



1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第41回目は、生成AI最新論文の概要5つを紹介します。
生成AI論文ピックアップ
ピクセルを1つずつ予測するのではなく、画像を粗い解像度から徐々に高解像度へと生成する、高速かつ高品質な画像生成AI「VAR」
GPT-4超えの精度でスマートフォンに導入できる20億パラメータを持つオンデバイスAIモデル「Octopus v2」をスタンフォード大学が開発
言語モデルの計算を最大50%高速にする「MoD」をGoogleが開発
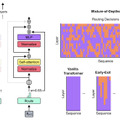
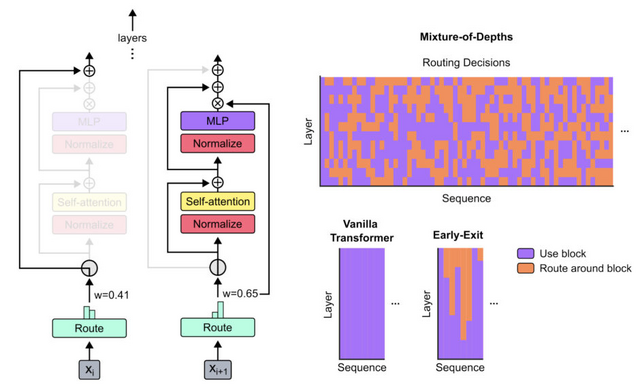
この研究では、Transformer言語モデルの計算効率を改善するMixture-of-Depths(MoD)という手法を提案しています。通常のTransformerは全てのトークンに均等に計算リソースを割り当てますが、MoDでは動的にトークンを選択し、必要な箇所にのみ計算を集中させます。
この手法により、モデルは計算量を動的かつ文脈に応じてトークン単位で割り当てることを学習します。その結果、同等の計算量とトレーニング時間で、ベースラインの性能に匹敵するモデルが実現できました。さらに、推論時の1回の順伝播あたりの計算量を大幅に削減でき、最大50%高速化できることが示されました。
また、MoDの仕組みはMixture-of-Experts(MoE)と組み合わせることもでき、それぞれの利点を生かすことができます。この研究は、大規模言語モデルを、より高速かつ省リソースに学習・推論できる可能性を示しており、機械翻訳や要約、質問応答など、様々な自然言語処理タスクへの応用が期待されます。
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
David Raposo, Sam Ritter, Blake Richards, Timothy Lillicrap, Peter Conway Humphreys, Adam Santoro
Paper
「画像生成AIのモデルサイズを大きくすればいいとは限らない」をGoogleなどが実証
潜在拡散モデル(LDM)は、高品質な画像生成において優れた性能を示していますが、サンプリング効率の低さが実用上の課題となっています。この研究では、LDMのスケーリング特性、特にモデルサイズとサンプリング効率の関係について実証的に調査しました。
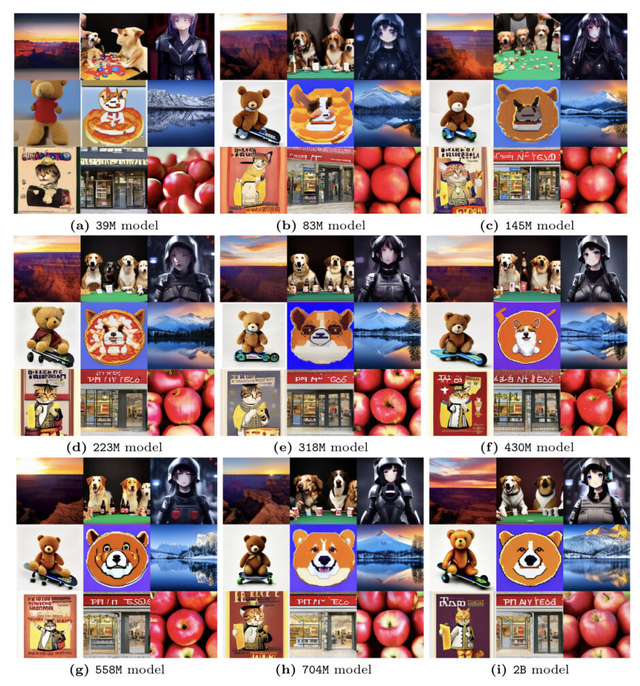
39Mから5Bまでのパラメータ数の異なる12種類のLDMを一から学習させた結果、モデルサイズを大きくすると、学習に使用する計算リソースの量に応じてtext-to-imageの性能が向上することが分かりました。また、事前学習の性能が高いほど、ダウンストリームタスクでの性能も高くなる傾向が見られました。
興味深いことに、同じサンプリングコストの制約下では、小さいモデルの方が大きいモデルよりも高品質の画像を生成できる場合が多いことが明らかになりました。さらに、ダウンストリームタスクにおいても、サンプリングステップ数が少ない場合は小さいモデルの方がサンプリング効率が良いことが示されました。
また、蒸留を適用した場合でも、サンプリングコストが制約された状況では、小さい蒸留モデルが大きい蒸留モデルと同等の性能を示すことが分かりました。
これらの結果から、LDMをスケールアップする際は、モデルサイズを大きくするだけでなく、推論時のサンプリングコストとのトレードオフを考慮することが重要であると言えます。特に、サンプリングコストが制約された状況では、小さいモデルの方が効率的に高品質の画像を生成できる可能性があります。

Bigger is not Always Better: Scaling Properties of Latent Diffusion Models
Kangfu Mei, Zhengzhong Tu, Mauricio Delbracio, Hossein Talebi, Vishal M. Patel, Peyman Milanfar
Paper
ピクセルを1つずつ予測するのではなく、画像を粗い解像度から徐々に高解像度へと生成する、高速かつ高品質な画像生成AI「VAR」
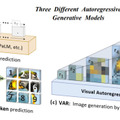
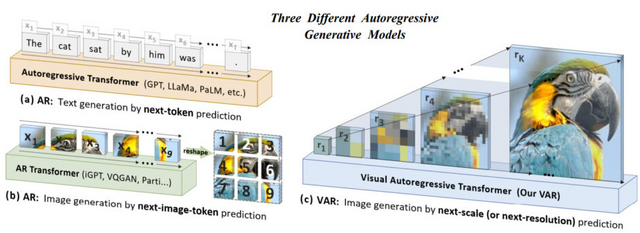
「Visual Autoregressive Modeling」(VAR)は、効率的でスケーラブルな画像生成の新手法です。従来の自己回帰画像モデルが「次のピクセルを予測する」という方式を用いていたのに対し、VARは「次の解像度を予測する」という方式を採用しました。
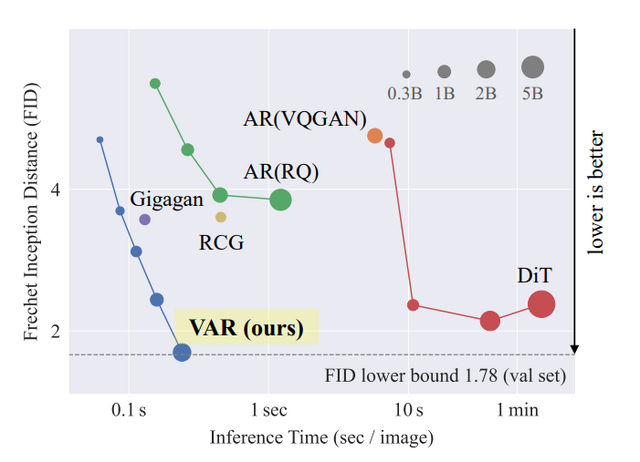
具体的には、VARは入力画像を複数の粗い解像度に量子化し、低解像度から高解像度へと段階的に潜在表現を生成していきます。この設計により、計算量が大幅に削減され、20倍以上の高速生成が可能になりました。また、空間的な局所性が保持され、CNNの利点を活かせます。
VARは数十億パラメータへの効率的なスケーリングが可能で、パラメータ数に対する性能向上に明確なべき乗則が認められました。これは大規模言語モデルと同様の特性です。ImageNetのベンチマークでは、わずか2Bパラメータで最先端のDiffusion Transformerを凌駕する高品質画像を生成できました。
さらに、VARは画像補完や編集などのゼロショット・タスクにも汎化できることが実証されています。

Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, Liwei Wang
Project | Paper | GitHub | Demo
パラメータ効率の高いファインチューニング手法「ReFT」をスタンフォード大学などが開発
大規模言語モデルを新しいタスクに適応させる際、モデルの全てのパラメータを更新するファインチューニングは非常に計算コストがかかります。そこで注目されているのが、パラメータ効率の良いファインチューニング手法「PEFT」です。PEFTは一部のパラメータのみを更新することで、メモリ使用量とトレーニング時間を削減しつつ、全パラメータを更新する場合と遜色ない性能を実現します。
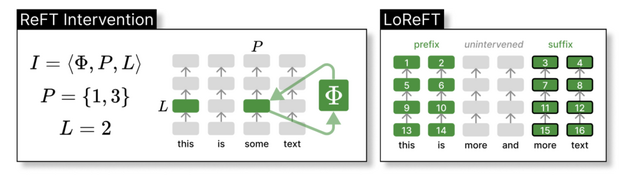
研究チームは、新しいPEFTアプローチ「Representation Finetuning」(ReFT)を提案しました。既存のPEFTがモデルの重みを更新するのに対し、ReFTはモデルの中間表現に介入することでモデルを制御します。研究では特に「Low-rank Linear Subspace ReFT」(LoReFT)という手法に焦点を当てており、これは低ランクの射影行列で張られる部分空間内で中間表現を編集するというシンプルかつ強力な手法です。
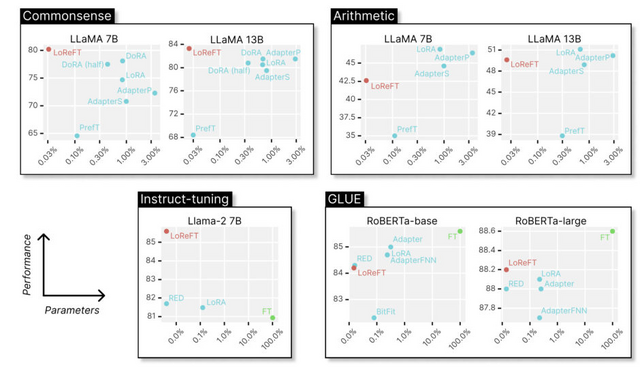
研究チームは、常識推論、算術推論、自然言語理解などの20以上のデータセットでLoReFTの性能を評価しました。その結果、LoReFTは最新のPEFT手法と比べてパラメータ数を10分の1から50分の1に抑えつつ、ほとんどのタスクで最高性能を達成しました。特に大規模なモデルほどLoReFTの優位性が顕著でした。
ReFT: Representation Finetuning for Language Models
Zhengxuan Wu, Aryaman Arora, Zheng Wang, Atticus Geiger, Dan Jurafsky, Christopher D. Manning, Christopher Potts
Paper | GitHub
GPT-4超えの精度でスマートフォンに導入できる20億パラメータを持つオンデバイスAIモデル「Octopus v2」をスタンフォード大学が開発
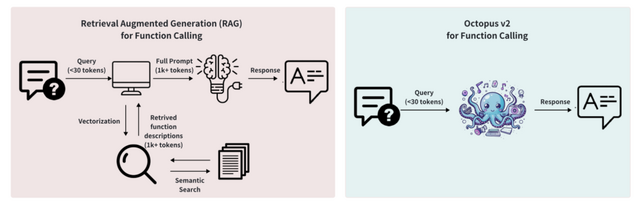
近年、言語モデルは自動化されたワークフローに関連するタスク、特に関数呼び出しの能力において、AIエージェントで効果を発揮しています。クラウド環境の大規模言語モデルは高い性能を示しますが、プライバシーとコストの懸念があります。一方、エッジデバイス上の言語モデルは、レイテンシと精度に課題を抱えています。
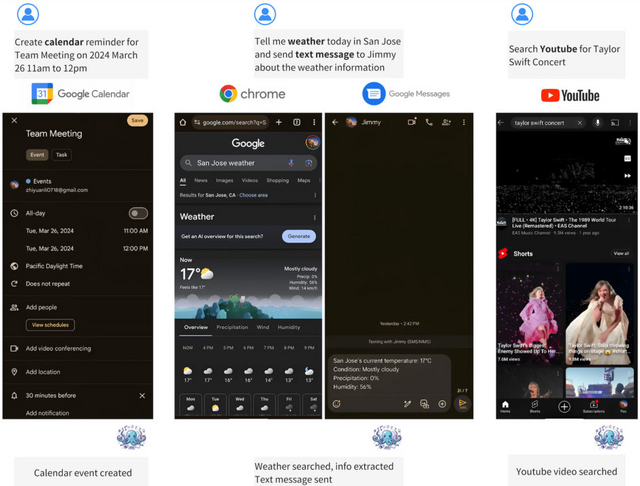
研究チームは、20億パラメータを持つエッジデバイス上で機能するオンデバイスAIモデル「Octopus v2」を開発しました。Octopus v2は、モバイルデバイス上でもAIエージェントを機能させることを目的に開発され、実際にGPT-4を上回る精度とレイテンシを実現しました。
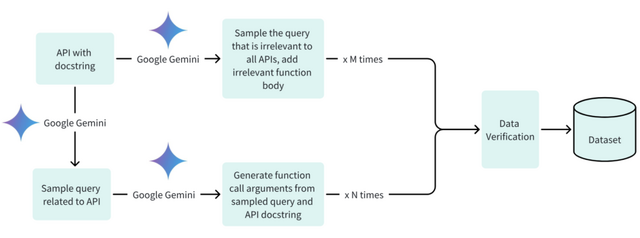
研究チームは、Google DeepMindのGemma 2Bという20億パラメータモデルをベースにして、Android API呼び出しに焦点を当てた特定のデータセットで微調整を行いました。トレーニングでは、デバイス上での実行のパフォーマンスを最適化するために、完全なモデルトレーニングとLoRA技術が用いられました。
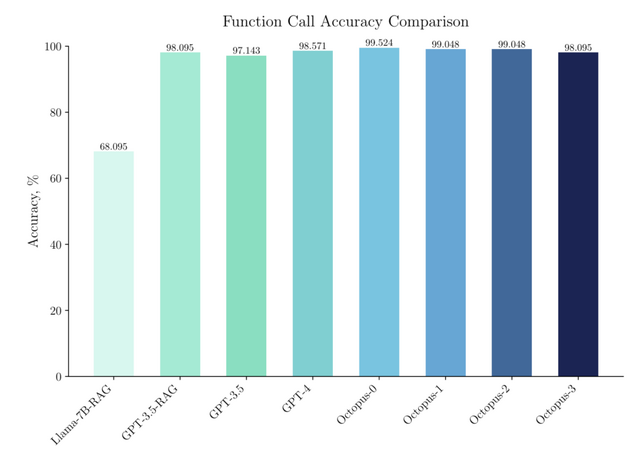
ベンチマークテストでは、Octopus v2は関数呼び出しタスクで99.524%の精度を達成し、GPT-4を上回りました。また、このモデルは応答時間も大幅に短縮し、レイテンシは1回の呼び出しあたり0.38秒に抑えられました。これはLlama-7BのRAGベースの手法と比較して35倍の改善です。さらに、処理に必要なコンテキストの長さが95%短縮され、デバイス上での操作の処理効率が実証されました。
Octopus v2: On-device language model for super agent
Wei Chen, Zhiyuan Li
Paper | Hugging Face