
1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第2回目は、マイクロソフトの巨大トークン化手法など5つの論文をまとめました。
生成AI論文ピックアップ
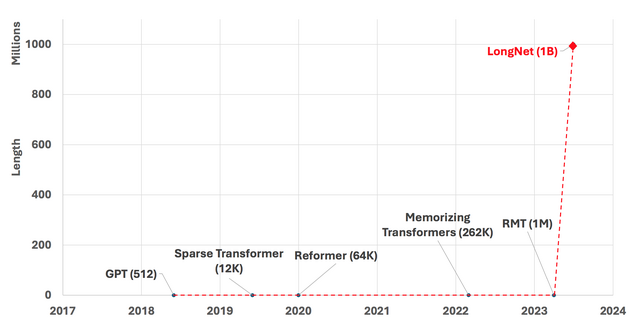
言語生成モデルを“10億トークン”に拡張できる手法「LongNet」 Microsoftが発表
コンテキスト(プロンプト)を単語や文字、句読点、数字、記号などのパーツに小分けしたものを指すトークンは、大規模言語モデル(LLM)においてコンテキストを理解する上で重要な役割を果たします。しかし、既存のLLMはChatGPT(GPT-4)でも約3万トークン程度であり、最新のモデルでも数百万トークン程度に制限されています。
なぜなら、これらのTransformerベースのモデルは、Attention機能により全てのトークン同士の関係を考慮し出力を生成するため、トークン数が増えると計算コストが高くなる弱点があるからです。
シーケンス内のすべてのトークンが他のすべてのトークンに注意を向け、各関係を考慮し、出力を生成するときに入力の特定の部分に焦点を当てるアルゴリズムを採用していることに起因します。そのためトークンの数が増加するにつれて、計算の複雑さが二次関数で増加します。
LongNetでは、この問題を解決するために「Dilated Attention」という新しいコンポーネントを導入しました。Dilated Attentionは、トークンをセグメント(サブセット)に分割し、指数関数的にまばらな領域に注意を集中させることで、全てのトークンが全てのトークンに注意を向ける必要性がなくなります。
このアプローチにより、LongNetは計算コストを大幅に抑えたまま10億トークンの大きなシーケンスを処理できる効率的なスケールアップを実現しました。実験では、短いシーケンスから長いシーケンスまで、高い精度を維持しながら処理できることが確認されました。
LongNet: Scaling Transformers to 1,000,000,000 Tokens
Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Furu Wei
Paper | GitHub
“ドラッグ&ドロップ”で画像内の物体を移動できるAI テンセント含む研究者ら「DragonDiffusion」開発
最近登場した「DragGAN」という技術は、洗練された画像編集を可能にする、点から点へのドラッグスキームを提案しています。「DragDiffusion」という類似の手法も登場しており、容量と汎化の制約に悩むGANモデルの問題を解決しています。
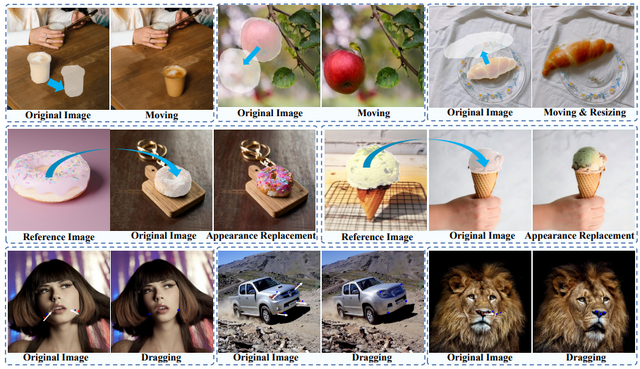
しかしながら、これらの手法はA点からB点への移動による特有の操作方法を用います。そこで、この研究では点の移動による編集ではなく、より直感的な方法である、画像間のコンテンツをドラッグすることで編集可能なシステム「DragonDiffusion」を提案しています。
具体的には、画像内のオブジェクトをクリックして任意の場所にドラッグ&ドロップすると、指定したオブジェクトが移動します。移動後の空いたスペースは周囲と調和するように埋められ、元々存在していなかったかのように処理されます。
DragonDiffusionでは、拡散過程で「誘導特徴量」と「生成特徴量」と呼ばれる2つの特徴量を使用しています。これらの中間特徴量の強い関連性により、編集結果と元画像の内容の一貫性を保ちながら編集が行えます。
DragDiffusionと異なり、モデルの微調整や学習を必要とせず、事前学習済みのStable Diffusionに基づいて構築されています。すべての編集とコンテンツの一貫性の情報は画像自体から得られ、さらに中間特徴の対応関係を利用することで、オブジェクトの移動、サイズ変更、外観の置き換え、コンテンツのドラッグなどの画像編集機能を実現できます。
DragonDiffusion: Enabling Drag-style Manipulation on Diffusion Models
Chong Mou, Xintao Wang, Jiechong Song, Ying Shan, Jian Zhang
Paper | GitHub
写真1枚から高解像度の3Dモデルを生成するAI「Magic123」 米Snap含む研究者らが開発
「Magic123」というImage-to-3Dフレームワークを提案したこの論文では、1枚の写真を入力として使用し、写真に含まれる被写体の3Dモデルを生成する手法を紹介しています。Magic123は、ポーズなしの画像から、詳細な3Dジオメトリと高いレンダリング解像度(1024×1024)を持つ忠実な3Dコンテンツを再構成することができます。
従来の3D再構成手法では、2Dプリオールまたは3Dプリオールのどちらかを使用する方法が取られてきました。それぞれには利点と欠点がありますが、本研究では、両者を分析して最適なアプローチを見つけることを試みました。2Dプリオールは、3Dプリオールでは達成できない汎化性能を持ちますが、3Dの詳細さと一貫性には制約があります。
一方、3Dプリオールにのみ依存することは、限られた3D学習データのため、一般的な物体には効果的ですが、一般的でない物体では困難であり、単純化された3D形状や平坦な形状を出力することがあります。
Magic123は、2Dと3Dの両方のプリオールを組み合わせた2段階のアプローチを使用して、高品質な3D出力を生成するパイプラインです。第一ステージでは、NeRFを使用して粗い形状とテクスチャを学習します。ただし、NeRFはメモリを大量に必要とするため、レンダリング画像の解像度が低下し、3D出力の品質が低下する可能性があります。第二ステージでは、高解像度のレンダリング画像でメモリ効率の良い微分可能なメッシュ表現を最適化することで、3Dコンテンツの品質を向上させます。

Magic123: One Image to High-Quality 3D Object Generation Using Both 2D and 3D Diffusion Priors
Guocheng Qian, Jinjie Mai, Abdullah Hamdi, Jian Ren, Aliaksandr Siarohin, Bing Li, Hsin-Ying Lee, Ivan Skorokhodov, Peter Wonka, Sergey Tulyakov, Bernard Ghanem
Project Page | Paper | GitHub
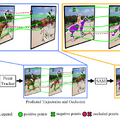
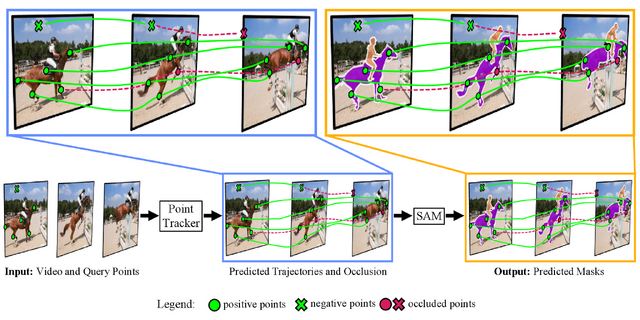
点で指定するだけ、動画内の動く物体を自動で追跡して識別するビデオセグメンテーションAIモデル
この研究は、動画中のあらゆる物体を追跡しセグメンテーションする手法「SAM-PT」を提案します。この手法は、Metaの静止画像セグメンテーションモデル「SAM」を動画セグメンテーションに拡張したアプローチです。
動画セグメンテーションは自律走行やロボット工学、ビデオ編集などで役立つ技術ですが、現在の手法はゼロショット設定や未知のデータに対する難点があります。一方で、SAMは画像セグメンテーションにおいてゼロショット能力を持っていますが、現時点では動画セグメンテーションタスクには適用できません。
これらの解決策としてSAM-PTは、点追跡と画像セグメンテーションを組み合わせて、動画内の物体を追跡しセグメンテーションします。ユーザーは動画の最初のフレームで、追跡したいオブジェクトにポジティブの点を加え、非追跡のオブジェクトにネガティブの点を加えるだけ。後は、別のフレームにそれらの点が伝播され、またオクルージョンを自動予測します。
これによりSAM-PTは、トレーニングデータを必要とせず、オクルージョンが発生しても高性能な動画セグメンテーションを実現します。実験結果では、SAM-PTがさまざまなベンチマークで優れた性能を示しました。
Segment Anything Meets Point Tracking
Frano Rajič, Lei Ke, Yu-Wing Tai, Chi-Keung Tang, Martin Danelljan, Fisher Yu
Project Page | Paper | GitHub
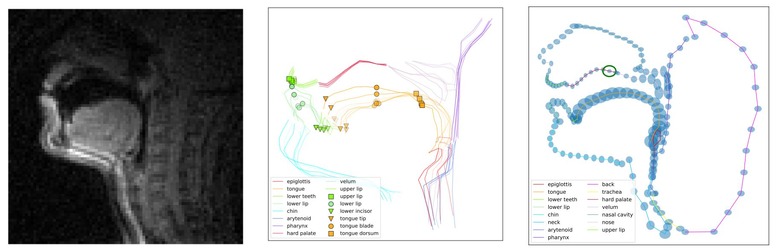
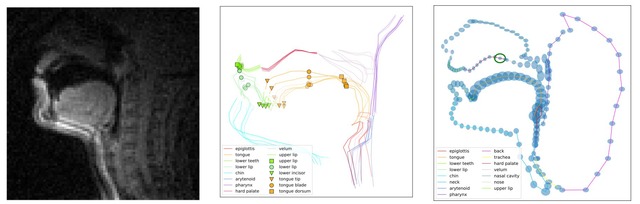
喉のMRI画像から音声合成を生成するAI
本研究では、口腔から喉にかけての領域の画像を磁気共鳴画像法(MRI)で撮影し、その画像から音声合成を生成するシステムを提案します。MRIに基づく新しい調音合成手法を考案し、このようなデータを処理するための前処理とモデリング戦略を提供します。
この研究では、声道情報を使用した調音合成に焦点を当てています。最近の進歩により、電磁気的調音学(EMA)を使用した口の位置測定に基づく明瞭な調音合成が可能になりました。しかし、これらの手法では鼻音などの重要な調音情報が欠けており、一般化能力が制限されています。
この課題に取り組むために、我々はEMAよりも広範な調音空間をカバーするMRIベースの代替特徴セットを提案します。さらに、MRIデータを使用して学習したGANベースの手法を改良し、正規化とノイズ除去の手順を導入することで、MRI音声合成モデルの計算効率と音声の忠実度の両方を向上させます。
実験の結果、提案するモデルがいくつかの評価指標でベースラインを上回ることが実証されました。また、MRIの利点に比べてEMAに対するMRIの特徴や調音合成においてMRIがどれほど重要かを定量的・定性的に明らかにしました。
Deep Speech Synthesis from MRI-Based Articulatory Representations
Peter Wu, Tingle Li, Yijing Lu, Yubin Zhang, Jiachen Lian, Alan W Black, Louis Goldstein, Shinji Watanabe, Gopala K. Anumanchipalli
Paper | GitHub