
1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、大規模言語モデル(LLM)の「思考の連鎖」(Chain-of-Thought, CoT)推論能力は幻想だと主張した研究論文「Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens」を取り上げます。米アリゾナ州立大学に所属する研究者らが発表しました。
CoT推論は、「ステップバイステップで考えてみましょう」といった簡単なプロンプトを追加することで、LLMが複雑な問題を中間ステップに分解し、人間のような推論過程を生成する手法として注目されてきました。数学的問題解決や論理推論において顕著な成果を示し、LLMが意図的な推論プロセスを実行しているという認識を生み出してきました。
しかし研究チームは、この見かけ上の推論能力に対して疑問を投げかけます。CoT推論は真の論理的推論能力ではなく、訓練データの範囲や傾向(データ分布)から学習した統計的パターンを再現する洗練されたパターンマッチングメカニズムに過ぎないというのです。
研究では、アメリカ独立記念日が閏年か平年かという単純な質問に対するGeminiの回答を例として挙げています。モデルは「1776年は4で割り切れるが世紀年ではないので閏年である」と正しく述べた直後に、「したがって、アメリカが設立された日は平年だった」という論理的に矛盾した結論を導き出しました。このような事例は、モデルが表面的には理路整然とした推論を展開しながらも、実際には論理的整合性を欠いていることを示唆しています。
研究チームは、CoT推論の本質を理解するために「DataAlchemy」という独自のテスト環境を構築しました。この環境では、ゼロからLLMを訓練し、その性能が訓練データと異なる状況でどのように変化するかを体系的に調査することができます。例えば、「APPLE」という文字列を特定のルールで変換する問題を学習させ、その後で新しいパターンの問題を解かせるなどです。
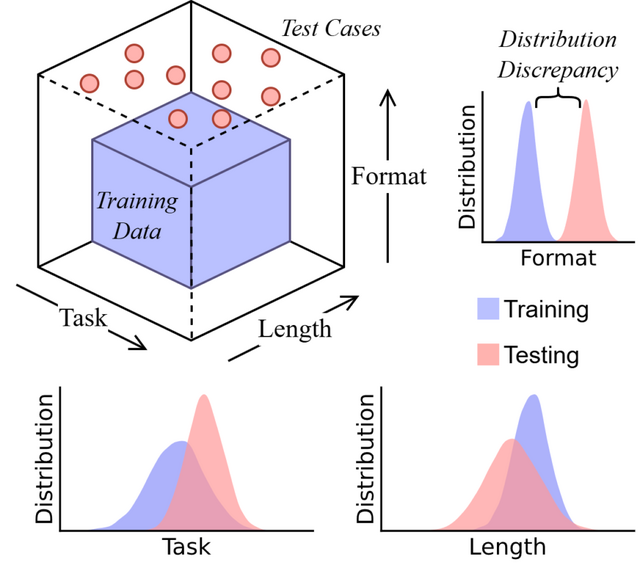
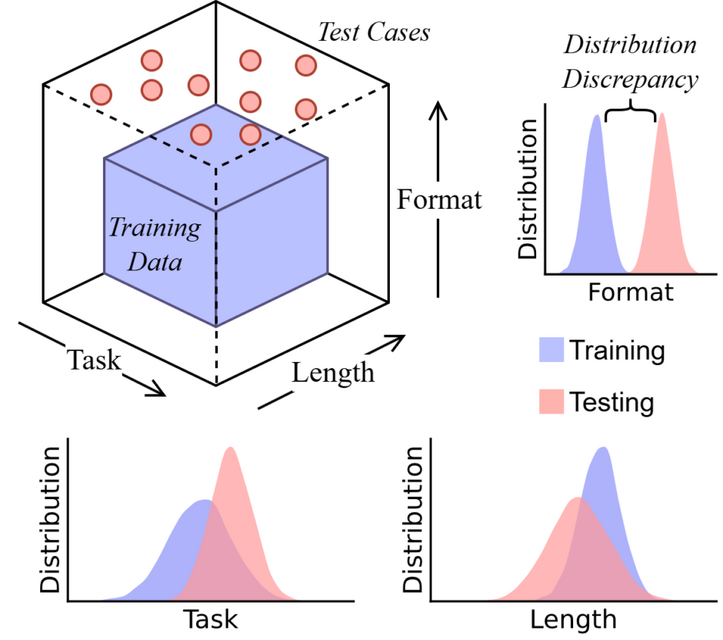
▲CoT推論をタスク、長さ、フォーマットの3つの次元から分析
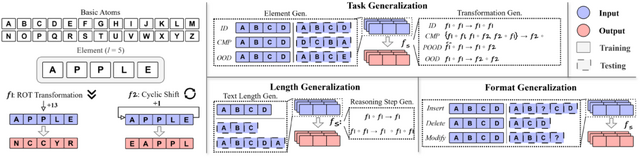
▲DataAlchemyのフレームワーク
結果は、訓練で見たのと全く同じパターンの問題なら100%正解しますが、少しでも違うパターンになると正答率がほぼ0%に落ちました。モデルは訓練で見たパターンに似た推論を生成しようとしますが、論理的な一貫性がなく、最終的に誤った結論に至ることが多くありました。
また、4文字の要素で訓練されたモデルは、3文字や5文字の要素に対して性能低下を示しました。さらに問題の尋ね方や言い回しといった表面的な形式をわずかに変えた結果、フォーマットの変化でも性能が低下しました。
研究チームは、少量の未見データでファインチューニングを行うことで、モデルが新しい分布に迅速に適応できることを発見しました。しかしこれは真の汎化能力の獲得ではなく、単にデータ分布内の範囲をわずかに拡張したに過ぎないと指摘しています。