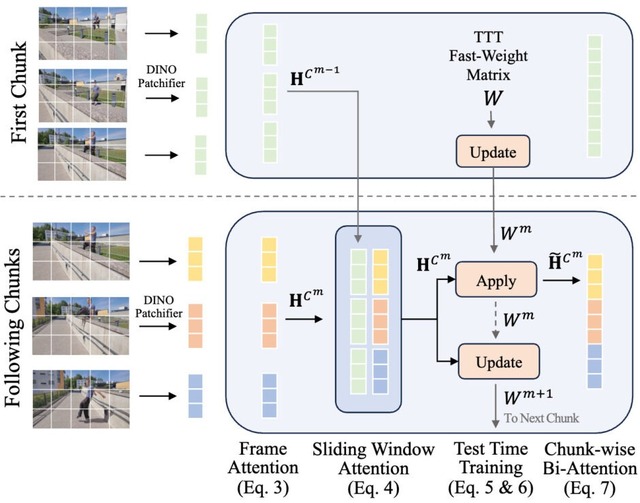
従来の手法では長い動画を処理すると計算量が膨張し、空間のスケールが大きく歪んでしまう課題がありました。LoGeRは動画を短い塊(チャンク)に分けて処理しつつ、隣接するコマを正確に繋ぐ機能と、全体のスケール感を記憶して長期的なズレを防ぐ機能を組み合わせた独自の2種類のメモリを導入することで、この問題を解決しています。
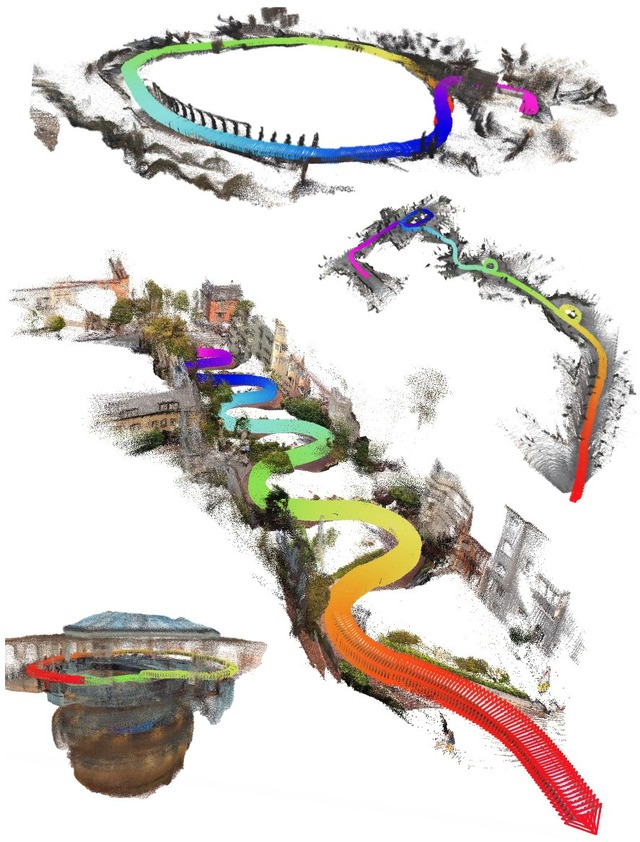
結果として、最大約1万9000フレーム(距離11.5km)という広大な移動データでも高品質に3D復元することに成功しており、自動運転やVR、ロボットナビゲーション分野への応用が期待されます。