
この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する今回の「生成AIウィークリー」(第150回)は、AIエージェントが動作する環境をシミュレートする言語モデル「Qwen-AgentWorld」、Claude Mythos/Fableで学習したと謳うローカル無検閲AI「Qwythos-9B」GGUF版を取り上げます。
また、Meta開発のデータサイエンティストAI「Autodata」や、120億パラメータの画像生成AIモデル「Krea 2」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、Baiduの研究チームが開発した、数十ページのPDFなど長文を一括処理できるエンドツーエンドのOCRモデル「Unlimited OCR」を別の単体記事で取り上げています。
Claude Mythos/Fableで学習したと謳うローカル無検閲AI「Qwythos-9B」GGUF版が登場
無検閲で思考プロセスを持つ推論AIモデル「Qwythos-9B-Claude-Mythos-5-1M」の扱いやすいGGUF版が公開されました。
AlibabaのQwen3.5-9Bをベースに、Claude Mythos/Claude Fableのトレースを元にした5億トークン超のデータで事後学習したとされています。
最終的な回答を出力する前にAI内部で思考するステップを挟む点が特徴。最大100万トークンの長文読み込みや、外部ツールを操作する関数呼び出しに対応しています。
安全フィルターによる回答拒否がない無検閲(アンセンサード)仕様となっています。容量は4bit版から16bit版までがApache 2.0ライセンスで提供されています。

Qwythos-9B-Claude-Mythos-5-1M-GGUF
Empero AI
Hugging Face
AIエージェントが動作する環境をシミュレートする言語モデル「Qwen-AgentWorld」
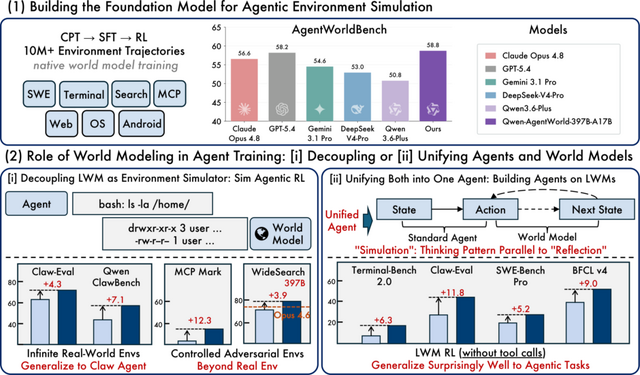
Qwenチームは、AIエージェントが動作する環境をシミュレートする言語モデル「Qwen-AgentWorld」を発表しました。
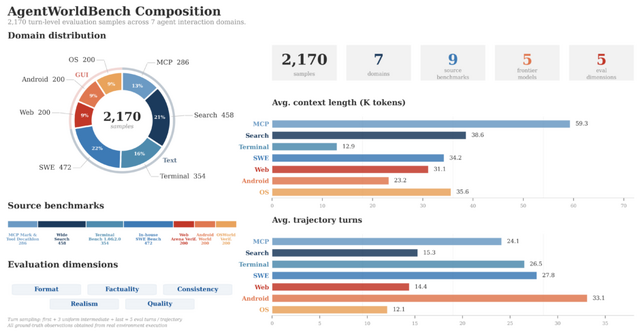
シミュレーション内容としては、テキストで操作する環境として、MCP、検索、ターミナル、SWEの4つ。画面を見て操作するGUI環境として、Web、OS、Androidの3つを搭載しています。
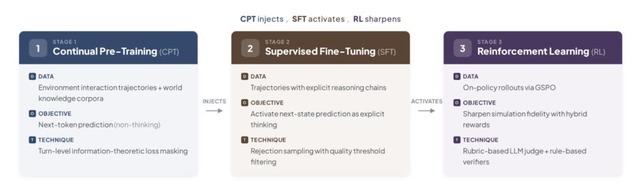
実際の環境でのやり取りを記録した1000万件以上のデータを使用し、最初から環境の予測を目的として訓練されています。
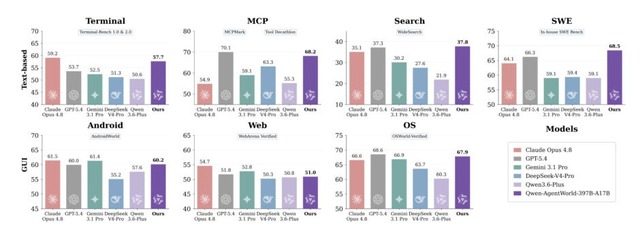
同時に公開された評価用ベンチマーク「AgentWorldBench」によるテストでは、最上位モデル(397B-A17B版)がGPT-5.4やClaude Opus 4.8、Gemini 3.1 Proといった他社の主要モデルを上回るシミュレーション精度を達成しました。

Qwen-AgentWorld: Language World Models for General Agents
Yuxin Zuo, Zikai Xiao, Li Sheng, Fei Huang, Jianhong Tu, Yuxuan Liu, Tianyi Tang, Xiaomeng Hu, Yang Su, Qingfeng Lan, Yantao Liu, Qin Zhu, Yinger Zhang, Bowen Yu, Haiquan Zhao, Haiyang Xu, Jianxin Yang, Jiayang Cheng, Junyang Wang, Lianghao Deng, Mingfeng Xue, Tianyi Bai, Yang Fan, Yubo Ma, Yucheng Li, Zeyu Cui, Zhihai Wang, Zhihui Xie, Zhuorui Ye, An Yang, Dayiheng Liu, Jingren Zhou, Ning Ding
Paper | GitHub | Blog
MetaがデータサイエンティストAI「Autodata」を発表。AIが自分の訓練データを作る
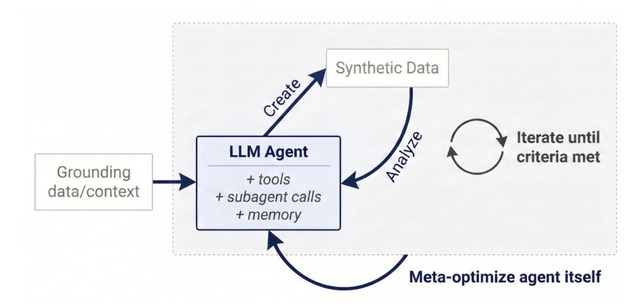
MetaのAI研究部門FAIRは、AI自身がデータサイエンティストとして振る舞い、データの生成、品質評価、分析、合成データ生成の改善を反復的に行うAIエージェント「Autodata」を発表しました。AIの訓練データや評価データを効率的に作るためのエージェントです。
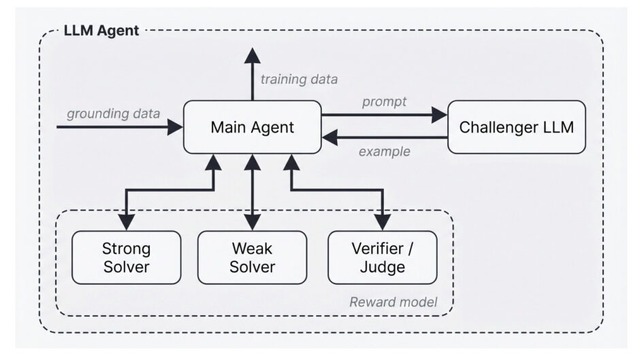
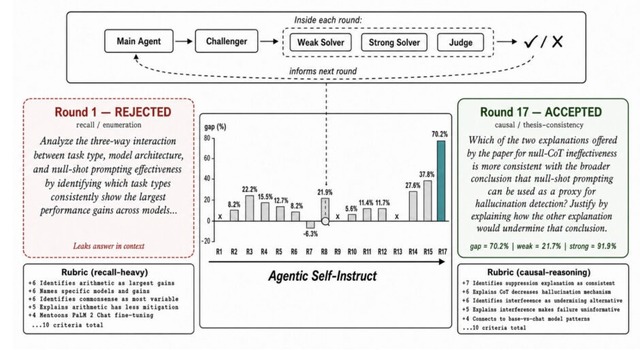
実装は「Agentic Self-Instruct」と呼ばれ、問題を作るデータの作成者、問題を解く能力の低い弱いモデル、問題を解く能力の高い強いモデル、結果を判定する裁判官の4つのサブエージェントが連携します。
作成された問題を2つのモデルに解かせ、弱いモデルには難しく、強いモデルなら正解できるという学習に最適な難易度になるまで、裁判官のフィードバックをもとにデータの修正と洗練を繰り返します。
研究チームは、コンピュータサイエンスの論文理解、法務推論、科学的推論(数学や物理)のタスクでこの手法を検証しました。その結果、従来の単純なプロンプト指示によるデータ生成手法(CoT Self-Instructなど)と比較して、Autodataが作成したデータを用いて強化学習(RL)を行ったモデルは、高い性能を示しました。
さらに、単にエージェントにデータを作らせるだけでなく、より良いデータを作れるように、データサイエンティストAI自身を改善させるメタ最適化を行なっており、生成されるデータの品質がさらに向上することも確認されています。
Autodata: An agentic data scientist to create high quality synthetic data
Ilia Kulikov, Chenxi Whitehouse, Tianhao Wu, Yixin Nie, Swarnadeep Saha, Eryk Helenowski, Weizhe Yuan, Olga Golovneva, Jack Lanchantin, Yoram Bachrach, Jakob Foerster, Xian Li, Han Fang, Sainbayar Sukhbaatar, Jason Weston
Paper
120億パラメータの画像生成AIモデル「Krea 2」がオープンウェイト登場。商用利用も可能
AI企業のKrea.aiは、120億パラメータの画像生成AIモデル「Krea 2」シリーズをHugging Faceにてオープンウェイトで公開しました。
このモデルは、Diffusion Transformer(拡散トランスフォーマー)を採用しており、自然言語の説明文から画像を作り出すことができます。
追加の事後学習を行う前の基盤モデルである「Krea 2 Raw」と、ファインチューニングと蒸留を施した「Krea 2 Turbo」の2種類が提供されています。
本モデルは公開データ、ライセンスデータ、独自の合成データを組み合わせて学習されており、有害なコンテンツを排除するためのフィルタリングと安全性評価が実施されています。
ライセンスは、年間売上高が100万米ドル未満であれば、ロイヤリティ無料で商用利用が認められています。


Krea-2
Krea.ai
Hugging Face